
 O título da Tabela deve conter: 1- o Quê, 2- Quem, 3- Onde e 4- Quando. p'ra poder fazer o Teste de Hipótese H0: H1 é falsa x H1: Stat X > Xc, α = 0,05 e achar o P que é a soma de tudo que pode dar errado e a Tabela mãe é o Legado... p'ra Posteridade. | aplicando o Teste estatístico adequado
concluímos que (H1: X̅A > X̅B; α=0,05) a média do grupo A é maior que Stat Z > 1,645 é o valor mínimo (crítico) p'ra rejeitar H0 unilateral à direita com (α = 0,05).
média do grupo B ao
nível de significância
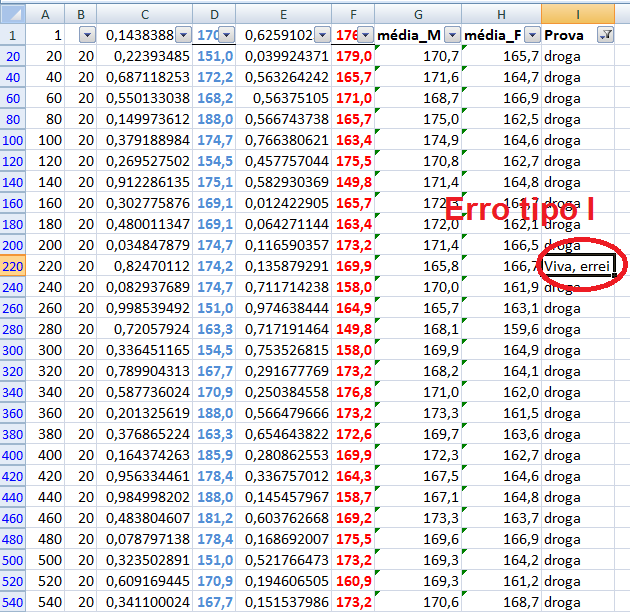
Stat Z > 1,96 é o valor mínimo (crítico) p'ra rejeitar H0 bilateral com (α = 0,05). Lembre-se: o cálculo do valor de z ou t (Stat z ou t) não depende de H0. Calcule Stat t na unha. entre [-3:3] ≅ 99% (praticamente todo mundo). IC[95%] = X̅ ± 1,96*epm = X̅ ± margem de erro. Área de -oo:0] = 50%; de -oo:1] ≅ 84%, de -oo:1,645] ≅ 95% i.é, α = 0,05(*). Se Stat Z=1,8>1,645 rejeito H0 unilateral para α=0,05 mas não para α=0,01(**), Zc=2,326. Densidade da frequência (φ=0,242) = Frequência da classe (0,95) / Largura da classe (2*1,96) Se n=4, X~t(3;0;1), α=0,05, então, o IC(95%)=X±tc-bi(α/2;gl)*S/√n = 0 ± 3,18 * 1/√4 = [-1,59:1,59]. Observe que se α = 0,05 e o teste é à direita, então o tc estará entre 6,314 e 1,645 (gl de 1 a infinito). Sim, o teste acredita que a amostra representa a população. Problema? ...Em estudos não-randomizados e não-pareados, o pesquisador aprende e introduz o viés (bias) de medida e, por isso, o desvio padrão diminui e assim aumenta a probabilidade de um P legal!. Quanto maior o 'n' (tamanho da amostra) maior a certeza e menor o Erro tipo I e tipo II. |
 |
|
O Protocolo de pesquisa é o conjunto de documentos encaminhados ao Comitê de Ética em Pesquisa (CEP) para apreciação. No Protocolo se descreve a pesquisa em seus aspectos fundamentais, informações relativas ao sujeito da pesquisa, à qualificação dos pesquisadores e todas as instâncias responsáveis.
O Projeto de pesquisa é uma parte do Protocolo e contempla o planejamento de todas as etapas da pesquisa que se pretende realizar. (Conselho Nacional de Saúde - Resolução 466/12). 02- Folha de rosto... 03- Projeto de pesquisa contendo: A) Resumo; B) Justificativa; C) Introdução; D) Objetivos; E) Descrição detalhada da metodologia proposta; F) Casuística (amostragem), especificando os Critérios de Inclusão e Exclusão dos sujeitos da pesquisa na amostra, bem como os Planos de Recrutamento; G) Número de sujeitos da pesquisa; H) Análise crítica dos riscos e benefícios; I) Bibliografia; J) Cronograma de execução do projeto; K) Responsabilidades do pesquisador, da Instituição e do patrocinador (se houver); L) Critérios para suspender ou encerrar a pesquisa; M) Local de realização das várias etapas e infra-estrutura necessária; N) Justificativa do uso de grupos vulneráveis; O) Declaração sobre o uso e destinação do material e/ou dados coletados; P) Declaração de que os resultados serão tornados públicos, sejam favoráveis ou não. ...04- Orçamento financeiro detalhado, fonte do financiamento e remuneração do pesquisador (se houver). 05- Termo de consentimento livre e esclarecido (TCLE). 06- Definições das atribuições da equipe do projeto, titulação e a formação acadêmica e a anuência prévia de todos os participantes com as devidas assinaturas da equipe. 07- Curriculum vitae. 08- Declaração das instituições parceiras. 09- Para pesquisas com armazenamento de material biológico também adequar às resoluções 340/2004 e 347/2005. 10- Cópia dos documentos em cd-rom. 11- Informações referentes aos procedimentos de biossegurança envolvendo a equipe do projeto e os sujeitos da pesquisa quando for o caso. 02- Classificar os tipos de projetos de pesquisa.
1) Ciências exatas: 1.1) Bioestatística é o ramo da Estatística aplicada às Ciências Biológicas (conjunto de ferrramentas para coleta, organização, análise e interpretação de resultados experimentais). 2) Ciências biológicas: 2.1) Epidemiologia: estuda a distribuição populacional quantitativa dos estados de saúde/doença e os fatores de risco. Aplicações: 1- Diagnósticos de saúde comunitária, 2- Monitoramento das condições de saúde, 3- dentificação dos determinantes de doenças, 4- Validação de métodos diagnósticos, 5- Estudo da história natural das doenças e seu prognóstico, 6- Avaliação de intervenções médico-sanitárias, 7- Avaliações terapêuticas 2.2) Farmacologia: estuda a relação fármaco-organismo. 2.3) Fisiologia: estuda os mecanismos de manutenção da Homeostase. 3) Ciências humanas: Arusha, Tanzânia, 02/dez/2016. II) quanto aos objetivos: 1- teórico, 2- metodológico, 3- observacional, 4- experimental ou intervencional, 5- confirmatório. 1- Estudo teórico: 1- definição de leis, 2- sistemas estruturados e 3- modelos teóricos. 2- Estudo metodológico: 1- desenvolvimento de metodologia científica, 2- comparação (confiabilidade) entre métodos.
2.1) Estudos sobre a reprodutibilidade de testes.
2.2) Estudos sobre a acurácia de testes: 1- Sensibilidade, 2- Especificidade, 3- Valor preditivo, 4- Curvas ROC. 2.3) Estudos sobre o efeito dos resultados do teste nas decisões clínicas. 2.4) Estudos sobre factibilidade, custos e riscos de testes. 2.5) Estudo sobre efeito do teste nos desfechos. 3- Estudo experimental: 1- fisiológico, 2- farmacológico, 3- físico, 4- químico... #intervenção em humanos
3.1) Estudo experimental farmacocinético... Efeito do organismo sobre a droga.
Bioquivalência 3.2) Estudo experimental farmacodinâmico... Efeito da droga sobre o organismo. H1: O coeficiente de Hill (do doido) da Curva Dose-Resposta é estatísticamente igual a 1. H0: H1 é falsa. Os objetivos secundários são: 1- confirmação da eficácia, 2- investigação da forma e da localização da curva de dose resposta, 3- estimativa de uma dose inicial mais apropriada, 4- identificação das melhores estratégias para o ajuste de doses e para a determinação de um limite máximo de dose além do qual não haverá benefícios terapêuticos adicionais. Medidas: pD2, EC50, Coeficiente de Hill, Coeficiente angular S, Resposta máxima, Intervalo de confiança (IC95%) do coeficiente de Hill. 4- Estudo de caso retrospectivo: 1- observacional...
No Estudo de caso os fatos são observados, registrados, analisados, classificados e interpretados sem a interferência do pesquisador (que só faz mensurações (medidas ou contagens). Não há grupos controle nem comparação entre grupos. O objetivo é responder a 5 questões: 1- Quem tem a doença ou o evento (Who)? 2- Qual a doença ou o evento (What) 3- Em que condições ocorreu (Why)? 4- Qual a frequência (When)? 5- Onde ocorreu (Where)?.
1- Estudo (relato) de caso - São estudos etiológicos ou etiopatogênicos que descrevem a clínica de um indivíduo. Vêm antes das descrições de casuísticas (amostragem) e não fornece explicação definitiva. Ex: Relato de manifestações clínicas de uma doença X (rara). 5- Estudo epidemiológico observacional: 1- descritivo (de prevalência), 2- analítico (de incidência)...
5.1) Estudo epidemiológico observacional descritivo:
O Estudo exploratório, piloto ou preliminar é o primeiro estágio de toda pesquisa científica e é usado quando quase nada é conhecido a respeito do assunto (pouca ou nenhuma referência bibliográfica). O objetivo é dar uma visão geral de um determinado fato, sua definição e classificação.
Tamanho da amostra com desvio-padrão desconhecido: Com base na primeira coleção de pelo menos 31 valores amostrais selecionados aleatoriamente e usar o desvio-padrão da amostra S.
No Estudo de caso os fatos são observados, registrados, analisados, classificados e interpretados sem a interferência do pesquisador (que só faz medidas). Não há grupos controle nem comparação entre grupos. O objetivo é responder a 5 questões: 1- Quem tem a doença ou o evento (Who)? 2- Qual a doença ou o evento (What) 3- Em que condições ocorreu (Why)? 4- Qual a frequência (When)? 5- Onde ocorreu (Where)?.
1- Estudo (relato) de caso - São estudos etiológicos ou etiopatogênicos que descrevem a clínica de um indivíduo. Vêm antes das descrições de casuísticas (amostragem) e não fornece explicação definitiva. Ex: Relato de manifestações clínicas de uma doença X (rara). 2- Série de casos - É um conjunto de estudo de casos que analisa a distribuição da doença na população caractrerizada por sexo, idade, localização geográfica, sintomatologia, exames laboratoriais, etc. Ex: O relato de uma série de casos de indivíduos homossexuais com Sarcoma de Kaposi alertou sobre a AIDS.
1- Levantamento (Survey) é o tipo de pesquisa que visa determinar informações sobre práticas ou opiniões atuais de uma população específica. Ex: #pessoas no casa, renda familiar, altura, peso, idade.
2- Levantamento Normativo (Survey Normativo) é o tipo de pesquisa descritiva que procura estabelecer normas, para amostras de idade e gênero diferentes, com relação as habilidades, desempenhos, convicções ou atitudes. Em Estudo de prevalência, transversal, estudo seccional, de inquérito ou cross-seccional a principal medida transversal é a da proporção de indivíduos que apresentam um determinado transtorno no momento da avaliação ou em período de tempo estabelecido chamada Prevalência. Prevalência ou Taxa de prevalência é uma medida transversal definida por: Prevalência = Nro de pessoas com o evento de interesse / População sob risco de apresentar o evento num determinado período de tempo, ou seja, a medida da frequência de quantas pessoas estiveram doentes em um determinado lugar numa dada época. Todas as medições são feitas nem um curto período de tempo (como uma foto), não há seguimento dos participantes. Causa e efeito são detectados simultaneamente, portanto não se pode falar em Fatores de risco e sim, de Fatores associados. Classificação: (1- no ponto e 2- no período) 1- Prevalência no ponto ou ponto-prevalência - É a prevalência no momento da avaliação. 2- Prevalência no período - É a prevalência no período de tempo estabelecido (prevalência em um mês, no ano, na vida, etc). Estatística: 1- Medidas de OCORRÊNCIA, 2- Medidas de RISCO???. 1- Medidas de OCORRÊNCIA (OU FREQUÊNCIA) TRANSVERSAL: 1- Taxa de Prevalência = Número de casos existentes / Número de pessoas estudadas na população (n), com IC(95%) = Prevalência ± 1,96*RAIZ((Prevalência*(100-Prevalência))/n). Ex: A Taxa de Prevalência de dengue no Ceará em 1994 foi de 3% com IC(95%) = 1%. É usada em doenças crônicas, no planejamento e administração de serviços. 2- A Razão de Prevalência (RP, Razão de Taxa de Prevalências ou densidade de Prevalênicia) mede quantas vezes a Taxa de prevalência entre os expostos é maior (ou menor) do que entre os não expostos. "...Esses fatores foram avaliados por meio de modelo hierárquico utilizando regressão de Poisson para o cálculo de razões de prevalências após ajuste para fatores de confusão." 2- Medidas de RISCO (ou de EFEITO, de ASSOCIAÇÃO) são: 2.1- A Razão de Chances, Odds ratio, Razão de Produtos cruzados ou Razão de odds. Indicam a magnitude do efeito de um Fator de Risco sobre a ocorrência do desfecho. Esta medida corresponde ao Risco Relativo nos Estudos longitudinais.
5.2) Estudo epidemiológico observacional analítico:
Estudo de correlação, ecológico ou correlacional - A unidade de observação é um conjunto de indivíduos (bloco populacional). Procura-se encontrar possíveis correlações em indicadores globais. Não é possível conhecer os dados individuais já que as informações são obtidas de registros de dados coletados de fonte de dados oficiais (OMS, registros nacionais...), são estudos rápidos e de baixo custo, já que dispensam amostragens, entrevistas, fichas ou exames clínicos. Descreve as diferenças entre populações num determinado intervalo de tempo ou num mesmo tempo. A associação entre exposição e doença esta associação é medida como no risco relativo, que é estimado pelo cálculo do odds ratio (OR), também denominado razão dos produtos cruzados. A razão de prevalência é a relação entre a prevalência entre expostos e entre não-expostos. O Fator determinante é o tempo e forma de comparação entre as amostras. A oganização das variáveis pode ser feita através de uma tabela 2x2. Não determina risco absoluto (incidência).
Fontes de dados sobre doença: 1- Registros de mortalidade, 2- Registros de morbidade, 3- Dados censitários sobre morbi-mortalidade e população. Fontes de dados sobre exposição e fatores de confusão: 1- Censos econômicos, 2- Censos demográficos, 3- Dados de produção e/ou consumo. Estatística: Medidas de ocorrência e de efeito a análise dos estudos ecológicos é relativamente simples, mas a interpretação dos resultados pode ser difícil. A medida de associação é a CORRELAÇÃO e, por isso, eles são também conhecidos como Estudos de correlação.
Vigilância epidemiológica é o conjunto de atividades que permite reunir as informações necessárias para : 1- conhecer a qualquer momento,= o comportamento ou história natural das doenças e 2- detectar ou prever alterações de seus fatores condicionantes, com o objetivo de recomendar as medidas indicadas e eficientes que levem à prevenção e ao controle de determinadas doenças.
5.2.3) Estudo de Caso-Controle ou Case-base study (Efeito ⇒ Causa - retrospectivo). Odds e Odds Ratio...
O Estudo de Caso-Controle (Case-control study, Estudo ex-post facto "a partir de fatos passados") é semelhante ao Estudo de Caso, só que é possível compará-lo ao grupo controle. Assim como nos Coorte Caso-Controle, no Estudo Caso-Controle os participantes não são randomizados (ver técnicas de MASCARAMENTO) para os respectivas amostras porque já pertencem a eles antes do início da pesquisa (avisar ao Analista estatístico sobre este critério de entrada). O Objetivo é estudar a etiologia ou a etiopatogenia das doenças. É um tipo de estudo que se inicia com a identificação de pacientes com uma determinada doença ou situação, os quais são avaliados quase sempre retrospectivamente (pode ser propectivo, neste caso é Coorte Caso-Controle) para verificar se receberam algum tratamento ou se foram expostos a algum fator de risco. É muito sensível a viés e é eficiente para estudar doenças raras, crônicas e fatores de risco. Ex: Casos: indivíduos refratários a tratamento de uma doença para a qual já existe terapêutica eficaz. Controles: indivíduos com resultados satisfatórios ao tratamento.
Classificação: 1- Pareado (emparealhado, dependente) - a medida de efeito é a Razão de pares discordantes. 2- Não-pareado (independente). Estatística: 1- Medida de Ocorrência é a Prevalência de exposição, 2- Medida de Risco (ou de efeito) é a Razão de Chances (Odds ratio, Razão de Produtos cruzados ou Razão de odds). Não se pode estimar Riscos Relativos em estudos transversais.
O Estudo de Coorte (Cohort study, estudo de acompanhamento, de incidência, longitudinal, de seguimento, follow-up): Além de estudar a etiologia e a etiopatogenia é o Padrão ouro para avaliação do prognóstico. Pode-se acompanhar toda uma amostra população (1 coorte) ou dois grupos (2 coortes), dos quais apenas um é exposto a uma intervenção, uma condição ambiental ou um fator de risco (coorte caso), enquanto que o outro grupo não é submetido a estes eventos (coorte controle). Há ainda o modelo de Estudo de coorte com duração de seguimento variável. Ex: Estudar os efeitos da droga X na redução da probabilidade de uma determinada doença.
O maior estudo estatístico observacional é o CENSO (recenseamento demográfico) realizado a cada 10 anos que juntamente com dados do DATASUS geram vários Indicadores de saúde...
População total (x 1.000)
Taxa de crescimento anual da população (%) População em áreas urbanas (%) População vivendo abaixo da linha de pobreza (% < US$1 por dia) Idade mediana da população (anos) Proporção da população com mais de 60 anos (%) Proporção da população abaixo de 15 anos (%)
Taxa de alfabetização (%)
Produto interno bruto per capita bruto per capita (PPP international $) Razão líquida de matrícula no ensino primário no sexo feminino (%) Razão líquida de matrícula no ensino primário no sexo masculino (%) Cobertura de registro de nascimentos (%) Cobertura de registro de óbitos (%) Taxa de fertilidade total (por mulher)
Cobertura de pré-natal - ao menos 4 visitas (%)
Partos realizados por profissionais de saúde qualificados (%) Neonatos protegidos ao nascer contra o tétano neonatal (PAB) (%) Crianças com 1 ano imunizadas com MCV Crianças com 1 ano imunizadas com 3 doses de DTP3 (%) Crianças com 1 ano imunizadas com 3 doses de HepB3 (%) Crianças com 1 ano imunizadas com 3 doses de Hib3 (%) Cobertura de terapia antiretroviral entre os com infecção avançada pelo HIV (%) Detecção de tuberculose segundo o DOTS (%) Sucesso no tratamento de tuberculose segundo o DOTS (%) Mulheres que realizaram mamografia (%) Mulheres que realizaram Papanicolau (%) Prevalência de contraceptivo (%)
Gasto per capita total com saúde (dólar int. $)
Gasto per capita total com saúde pela taxa de câmbio média (US$) Gasto per capita com saúde pelo governo (dólar int. $) Gasto per capita com saúde pelo governo pela taxa de câmbio média (US$) Proporção de gastos do governo em saúde no gasto total com saúde Proporção de gasto privado em saúde do total de gastos em saúde Proporção de recursos do exterior no gasto total com saúde Proporção de gastos do governo em saúde no gasto total do governo Proporção de gasto do próprio bolso no gasto privado em saúde Proporção de planos prépagos do total de gastos privados em saúde Densidade de profissionais da odontologia (p/ 10.000 hab.) Densidade de profissionais de enfermagem (p/ 10.000 hab.) Densidade de profissionais médicos (p/ 10.000 hab.) Leitos hospitalares (p/ 10.000 hab.)
Proporção de partos realizados por profissionais de saúde qualificados no maior nível educacional da mãe
Proporção de partos realizados por profissionais de saúde qualificados no menor nível educacional da mãe Proporção de partos realizados por profissionais de saúde qualificados no quintil de riqueza mais elevado Proporção de partos realizados por profissionais de saúde qualificados no quintil de riqueza menos elevado Proporção de partos realizados por profissionais de saúde qualificados em área rural Proporção de partos realizados por profissionais de saúde qualificados em área urbana Cobertura de vacinação contra sarampo em crianças de 1 ano no maior nível educacional da mãe Cobertura de vacinação contra sarampo em crianças de 1 ano no menor nível educacional da mãe Cobertura de vacinação contra sarampo em crianças de 1 ano no quintil de riqueza mais elevado Cobertura de vacinação contra sarampo em crianças de 1 ano no quintil de riqueza mais elevado
Mortalidade em menores de 5 anos (p/ 1.000 nascidos vivos) na área rutal
Mortalidade em menores de 5 anos (p/ 1.000 nascidos vivos) na área urbana Mortalidade em menores de 5 anos (p/ 1.000 nascidos vivos) no maior nível educacional da mãe Mortalidade em menores de 5 anos (p/ 1.000 nascidos vivos) no menor nível educacional da mãe Mortalidade em menores de 5 anos (p/ 1.000 nascidos vivos) no quintil de riqueza mais alto Mortalidade em menores de 5 anos (p/ 1.000 nascidos vivos) no quintil de riqueza mais baixo Mortalidade entre 15 a 60 anos (p/ 1.000 hab.) Mortalidade entre mulheres de 15 a 60 anos (p/ 1.000 hab.) Mortalidade entre homens de 15 a 60 anos (p/ 1.000 hab.) Mortalidade por câncer padronizada por idade (p/100.000 hab.) Mortalidade por doença cardiovascular padronizada por idade (p/100.000 hab.) Mortalidade por lesões padronizada por idade (p/ 100.000 hab.) Mortalidade por doenças nãotransmissíveis padronizada por idade (p/ 100.000 hab.) Proporção de mortes em crianças < 5 anos por diarréia Proporção de mortes em crianças < 5 anos por HIV/AIDS Proporção de mortes em crianças < 5 anos por lesões Proporção de mortes em crianças < 5 anos por malária Proporção de mortes em crianças < 5 anos por sarampo Proporção de mortes em crianças < 5 anos por causas neonatais Proporção de mortes em crianças < 5 anos por outras causas Proporção de mortes em crianças < 5 anos por prneumonia Mortalidade materna (p/ 100.000 nascidos vivos) Mortalidade infantil (p/ 1.000 nascidos vivos) Mortalidade infantil (p/ 1.000 nascidos vivos) no sexo feminino Mortalidade infantil (p/ 1.000 nascidos vivos) no sexo masculino Mortalidade neonatal (p/ 1.000 nascidos vivos) Mortalidade em < 5 anos (p/ 1.000 nascidos vivos) Mortalidade em < 5 anos (p/ 1.000 nascidos vivos) no sexo feminino Mortalidade em < 5 anos (p/ 1.000 nascidos vivos) no sexo masculino
Incidência de tuberculose (p/ 100.000 hab. p/ ano)
Prevalência de HIV entre >=15 anos (p/ 100.000 hab.) Prevalência de tuberculose (p/ 100.000 hab.) Mortes por HIV/AIDS (p/ 100.000 hab. p/ ano) Mortes por tuberculose em pessoas HIVnegativas (p/ 100.000 hab.) Mortes por tuberculose em pessoas HIVpositivas (p/ 100.000 hab.) Expectativa de vida ao nascimento (anos) Expectativa de vida ao nascimento (anos) no sexo feminino Expectativa de vida ao nascimento (anos) no sexo masculino Expectativa de vida saudável (HALE) ao nascimento (anos) Expectativa de vida saudável (HALE) ao nascimento em mulheres (anos) Expectativa de vida saudável (HALE) ao nascimento em homens (anos) Proporção de anos de vida perdidos por doenças transmissíveis Proporção de anos de vida perdidos por lesões Proporção de anos de vida perdidos por doenças nãotransmissíveis Proporção de crianças < 5 anos acima do peso para a idade Proporção de crianças < 5 anos com baixa estatura para a idade Proporção de crianças < 5 anos abaixo do peso para a idade Recém-nascidos com baixo peso ao nascer Prevalência de mulheres (>=15 anos) obesas (%) Prevalência de homens (>=15 anos) obesos (%)
% da pop. rural usando combustíveis sólidos
% da pop. urbana usando combustíveis sólidos % da pop. total com acesso sustentável à fontes melhoradas de água potável % da pop. rural com acesso sustentável à fontes melhoradas de água potável % da pop. urbana com acesso sustentável à fontes melhoradas de água potável % da pop. total com acesso sustentável à saneamento melhorado % da pop. rural com acesso sustentável à saneamento melhorado % da pop. urbana com acesso sustentável à saneamento melhorado Prevalência de tabagismo atual entre adolescentes (13-15 anos) (%) Prevalência de tabagismo atual entre adolescentes (13-15 anos) do sexo feminino (%) Prevalência de tabagismo atual entre adolescentes (13-15 anos) do sexo masculino (%) Prevalência de tabagismo atual entre adultos (>=15 anos) (%) Prevalência de tabagismo atual entre mulheres adultas (>=15 anos) (%) Prevalência de tabagismo atual entre homens adultos (>=15 anos) (%) Consumo per capita de álcool registrado (litros de puro álcool) entre >=15 anos Estatística: 1- Medidas de OCORRÊNCIA. 2- Medidas de ASSOCIAÇÃO. 1- As medidas de OCORRÊNCIA (ou de FREQUÊNCIA) avaliam a força da morbidade ou da mortalidade, normalmente é expressa (corrigida) para 100.000 habitantes. INCIDÊNCIA é apenas o número de novos casos de uma doença (sem levar em conta o tamanho da população), mas, na prática, quando falamos em incidência estamos falando de Taxa de INCIDÊNCIA = Número de casos novos no período/(Número de pessoas em risco x Tempo de risco). É usada em doenças agudas, pesquisas etiológicas, estudos de prognóstico, verificação de eficácia de ações terapêuticas e preventivas. 2- As medidas de ASSOCIAÇÃO (ou EFEITO), avaliam a magnitude do efeito de um fator de risco sobre a ocorrência do desfecho (lembrar que risco é proporção e chance é razão) Risco (R) = Probabilidade de incidência = Incidência cumulativa = Número de casos novos no período/(Número de pessoas em risco: 2.1- O Risco relativo (RR) indica quantas vezes maior é o risco de adoecer entre os expostos comparados aos não expostos, não pode ser usado no Estudo Caso-Controle já que é uma medida de Incidência. RR = Razão entre duas taxas de incidência (menor que 1 é fator de proteção) e pode ser expressa em porcentage (RR - 1) * 100%, esta medida corresponde ao Odds ratios nos Estudos transversais. 2.2- Risco atribuível (RA) é a parcela da incidência da doença decorrente da exposição a um determinado fator de risco. RA = Incidência nos expostos - Incidência nos não expostos. 2.3- Risco Atribuível na População (Levin's Population Attributable Risk ou RAP) significa a redução a nível populacional da ocorrência de uma doença se fosse possível eliminar totalmente a exposição. RAP = (Prevalência do fator de risco * (Risco relativo 1)) / (Prevalência do fator de risco * (Risco relativo 1)) + 1)
Os Estudos observacionais longitudinal Estudo Caso-Controle têm o objetivo de esclarecer hipóteses sobre eventuais relações temporais do tipo causa e efeito. as amostras controle servem para comparação dos resultados.
5.2.6) Processo estocástico e Série temporal... 1- intervalo (contínuo e discreto), 2- previsão (simples e múltiplos).
Processo estocástico se refere a população e Série temporal ou histórica à amostra. Uma série histórica é uma sequência de observações obtidas em intervalos regulares de tempo, ou seja, é uma variável aleatória em função do tempo. Este conjunto pode ser obtido através de amostras periódicas do evento ou cumulativamente. A trajetória de um processo é a curva obtida no gráfico da série histórica. O conjunto de todas as trajetórias possíveis é chamado de processo estocástico e a série temporal é uma amostra deste processo. Ex: ECG (Eletrocardiografia dinâmica ou Holter), EEG, EMG. Aparentemente, o melhor método de análise é usando as Redes Neurais.
6- Estudo de caso prospectivo: 1- observacional, 2- intervencional...
Informática Médica.
7- Estudo epidemiológico intervencional: 1- ensaio clínico, 2- ensaio comunitário, 3- o famoso RCT...
Ensaio clínico (Terapêuticos) ou coorte intervencional: Características: Avalia de forma sistemática as novas estratégias terapêuticas.
Após os estudos experimentais FARMACOLÓGICOS inicia-se a Fase 0 (pré-clínica) - 10 a 15 indivíduos, são estudos não-randomizados, não cegos e não controlados, dura de semanas e o objetivo é o estudo Farmacocinético e Farmacodinâmico, Os testes são realizados com doses subterapêuticas. Fase 1 - 20 a 80 indivíduos, são estudos não-randomizados, não cegos e não controlados, dura de semanas e o objetivo o estudo Farmacocinético e Farmacodinâmico. O objetivo é determinar a confiança e segurança dos medicamentos em pessoas saudáveis e definir a Dose Máxima Tolerada (MDT) e os efeitos. Fase 2 - 50 a 200 indivíduos, dura de semanas a meses. São estudos randomizados de pequeno porte. É onde começa os Ensaios iniciais de investigação clínica do efeito do tratamento e a segurança. Na fase Fase IIa, grupos de pacientes com certos tipos de doença são tratados com a droga na dose igual à MTD para estudar a atividade da droga. Na Fase IIb oo objetivo é encontrar a dose terapêutica apropriada. Fase 3 - 200 a 1000 indivíduos, dura de meses a anos, (estudo clínico prospectivo, controlado, randomizado, cegos ou duplo cegos, muiticêntricos). Compara com o tratamento padrão (ouro) vigente disponível para a mesma condição clínica. Testa a significância estatística e busca subsídios para autorização de comercialização da terapia. São os mais caros e demorados. Fase 4 (Vigilância pós comercial) - 1000 a milhões indivíduos, dura anos, ocorrem após a comercialização da droga e objetivam expandir o conhecimento sobre toxicidades mais raras (efeitos adversos). A relação entre as amostras é expressa pelo risco relativo. Procura-se verificar a incidência de efeitos adversos nas amostras de expostos e não-expostos. No Ensaio clínico controlado (controlled clinical trial) uma amostra é o controle e a outra sofre intervenção formando portanto, grupos NÃO pareados. No Ensaio clínico paralelo (parallel clinical trial) cada elemento da amostra é analisada duas vezes, uma antes e outra após a intervenção, formando portanto, amostras pareadas. No Ensaio clínico cruzado (ensaio sequencial, crossover clinical trial) é feita uma intervenção paralela seguida de um tempo de clareamento e depois de outra intervenção paralela com as amostras trocados.
Envolve a intervenção em toda uma comunidade, não apenas pequenas amostras de indivíduos. É usado para avaliar a eficácia e efetividade de intervenções que busquem a prevenção primária através da modificação dos fatores de risco na comunidade. É conduzido dentro de um contexto sócio-econômico de uma população naturalmente formada. Limitações: pequeno número de comunidades podem ser incluídas; difícil de isolar uma comunidade.
RCT (Randomized Controlled Trial, prospective) - Ensaio onde pesquisador seleciona ao acaso (randomizado) um grupo de pacientes que é submetido ao novo tratamento teste e um outro grupo que recebe placebo ou o tratamento clássico (controlado) para aquela doença. É prospectivo por que os pacientes são seguidos durante um intervalo de tempo, ao final do qual os resultados comparativos são analisados.
8- Estudo confirmatório ou teste de hipóteses clínicas...
Estudo confirmatório (Confirmatory study), também conhecido como estudo de teste de hipóteses de ensaios clínicos - inclui alguns dos estudos de fase 2 tardia, todos os estudos clínicos de fase 3 e a maioria dos estudos de fase 4. O objetivo é encontrar evidência de eficácia ou segurança para apoiar os argumentos médicos e promocionais de determinado produto.
III) quanto à escala de mensuração da variável 1- Quantitativa (métrica) razão: numerador/denominador. Ex: pessoas/sala, mg/mL...
É o mais alto nível de mensuração, dá p'ra contar, comparar, somar, subtrair, multiplicar ou dividir. Tem todas as propriedades da escala de mensuração intervalar mais um zero absoluto (ausência da característica), e a razão ou a proporção entre dois valores é válida. Ex: Peso_1 = 100 kg. Peso_2 = 50 kg. Peso_2/Peso_1 = 2, ou seja o Peso_2 é 2x maior que o Peso_1 ou o Peso_1 é 50% menor que o Peso_2. Contra_exemplo: A água a 100ºC (373ºK) não está 100x mais quente que a 0°C (273°K), e sim, 1,37 vezes mais.
2- Quantitativa (métrica) intervalar: Intervalos (diferenças). Ex: tempo, temperatura (°C, ºF), densidade, QI...
Dá p'ra contar, comparar, somar, subtrair. Tem todas as propriedades da escala ordinal mais o fato de que o intervalo (distância ou diferença) entre os valores (ou categorias) é constante. Ex: A diferença de temperatura da água entre 50ºC (373ºK) e 0°C é igual à diferença 75ºC e 25°C.
3- Qualitativa (categórica) ordinal: Classe ordenada. Ex: estágio (inicial, terminal); escolaridade (1º, 2º, 3º grau)... Ranks ou postos: Quando os dados representam a posição relativa, postos (ranking) dos membros de uma amostra com relação a alguma ordenação. Escores: São usados quando não é possível fazer medições diretas, são classificações subjetivas, como a dor. Normalmente se compara medianas, quartis ou proporções usando o Teste do Qui-quadrado, Teste de Kruskal-Wallis, regressão logística, etc. As medidas de associação mais comum é: O coeficiente rs de Spearman. 4- Qualitativa (categórica) nominal: Classe não-ordenada. Ex: sexo, cor dos olhos (azul, marrom, verde), doente/sadio...
Dá p'ra contar e avaliar a sequência. Uma moeda balanceada (p = 0,5) pode não ser honesta se as primeiras 50 jogadas deu cara e as últimas 50 coroa. É o mais baixo nível de mensuração, só dá p'ra contar (somar). É a mais famosa por causa da variável qualitativa nominal dicotômica (ser ou não ser!), não há ordenação entre as amostras. Exemplos: sexo, cor dos olhos, fumante/não fumante, doente/sadio, profissão. Normalmente se tem uma tabela de contingência (2x2) e se compara as proporções usando o Teste do Qui-quadrado de Pearson. As estatísticas possíveis são: a moda e a contagem de freqüências. e as medidas de associação mais comuns são: Odds ratio, Risco relativo e o coeficiente de contingência C.
5- Dados censurados...
Dados Censurados ocorrem, quando alguns sujeitos em estudo não terminam o evento de interesse, ou seja, falham até o fim do estudo ou tempo de análise.
1- Censura Tipo I: o teste será terminado após um período pré-estabelecido de tempo. 2- Censura Tipo II: o teste será terminado após ter ocorrido a falha em um número pré-estabelecido de sujeitos sob teste. 3- Censura Tipo III: o período de estudo é fixado e os sujeitos entram no estudo em diferentes tempos durante aquele período. IV) quanto ao tipo de amostragem Amostragem é uma técnica e/ou conjunto de procedimentos necessários para descrever e selecionar as amostras, de maneira aleatória ou não, e quando bem utilizado é um fator responsável pela determinação da representatividade da amostra em relação à População. (LEONE, Rodrigo. ET AL, 2009). : 1- aleatória ou probabilística = representa a população, 2- determinística.
Amostra aleatória que dizer que a Amostra foi obtida por um processo de Amostragem aleatória. Variável aleatória quer dizer que uma das características (variável) da População representada na Amostra foi obtida por um processo de Amostragem aleatória.
1- Amostragem aleatória: 1- simples, 2- estratificada, 3- conglomerada simples (clusters), 4- conglomerada sistemática... Tabela geral.
1.1- Amostragem aleatória (randômica) simples - Cada elemento (variável) da população tem a mesma probabilidade conhecida e diferente de zero (p ≠ 0) de ser selecionado para compor a Amostra aleatória (pareadas e independentes). 1.2- Amostragem aleatória (randômica) estratificadada - A população é dividida em grupos mutualmente excludentes (como grupos de idade) e grupos randômicas são sorteadas para cada amostra. 1.3- Amostra conglomerada por área (Clusters)- A população é dividida em grupos mutualmente excludentes (como quarteirões) e o pesquisador sorteia uma amostra de grupos para ser entrevistada. 2- Amostragem não-randomizada: 1- por conveniência (acidentais), 2- intencional (julgamento), 4- cota (proporcional)... Tabela geral. É aquela em que a seleção dos elementos da população para compor a amostra depende ao menos em parte do julgamento do pesquisador ou do entrevistador no campo. 2.1- Amostragem de conveniência (acidental) - O pesquisador seleciona acidentalmente membros da população mais acessíveis. 2.2- Amostragem intencional (julgamento) - O pesquisador seleciona intencionalmente membros da população mais acessíveis. 2.3- Amostragem por cotas (proporcional) - O pesquisador entrevista um número predefinido de pessoas em cada uma das várias categorias. V) quanto ao tamanho 'N' das amostras VI) quanto ao relacionamento entre os grupos VII) quanto à técnica de mascaramento: 0- ausente, 1- na intervenção, 2- na coleta de dados, 3- na análise estatística.
1- Mascaramento (cegamento) na intervenção: 1- controlado (placebo x droga), 2- não-controlado.
2- Mascaramento na coleta de dados: 1- aberto, 2- simples cego e 3- duplo cego. 2.1- Aberto: todos os envolvidos têm acesso a informação. 2.2- Simples cego: apenas os participantes não sabem de qual grupo fazem parte. 2.3- Duplo cego: nem os pesquisadores, nem os participantes têm conhecimento sobre qual grupo fazem parte. 3- Mascaramento na análise estatística. Impede que o responsável pela análise estatística crie tendências (viés). VIII) quanto a origem dos dados: 1- fonte primária, 2- fonte secundária, 3- fonte terciária.
1) Primária
1.1) Coleta de dados de campo (formulário de campo). 1.2) Coleta de dados registrados em papel (prontuário ou formulário de laboratório). Laboratório - interferência artificial na produção do fato/fenômeno ou artificialização de sua leitura, geralmente melhorando as capacidades humanas de percepção. 2) Secundária 2.1) Bibliografia - faz parte de qualquer pesquisa, seja de campo ou de laboratório. IX) quanto ao procedimento: 1- histórico, 2- estatístico, 3- estruturalista, 4- funcionalista, 5- comparativo e 6- monográfico.
6) Monográfico: Trabalho sistemático e completo sobre um assunto particular, usualmente pormenorizado no tratamento, mas não extenso em alcance.
?7- Revisão sistemática: Síntese estatística dos resultados numéricos de diversos estudos que avaliam a mesma questão.
1- Estudo monocêntrico: Normalmente é um ensaio clínico que ocorre em apenas uma instituição médica sob a responsabilidade de um pesquisador principal.
2- Estudo multicêntrico: Normalmente são ensaios clínicos que ocorrem em mais de uma instituição médica sob a responsabilidade de um pesquisador coordenador. Use o aplicativo EpiInfo do CDC! O StatCalc é muito bom, tanto para calcular o qui-quadrado quanto para calcular o tamanho da tamanho da amostra. Há dois tipos de cálculo do tamanho da amostra para Estudos TRANSVERSAIS: 1- Cálculo para estimativa de prevalência: Use o Survey (levantamento) e especifique a Prevalência estimada (20%) a Margem de confiança (95%) e o Erro tolerável (10%). Tecle F4 e o 'n' amostral deverá ser 61 indivíduos. 2- Cálculo para testar associação de Estudos TRANSVERSAIS: Use o Cohort ou o cross-sectional e especifique o Poder estatístico (80%), Erro alfa (5%) Expostos na população. Prevalência de doentes entre os não expostos. Razão de prevalência estimada. Há 1 tipo de cálculo do tamanho da amostra para Estudos LONGITUDINAIS: 1- Cálculo para testar associação de Estudos de caso-controle: Use o Case control studies e especifique o Poder estatístico. Nível de confiança (1 - α). Razão de DI. Prevalência de exposição entre os controles. Número de controle por caso. Exemplo_1: Poder estatístico (80%). Nível de confiança 1 - α (95%). Frequência da doença entre os não expostos (5%). Risco relativo (2). Resposta: n = 473. Exemplo_2: Beta (80%). Alfa (95%). Frequência da doença entre os não expostos (5%). Frequência da doença entre os expostos (20%). Risco relativo (4). Resposta: n = 88. Ao resultado acrescente 10% para compensar eventuais perdas e 30% para fatores de confusão. PODER ESTATÍSTICO é a probabilidade da pesquisa encontrar uma diferença quando na realidade esta diferença existe. NÍVEL DE SIGNIFICÂNCIA ESTATÍSTICO é a probabilidade da pesquisa encontrar uma diferença quando na realidade esta diferença NÃO existe (é o valor de ALFA). 1- redução do risco relativo 2- redução do risco absoluto 3- número necessario para tratar 4- odds ratio
Os amostras pareadas tem que ter o mesmo número de elementos "n", isto porque a diferença é feita comparando o elemento antes com ele próprio depois de um evento, comparando o lado direito com o esquerdo ou estudanto a relação de causa e efeito (efeito sem causa é milagre).
Pode haver vícios (viés; bias) vícios no delineamento, na amostragem, nas medidas, na escolha das variáveis e outros.
Crie uma lista aleatória de entrada para um experimento hipotético de, n = 20, e ordene-os para verificar se formam aproximadamente uma reta e desfaça para voltar à formação aleatória. Crie 2 amostras com a variável nominal 'M' e 'F' ao lado e ordene os números aleatórios novamente gerando a Lista de entrada aleatória para amostras independentes.
|
|
1) O Conceito é o significado que a pessoa tem a respeito de qualquer coisa, pessoa ou processo, os distúrbios mais frequentes são a desintegração e condensação de conceitos.
2) O Juízo consiste na afirmação ou negação da existência de relação entre dois conceitos e, cujo critério de verdade é a realidade objetiva, os distúrbios mais frequentes são os delírios. 3) O Raciocínio é a correção ou não da relação entre dois juízos formando uma série de idéias sequenciais lógicas (Modus ponens: Todo homem é mortal. Aristóteles é homem, logo Aristóteles é mortal). O raciocínio psicológico (teleológico ou lógica das exceções) nem sempre obedeçe ao rigor lógico por uso de "pontes" conceituais inexistentes (Aristóteles, o grande, o imortal), os distúrbios mais frequentes são a prolixidade de raciocínio e o pensamento obsessivo. Por outro lado, o raciocínio Lógico tem sempre uma relação quantitativa (matemática) ou de grupos (teoria dos conjuntos) fazendo "ponte" entre os argumentos.
Grafo é um conjunto não vazio de elementos e outro conjunto do relacionamento entre estes elementos. Caminho uma sequência de vértices (elementos) tal que de cada um de seus vértices há uma aresta (relacionamento) para o próximo vértice. O Sistema Circulatório é um exemplo de Grafo fortemente conexo (conectado), onde há pelo menos um caminho partindo de um elemento e chegando até ele mesmo. Use como exemplo os caminhos (ligações) entre a veia cefálica e o arco ranino para entendar que a pesquisa; O objetivo é encontrar uma (ou mais) ligação entre os elementos e que o valor de "P" é a medida estatística deste relacionamento.
Uma palavra chave é um conceito ou uma variável.
|
|
1- É o conjunto de métodos que envolvem a coleta, a apresentação e a caracterização de um conjunto de dados de modo a descrever apropriadamente as várias características deste conjunto.
2- É o resumo ou descrição das características importantes de um conjunto conhecido de dados populacionais. não confunda com Chance (Odds) = ndesejado / nnão-desejado = p%/(100-p%)
A- Tamanho da amostra (n), da população (N), margem de erro (5%), poder do teste, σ, p
3- A variável é recorrente temporal... Série temporal
I- A amostra foi obtida por amostragem aleatória simples (amostra aleatória)...
Exemplos... lembre-se: 1- O 'n' de um estudo piloto é de 30 a 40 sujeitos! 2- Uma população é finita quando N < 10.000 sujeitos ou quando o 'n' da amostra é > 5% da população.
Da mesma forma se pode calcular a margem de erro (E). Depois de determinar o 'n' veja Amostragem no Excel para identificar aleatoriamente os sujeitos da amostra. Variável qualitativa2.401 é o tamanho da amostra 'n' de uma população infinita com nível de confiança de 95% (α = 0,05, Zα/2 = 1,96) e erro amostral de 2% da real proporção p = 0,5, ou seja, p estará entre 0,48 e 0,52.
385 é o tamanho da amostra 'n' de uma população infinita com nível de confiança de 95% (α = 0,05, Zα/2 = 1,96) e erro amostral de 5% da real proporção p = 0,5, ou seja, p estará entre 0,45 e 0,55. 4 é o tamanho da amostra 'n' de uma população infinita com nível de confiança de 95% (α = 0,05, Zα/2 = 1,96) e erro amostral de 50% da real proporção p = 0,5, ou seja, p estará entre 0,25 e 0,75. 135 é o tamanho N da população finita (n > 5% de N) que é representada por uma amostra n = 100 sujeitos, com nível de confiança de 95% (α = 0,05, Zα/2 = 1,96), com erro amostral de 5% da real proporção p = 0,5, ou seja, p estará entre 0,45 e 0,55. 1- A população é infinita...
1.1 - O tamanho da amostra é em relação à média da população...
n = Número de indivíduos na amostra.
Zα/2 é o nível de confiança desejado (entre), para α = 0,05, Z = 1,96. σ = desvio-padrão da população. E = Margem de erro, é a diferença máxima entre a média amostral X e a verdadeira média populacional (σ), é a metade do IC[95%], H0: A proporção de votos entre os dois canditatos é igual. H0: P(votos) = 0,5. H1: H0 é falsa. α=0,05 à direita. "Bonner: para mais ou para menos...". 1.1.1- O desvio-padrão da população (σ) é conhecido... 1.1.2- O desvio-padrão da população (σ) NÃO é conhecido... 1.1.2.1- A população tem distribuição Normal... estima-se σ dividindo-se a amplitude da amostra por 4. 1.1.2.2- A população NÃO tem distribuição conhecida.... deve-se fazer um Estudo piloto. 1.2 - O tamanho da amostra é em relação à uma proporção da população... n = Número de indivíduos na amostra.
Zα/2 é o nível de confiança desejado (entre), para α = 0,05, Z = 1,96. p = Proporção populacional de indivíduos que pertence a categoria estudada. q = Proporção populacional de indivíduos que NÃO pertence à categoria estudada (q = 1 p). E = Margem de erro, é a metade do IC[X%], ex: 56±5%. 1.2.1- A proporção da população (p) é conhecido... 1.2.2- A proporção da população (p) NÃO é conhecido... 1.2.1 - A população tem distribuição Normal... estima-se p e q como iguais a 0,5. 1.2.1- A população NÃO tem distribuição conhecida.... deve-se fazer um Estudo piloto. 2- A população é finita...
Caso a amostra tenha um tamanho (n) maior ou igual a 5% do tamanho da população (N), considera-se que a população seja FINITA. Neste caso, aplica-se um fator de correção às equações anteriores.
2.1- Tamanho da amostra (n) com base na estimativa da média populacional de N sujeitos. 2.2- Tamanho da amostra (n) conhecendo-se a proporção (p) do evento na população (N). Nível de confiança 95%: Z = 1,96; Margem de erro (máximo admissível): e = 5%; p = 50% (pior cenário); 10%; 5% e 1%. Funciona como se vc quisesse determinar um n para provar que sua advinhação de 'p' é verdadeira para um dado N, Z e e.
2.3- Erro tipo II e Tamanho da amostra 2.3- Tabela Quanto maior for o tamanho da população, o mesmo tamanho de amostra resulta em uma margem de erro menor. Inversamente, para populações pequenas são necessárias amostras muito maiores para atingir uma margem de erro razoável.
II- Amostra pareada e independente... B. Geração de "resultados", padrões de distribuição de frequência normal, uniforme, etc...
1- Números aleatórios com distribuição uniforme: muito usada para gerar a lista (de entrada) aleatória de amostras independentes e evitar viés de aprendizagem. Como reconhecer: Ordene-os e o gráfico se apresenta aproximadamente como uma reta.
2- Números aleatórios com distribuição Normal: esta é centro do pesadelo, sem vê-la vc continuará perdido. C. Tabela mãe (o legado)...
Tenha cuidado com a Tabela mãe, até profissionais erram... : L linhas+1; C colunas+2: 1ª coluna = chave primária; 2ª- grupos; 3ª- var_1; ...; nª+2- var_n.
1- Anatomia de uma tabela descritiva...
Título: Explica o conteúdo.
Corpo: Formado pelas linhas e colunas dos dados. Cabeçalho: específica o conteúdo das colunas. Coluna indicadora: específica o conteúdo das linhas. Opcional: fonte, notas, chamadas. Em Estudos transversais, a frequência relativa (ou porcentual) é chamada de PREVALÊNCIA, e, em Estudos longitudinais, de INCIDÊNCIA. 2- Tipos de Tabelas de distribuição de frequência: Frequência absoluta, relativa e acumulada... 2.1- Tabela de contingência (ou de dupla entrada). 2.2- Tabela de distribuição de frequências de variável nominal.
1- Algumas notações: Estatísticas se refere à amostra e Parâmetros se refere à população...
Tamanho: da amostra (n), da população (N). Graus de liberdade: gl = n - 1 (n do grupo). Média: da amostra X̅, da população (µ, leia mi de micro). Mediana: Med ou Md0, Moda: Xm, Amplitude inter-quartil... Variância: da amostra (S2), da população (σ2, leia sigma) = Soma dos quadrados dos desvios / n ou N. Desvio-padrão: da amostra (S), da população (σ) = Raiz quadrada da variância. Erro padrão da média (EPM) = Desvio-padrão / Raiz quadrada de n Margem de erro = t(gl;α/2)*EPM. Intervalo de confiança da média IC[95%] = X̅ ± margem de erro. Ou seja, a média de uma nova amostra é considerada igual a média representativa se cair no intervalo de confiança. :2- As medidas de forma: 1- Curtose, 2- Assimetria. 3- As medidas de dispersão ou variabilidade: 1- Variância (S2 ou σ2) ⇒ 2- Desvio padrão; (S ou σ) ⇒ 3- Erro padrão da média (EPM) ⇒ 4- Graus de liberdade (gl) e nível de significância (α) ⇒ 5- Margem de erro da média ±(z(α/2) ou t(α/2))*EPM ⇒ 6- Intervalo de Confiança CUIDADO! Com o IC pode-se comparar a média de uma amostra (amostra) com a média da POPULAÇÃO µ e σ = 0, NÃO com a média de outro Grupo! Neste sentido, o Censo da população brasileira é uma amostra (assim como a População de uma ilha). Mas, para evitar problemas FINJA que o σ ≠ 0, argumentando que a Normal Padrão tem como µ = 0 e σ = 1!, mas pense 1*0 = 0... (1-α)% de que?; 7- Coeficiente de variação = Desvio padrão/média *100; 8- Intervalo (ou Amplitude); 9- Mínimo; 10- Máximo; 11- Soma; 12- Contagem.
E. Intervalo de confiança [1-α]% para X̅, p, S, etc: Se este tópico não ficar claramente entendido, desista!...
1- Para os valores de uma amostra grande com distribuição N: IC[95%] dos valores Z = µ ± Z(α/2)*σ (α = 0,05)
IC[95%] relativo de X̅a = X̅a ± t(gl, α/2) * MEr, onde, MEr = (S2a/na) * ((S2a/na + S2b/nb)^-0,5)
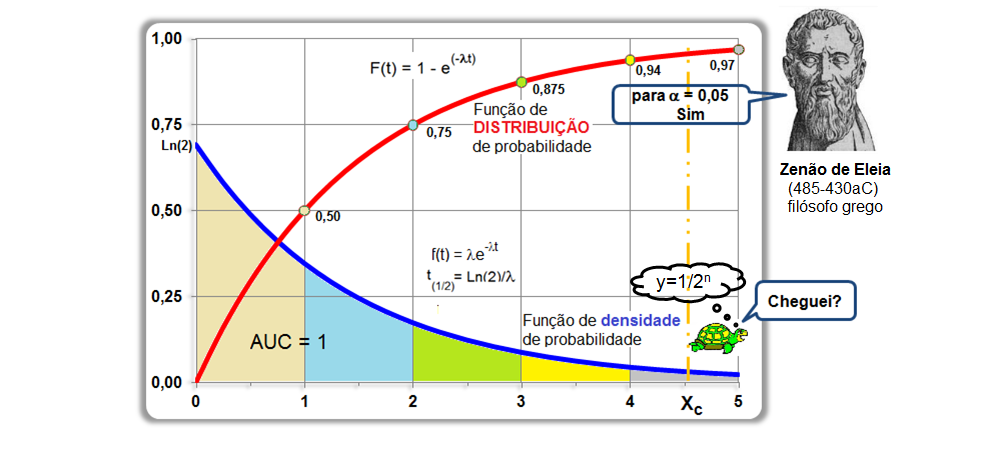
A curva de Gauss, a última das curvas t com valor crítico (α = 0,05) bilateral de 1,96, não 1,98!!!.
Se a área total é 1, então, de -oo até 0 = 0,5, concluímos que até 1,96 a área total é 0,5 + 0,95/2 = 0,975, em outras palavras, é 0,95 + 0,025 à esquerda. Densidade na prática!
A curva Dose-Resposta farmacológica. 2- Para os valores de uma amostra pequena (n<30) com distribuição t: IC[95%] dos valores t = X̅ ± t(gl, α/2)*S 3- Para a média (X̅) com variância populacional (σ2) conhecida: IC[95%] da X̅ = X̅ ± Z(α/2) * EPM (EPM = σ/√n) Cuidado, este IC[95%] só serve para confundir..., se o valor crítico é 1,96 (α = 0,05, bilateral) então no 'n' tem que ser muito, muito alto, a última das curvas t.
4- Para a média (X̅) com variância (σ2) desconhecida: IC[95%] da X̅ = X̅ ± t(gl; α/2) * EPM (EPM = S/√n)... 5- IC relativo X̅a e X̅b com distribuição t: Representação gráfica do Teste t de Student... Intuitivamente sabemos que se os IC das médias não se sobrepõem, o P < α, mas, isto não quer dizer que se eles se sobrepõem o P não possa ser menor que α, a menos que se use estes IC relativos. IC[95%] relativo de X̅b = X̅b ± t(gl, α/2) * MEr, onde, MEr = (S2b/nb) * ((S2a/na + S2b/nb)^-0,5) 6- Para os valores de uma amostra (n) dicotômica com p = 0,5: IC[95%] dos valores = n/2 ± 0,98*√n 7- Outros tipos de IC...
6- Para uma proporção (^p) com p conhecido: IC[95%] de ^p = ^p ± Z(α/2) * (p*(1-p) / n)^0,5
8- Para uma proporção (^p) com p desconhecido: IC[95%] de ^p = ^p ± t(gl, α/2) * (^p*(1-^p) / n)^0,5 9- IC[95%] para ΔX̅s independentes com σ2s conhecidas... 10- IC[95%] para ΔX̅s independentes com σ2s equivalentes e desconhecidas... 11- IC[95%] para ΔX̅s independentes com σ2s diferentes e desconhecidas... 12- IC[95%] para a Δ^ps independentes... 13- IC para a σ2s de uma população normal... 14- IC para a razão entre as σ2s de duas populações normais... 15- IC para a Odds Ratio Se 1 estiver dentro do IC... 16- IC para a Risco Relativo... F. Modelos probabilísticos (Função de densidade e de DISTRIBUIÇÃO de probabilidade) 1- A variável é quantitativa (intervalar ou razão) para calcular os parâmetros (coeficientes ou pesos)!!! 1.1- A variável tem distribuição normal de Gauss, X ~ N(µ; σ) Entre (bilateral): Área entre [-1:1] ≅ 70% (grande maioria); entre [-2:2] ≅ 95% (melhor [-1,96:1,96]), a imensa maioria), entre [-3:3] ≅ 99% (praticamente todo mundo). Até (unilateral): Área até [-oo:0] = 50%; até [-oo:1] ≅ 84%, até [-oo:1,645] ≅ 95% ou α = 0,05(*). Função de DISTRIBUIÇÃO (1-α) de probabilidade da Normal Se X~N(0;1), teste unilateral à direita, α = 0,05 e z > zc (1,645) então P (tem que ser!) < α e, portanto, rejeitamos H0.
Considere uma população de adultos. Seja X a variável aleatória intervalar que representa a altura H destas pessoas. Considere que µ = 170cm e σ = 10. Determine x de modo que 95% das pessoas tenham uma altura abaixo ou igual a esta altura H, calculado por z = 1,64, aproximadamente, para 0,95. Qual o número esperado de pessoas com altura superior a 1,65 m?
1.2- A variável tem distribuição t de Student À medida que o 'n' da amostra aumenta (graus de liberdade, lembre-se que cada gl é uma curva), a distribuição da "família" t de Student se aproxima da Normal (Teoria Central do Limite). A t com 1 gl (n = 2) é chamada de Função de densidade probabilidade de Cauchy. Ex: para 3 gl, 95% dos sujeitos da amostra estão entre ±3,18 s, já se for até (unilateral, acumulado) à direita, o valor é tc = +2,353. Função de DISTRIBUIÇÃO (1-α) das curvas t de Student. , X ~ t(gl; X̅; S), α = 0,05, tcuni (1,645:6,314); tcbi (±1,96:±12,71).
Se X1 e X2 ~ t(gl; x̅; s), gl = 1; Stat t (t calculado) > tc (6,314) então P < α e, por isso, rejeitamos H0. De fato, se o teste é unilateral à direita (H1: Média do Grupo A > Média do Grupo B; α=0,05. H0: H1 é falsa) e t > 6,314, SEMPRE rejeitaremos H0.
William Sealey Gosset (1876-1937), químico irlandês, publicou o Teste t sob o pseudônimo de "Student".
1.3- A variável aleatória tem distribuição qui-quadrado A função Χ2 é de Ernst Abbe (1840-1905), físico alemão, usado por Karl Pearson (Testes de Aderência e de Independência) e pelo Bonner do JN. Lembre-se que na Normal, ±1,96 desvio-padrão (bilateral) contém 95% da população (α = 0,05) e, 1,962 = 3,84, que é o valor crítico do Χ2 com 1 gl. Já para 68% da população (α = 0,32), z = ±1, o valor crítico do χ2 = 12 com 1 gl. Função de densidade de probabilidade do χ2 , X ~ χ2(ν; Ei), v = 1 é filha "quadrática" da Normal.
À medida que o 'n' da amostra aumenta... se aproxima da Normal. Atenção: As cores das curvas densidade x DISTRIBUIÇÃO não estão batendo.
Ernst Abbe (1840-1905), físico alemão.
A variável contínua v [nu], que tem distribuição de x² é definida como sendo o quadrado da variável u de distribuição normal reduzida ou seja: v = u2. Como u tem média zero 0 e variância 1, a variável v necessariamente passa pela origem e, por ser o quadrado de u, será sempre positivo ou nulo. Ex: O IC(95%) normal está entre -1,96 a 1,96, portanto o valor crítico do Χ2 com 1 GL é de 1,962 = 3,84, isto quer dizer que pode-se usar a Normal para calcular o Χ2 com 1 gl. C1 = 1/(2^0,5*EXP(LNGAMA(A1/2)*0,5))*(A1^-0,5)*EXP(-A1/2) para X (AI) > 0 gl = 1.
1.4- A variável tem distribuição F de Fisher-Snedecor ≈ Qui-quadrado. Adequadas para representar a Concentração plasmática x tempo de uma ingestão um fármaco (é assimétrica à direita ou curtose positiva já que Média > Mediana > Moda), lembra? , X ~ F(m; n), ANOVA e [Plasmática] x tempo ⇒ ASC.
O modelo F de Snedecor foi inicialmente desenvolvido por Ronald Aylmer Fisher (1890-1962) em 1922 e, por isso, ele é também conhecido por distribuição de Fisher-Snedecor. Em 1934 foi tabelado por George Waddell Snedecor (1881-1974) que também introduziu a letra F para representá-lo, homenageando dessa fora o seu real criador
1.5- A variável tem distribuição Dose-Resposta Área entre [-1,59:1,59] ≅ 95%. Área de -oo até 1,27] ≅ 95%. Densidade da frequência (φ±1,59 = 0,299) = Frequência da classe (0,95) / Largura da classe (2*1,59)
Curva dose-resposta clássica. Curva de densidade Normal x DR
Apesar destas curvas serem evidentemente diferentes... e Curva de DISTRIBUIÇÃO Normal x DR...os valores das suas respectivas integrais são praticamentes iguais!
A constante hiperbólica "S" é igual a 10 elevado ao coeficiente de Hill. Quando este coeficiente = 1 todos os modelos são equivalentes, é Curva dose-resposta clássica. Veja também Análise de 2 variáveis - 3.1- Curva Dose-Resposta. 1.6- Outras funções probabilísticas intervalares...
1.6- A variável tem distribuição exponencial
Usada em problemas que envolvem modelos abertos de um compartimento com parâmetros como t½ (Farmacocinética), λ = 0,693/t½ * Vd, ou, Decaimento radioativo. , X ~ E(λ), parâmetros farmacocinéticos (Clearance, t½ = Ln(2)/λ, Vd).
Muito usado em problemas que envolvam (tempo, distância, área, volume...). A média e o desvio padrão são iguais a 1/λ. A função de densidade de probabilidade da distribuição exponencial é f(x) = λe-λx. Como a variável é contínua (tempo) a análise é de intervalo/evento, diferentemente da distribuição de Poisson onde a variável é discreta e a análise é de evento/intervalo (tempo, distância, área, volume, etc). Ex: Qual a probabilidade que o intervalo de tempo até o próximo evento esteja entre 10 e 15 segundos (Exponencial). Qual a probabilidade de ocorrer 2 eventos em 1 km qualquer? (Poisson).
1.7- A variável tem distribuição uniforme A f.d.p. é constante dentro de um intervalo de valores da variável aleatória X. , X ~ U(a; b), é a mais fácil.
1.8- A variável tem distribuição de Weibull ≈ Poisson. Análise da sobrevivência , X ~ W(k; λ), análise da sobrevivência.
Uma das principais vantagens da distribuição de Weibull na análise da sobrevivência é que, através da estimativa de apenas dois parâmetros, são obtidas informações tanto de longevidade média quanto do tipo de curva de sobrevivência. Outra vantagem é que as observações não necessitam ser realizadas a intervalos constantes. Um dos parâmetro é a forma (shape) e o outro é a escala (scale).
1.9- A variável tem distribuição de von Bertalanffy Muito usada para representar crescimento de plantas e animais , X ~ Ber(k; t0), modelo de crescimento.
1.10- A variável tem distribuição Gama E(x) = α/β; Var(x) = α/β2. Se α = 1 equivale à Exponencial. Se α é inteiro equivale a Erlang. Se α = n/2 e β = 1/2 equivale a Χ2. Função de DISTRIBUIÇÃO Gama 1.11- A aproximação para a Normal é válida: Teorema Central do Limite...
O Teorema Central do Limite (Central Limit Theorem) estabeleçe que: "À medida que o tamanho da amostra aumenta, os dados amostrais tendem à distribuição Normal".
5.1- A aproximação da distribuição Binomial para a distribuição Normal é válida.
Para efeitos práticos esta aproximação é satisfeita sempre que n.p > 5 e p ≤ 1/2. Neste caso µ = n.p e σ = (n.p.q)^0,5. Além disto, é necessário se aplicar a Correção de continuidade já que curva Binomial não se encaixa exatamente na Normal.
5.2- A aproximação da distribuição Geométrica para a distribuição Normal é válida
2- A variável é categórica (ordinal ou nominal) (Bernoulli, binomial, Poisson...)
Razões, proporções, taxas e medidas de frequência: Prevalência, Incidência (frequência relativa), Taxa de incidência e Risco (Incidência cumulativa ou Probabilidade de incidência).
2.1- A variável é binária (nominal dicotômica), ex: cara/coroa, morreu/sobreviveu, presente/ausente, certo/errado) 2.1.1- A variável aleatória tem distribuição de Bernoulli, X ~ Be(p), filha da Binomial quando n = 1.
Variável dicotômica, P(X = x) = px . q1-x. Média: E(X) = p. Variância: Var(X) = p (1 - p).
Aplicações: No Modelo de Regressão Logística a variável independente é a preditora e a Variável dicotômica é o desfecho. É um modelo muito usado em estudos longitudinais (Prospectivo) para avaliar Fatores de Risco (em estudos transversais são chamados Fatores Relacionados). Exemplo: O tempo de consumo de cigarros (variável contínua preditora) é Fator de Risco para o Câncer de pulmão (variável dicotômica de desfecho ou outcome). 2.1.2- A variável aleatória tem distribuição Binomial Onde μ = n.p; σ = (n.p.q)0,5. Lembrar da correção de continuidade (acrescentar ou reduzir 0,5 da variável aleatória), utilizado para melhorar a aproximação de uma variável aleatória discreta pela distribuição normal que é contínua. , X ~ B(n; p), sim/não, cara/coroa, deu ou não deu...
Usada em Testes não-paramétrico, 1 grupo dicotômico, em eventos que podem ser representados por 'n' experimentos de Bernoulli (variável dicotômica). E(X) = np e a Var (X) = np(1p).
2.2- A variável é politômica, ex: faces de um dado: face_1 a face_6, altura: alta/normal/baixa 2.2.1- A frequência pode ser representada por uma distribuição Geométrica, X ~ Ge(p)
Usada para estimar o número de tentativas de Bernoulli até obter o primeiro êxito. Sequência de experimentos de Bernoulli, independentes e com mesma probabilidade p de sucesso.
2.2.2- A variável aleatória tem distribuição de Poisson ≈ Weibull. À medida que a 'n' aumenta,... observe ainda que, fixado um tempo, a probabilidade de NÃO ocorrência de eventos neste intervalo é reduzido para uma Exponencial. , X ~ P(k; λ), nro de eventos/unidade de tempo, /área.
A distribuição ou série de Poisson ou ainda a Lei dos pequenos números é muito usado em problemas que envolvam Intervalo (tempo, distância, área, volume...). P(x) = λx.e-λ/x!. A média é igua a λ e o desvio padrão é igual a λ0,5. A Distribuição de Poisson é uma distribuição discreta de probabilidade aplicável a ocorrências de um evento em um intervalo especificado (TAXA), expressa a probabilidade de uma série de eventos ocorrer num certo período de tempo se estes eventos ocorrerem independentemente de quando ocorreu o último. Exemplos: 1- Chamadas telefônicas por unidade de tempo. 2- Defeitos por unidade de área. 3- Acidentes por unidade de tempo. 4- Chegada de clientes a um supermercado por unidade de tempo. 5- Número de glóbulos sanguíneos visíveis ao microscópio por unidade de área. 6- Número de partículas emitidas por uma fonte de material radioativo por unidade de tempo. Podemos utilizar a distribuição de Poisson como uma aproximação da Distribuição Binomial quando: n é grande e p, muito pequeno, λ = n.p, para n maior ou igual a 100 e n.p menor ou igual a 10.
2.2.3- A variável aleatória tem distribuição Reverberativa, X ~ f(α)(C; F0; w0; m) Série temporal com previsão por passo simples - previsão com base na média de 2 intervalos anteriores. (Estudo dos ciclos: cardíaco, respiratório, uréia, Krebs, etc.)
Série temporal = Série histórica (Veja - 3.2) Estudo observacional longitudinal)
Os métodos de previsão de Série(s) temporal(is) se baseiam suas previsões no interrelacionamento entre observações passadas e que o padrão da variável é recorrente no tempo. Em relação ao número de Séries envolvidas na modelagem, os métodos são classificados em: 1- Univariados - analisa apenas uma série para a realização dos prognósticos. 1.1 - Série temporal classificada por intervalos de tempo: 1.1.1- Série temporal contínua: O levantamento das observações é feito em qualquer momento. 1.1.2- Série temporal discreta: O levantamento é feito em intervalos de tempo discretos e equidistantes (maioria). 2.1- Série temporal classificada por previsão: 2.1.1- Série temporal com previsão por passo simples: Não há incorporação de previsões aos dados para encontrar a próxima previsão, sendo, portanto, independente dos valores anteriormente previstos (é usado para prever crutos períodos). Os métodos usados são: Média Móvel, Alisamento Exponencial Simples, Alisamento Exponencial Linear e Alisamento Exponencial Sazonal e Linear de Winter. 2.2.1- Série temporal com previsão por múltiplos passos: O conjunto de valores é empregado para prever um determinado instante; que é, então, introduzida entre as observações passadas, compondo um novo conjunto de dados sobre o qual será obtida a previsão do tempo subsequente (é usado para prever longos períodos). 3.1- Métodos de Decomposição de Séries Temporais: se baseia na identificação das componentes individuais presentes no padrão básico da série. 2- Funções de transferência - analisa mais de uma série temporal assumindo que haja relação de causalidade (causa-efeito) entre as séries é conhecida. 3- Multivariados - analisa mais de uma série temporal sem a presuposição de que a relação de causalidade seja conhecida. G. Agrupamento de variável, Equação de Sturges, grupos (intevalar), categoria (ordinal) ou classe (nominal)...
Renda familiar é um bom exemplo de agrupamento de uma intervalar em ordinal.
No estudo descritivo, as variáveis podem ser agrupadas em classes (distribuição de freqüência) ou por categorias (tabelas de contingência). Neste caso a variável resposta e a freqüência de cada classe ou categoria; Uma variável não métrica é analisada por categorias; Uma variável métrica pode ser analisada por classes. Assim pode-se categorizar uma variável métrica; Assim, analise previamente suas variáveis e defina quais serão analisadas por categorias; Se você quiser desejar cruzar duas variáveis categorizadas você tem um exemplo de Tabela cruzada ou tabela de contingência. & Objetivo: Identificação de grupos homogêneos com base em determinadas características. 1- Métodos de agrupamento por partição: criam os K melhores grupos, este K é imposto à partida da modelagem. 2- Métodos de agrupamento hierárquicos: agrupa-se todos os casos em Ks grupos desconhecidos de partida. 2.1- Dado um conjunto de 'n' observações, qual a equação usada para se determinar o número de grupos? Nº de classes: K = 1+3,222 log n (em geral: 5-20), chamada Equação de Sturges. Ex: n = 100, então, K = 1 + 3,222 log 100 = 7,444 (7 ou 8). 2.2- Medidas de distância. 2.3- Método de aglomeração... (lembrar a SES: medir a percepção da pobreza usando os bens da favela do Papôco!) 2.3- Standartização. Regras para formação de blocos de variáveis discretas ou contínuas... 1- As variáveis devem ser ordenadas em relação ao desfecho em "menor - pior", "maior - melhor", "menor - melhor" ou "maior - pior", ex: se o desfecho é desnutrição, quanto maior o valor do manitol, pior, o inverso para a lactulose. 2- Variáveis com "k" classes de respostas não podem fazer parte de classes superiores, ex: uma variável dicotômica, sem repetição, não pode ser classificada em 3 classes de repostas, já uma de 3 pode ser grupada e reduzida a 2. 3- Se for decidido dividir os resultados dicotômicamente, deve-se procurar balancear as classes, ex: 1,2,2,3,3,3,4. 1,2,2 é classificada como 0 e 3,3,3,4 como 1. Regressão curvilinear: Variável contínua não-linear, modela-se a variável como categórica a partir dos cut off (pontos de corte) ou baseados em quartis. Estatística analítica, Estatística de Inferência, Estatística Indutiva ou Testes de Significância são generalizações sobre uma população tomadas a partir da utilização de amostras. Erro tipo I (falso-positivo): H0 é verdadeira e é rejeitada pelo pesquisador (ex: a moeda é honesta mas o resultado foi fora do IC95%). Erro tipo II (falso-negativo): H0 é falsa e é aceita pelo pesquisador. Possibilidades de Teste de Hipóteses. A Potência (1 - β) de um teste estatístico é a probabilidade de se rejeitar H0 quando H0 é falsa.
No caso de variáveis discretas, o valor da função de densidade de probabilidade corresponde à freqüência relativa de que o resultado de um experimento seja igual ao argumento da função. No caso de variáveis contínuas, o valor da densidade de probabilidade é tal que a integral da função sobre um intervalo corresponda à freqüência relativa do resultado de um experimento caia dentro do intervalo. Nível de significância (α) é o limite que se toma como base para afirmar que um certo desvio é decorrente ou não do acaso, geralmente se determina que α = 0,05, mas este nível de exigência é arbitrário e corresponde ao risco que se corre de rejeitar uma hipótese verdadeira ou aceitar uma hipótese falsa como por exemplo uma moeda desbalanceada ser considerada balanceada. Graus de liberdade (gl) é o número de grupos (classes) de resultados menos o número de observações da amostra necessária para o cálculo dos valores esperados em cada grupos, é importante para corrigir os erros inerentes em amostras pequenas, no caso de uma tabela, gl = (número de linhas -1) x (número de colunas -1). Risco é uma medida que reflete a probabilidade de que ocorra um dano a saúde. O Risco Relativo se baseia na observação de que nem todos têm a mesma probabilidade (risco) de padecer um dano, mas que para alguns (grupos) este risco, (probabilidade) é maior do que para outros, ou, a medida da força de associação entre um fator de risco e um desfecho em um estudo epidemiológico. Grau de Risco é a medida da probabilidade de que o dano ocorra no futuro, refere-se a um resultado não desejado e não deve ser confundido com o risco. Regressão em Estatística é iqual a função em Matemática. Corealação ou Covariância é quando há relação entres as 2 variáveis ou nas suas variâncias. Modelo multivariável quando há apenas uma variável dependente. Modelo muitivariado quando há mais de uma variável dependente. Testes paramétricos x não paramétricos: Paramétricos: assume-se que a distribuição é Normal. Antes de tudo faça os seguintes testes (comparações) e Torça para aceitar H0!!!!!! H0: A distribuição de frequência é Normal e as variâncias são homocedásticas se P<0,05.H1:H0 é falsa. A. Teste de aleatóriedade para uma amostra, a estranha história da Moeda balanceada e desonesta...
1- Teste de sequência para uma amostra, nominal, Transformação z ou t ...k,c,k,k,c,c,k,k,k,c,c,c,k,k,k,k,c,c,c,c...
H0: A sequência da amostra é aleatória. H1: H0 é falsa. α=0,05. A amostragem é aleatória ou determinística?
§Teste de interações de Wald-Wolfowitz (2 amostras).
H0: A amostra é tem sequência aleatória. H1: H0 é falsa. Teste de interação de uma amostra; Runs test. Usa-se para comprovar a propriedade de aleatoriedade de uma amostra utilizamos o teste de aleatorização, que faz uso da análise das iterações (sequência de símbolos idênticos), basicamente, verifica o número de iterações existentes na amostra; se o número de iterações é muito grande ou muito pequeno sugere falta de aleatoriedade. Pressuposto: Exige-se ao menos que os dados sigam uma escala nominal e que eles possam ser divididos em duas categorias. 2- Outros testes de sequência...
2- Teste de sequência cumulativa, nominal sequencial cumulativa, Stat Ψ, em construção, para aquisição de bens.
B. Intervalar, 1 grupo de cada vez, testes de ajuste ou goodness-of-fit, compara com o "padrão-ouro". H0: X̅A; X̅B; ... X̅K ~ N(µ, σ). H1: H0 é falsa. α=0,05. A amostra é paramétrica (coeficientes) ou não-paramétrica? 1- Teste de aderência de Shapiro-Wilk http://sdittami.altervista.org/shapirotest/ShapiroTest.html
H0: A frequência acumulada da amostra (= grupo) provém de uma população Normal. H1: H0 é falsa. α = 0,05.
O poder do teste (Erro tipo II) é menor que o de Kolmogorov/Smirnov e pode ser usado com qualquer 'n' amostral. O teste de Shapiro-Wilk é o teste de normalidade preferido por mostrar ser mais poderoso que todos os outros testes de normalidade.
Comparação entre Teste de ajuste, ajustamentos, encaixe ou goodness-of-fit
Comparação entre testes de ajustamento à normalidade usando o Método (de aproximação) de Monte Carlo. O S-W é o melhor e o K-S o pior.
2- Teste de Orloff: na realidade não é um teste de adesão, mas já é um início! 3- Teste de Kolmogorov/Smirnov (K-S) para uma amostra
Andrey Kolmogorov (1903-1987), matemático russo.
Teste de Kolmogorov/Smirnov (K-S) para uma amostra (há outro para 2 amostras independentes, teste não-paramétrico de Kolmogorov/Smirnov (K-S) para 2 amostras).
H0: A frequência acumulada da amostra (= grupo) provém de uma população Normal. H1: H0 é falsa. α = 0,05. O teste de Kolmogorov-Smirnov pertence à classe suprema de estatísticas baseadas na FDE, pois trabalha com a maior diferença entre a distribuição empírica e a esperada. 4- Teste de Lilliefors: usado quando a média e o desvio-padrão da população são conhecidos.
Análogo ao Teste K-S e aplicada quando se deseja testar normalidade e a média e a variância não são previamente especificadas, mas sim estimadas através dos dados da amostra.
5- Teste de Kuiper: é usado quando a variável é cíclica (como os dias da semana).
6- Teste de Anderson-Darling
Os testes Anderson-Darling e Cramer-von Mises pertencem à classe quadrática de estatísticas baseadas na FDE, pois trabalham com as diferenças quadráticas entre a distribuição empírica e a esperada.
7- Cramer-von Mises.
H0: S2A = S2B = ... = S2K. H1: H0 é falsa. α=0,05. As variâncias são homocedásticas ou herterocedásticas?...
1- Teste de Levene, intervalar, Stat F, testa a homocedasticidade (cedástico = dispersão) das variâncias...
Testa a diferença de variâncias entre 2 ou mais grupos e precede a decisão do uso do teste t não-pareado. É mais eficiente que o teste de Bartlett quando rejeitamos a hipótese de normalidade.
2- Teste de Brown Forsythe, testa a homocedasticidade das variâncias.
3- Teste de Bartlett, testa a homocedasticidade das variâncias, fácil de fazer... O teste de Bartlett é mais eficiente que o de Levene quando não rejeitamos a hipótese de normalidade dos dados. Considere o processo de produção de uma fibra sintética, no qual o experimentador quer conhecer a influência da porcentagem de algodão na resistência da fibra. Para isto, foi realizado um experimento totalmente aleatorizado, no qual diversos níveis de porcentagem de algodão foram avaliados com respeito à resistência da fibra. Um ponto importante no planejamento do experimento é que para cada nível do fator (porcentagem de algodão), os outros fatores que influenciam o processo (como o meio ambiente, máquina, matéria prima, etc) devem apresentar um padrão homogêneo de variabilidade. No experimento, tomamos 5 níveis para a porcentagem de algodão e 5 replicações. Tabela. http://www.portalaction.com.br/content/teste-de-bartlett.
4- Teste Cook-Weisberg, testa se a variância dos resíduos (erros) é constante.
1- Teste de aderência ao χ2, nominal, Stat χ2.
H0: n1 = n2 = ... = nk. H1: H0 é falsa. α=0,05. Os grupos são balanceados ou não balanceados?
Não confunda transformação de escala intervalar em agrupamento (formação de classes ou categorias).
1- Tipos de transformações mais frequentes. 2- Transformação logit - é relacionada com a propriedade da regressão logística de ser linearizada. 3- Transformação probit - obtida transformando E(Y) por meio da distribuição normal acumulada e limitado a apenas uma variável preditora. 4- Complemento log-log - Diferentemente das transformações logit e probit, esta transformação não é simétrica em torno de E(Y) = 0,5. H0: H1 é falsa. H1: A diferença das médias entre os grupos é significativa se P < 0,05.
1- Teste para comparar a média (X̅) da amostra com um dado valor ou com a X̅ da População ...5, 7, 4, 50?, 6, 7, 4...
Modelo: Os valores da pesagem de 3 animais foi 250±10 gramas. Um animal com 250 gramas pode NÃO fazer parte desta amostra com α = 0,05? Às vezes vc precisa "sacrificar" um resultado e esta é uma excelente justificativa... H0: H1 é falsa. H1: 250 ∉ IC[95%]. α = 0,05. Se X ~ t(2, 250, 10), t(2;0,025) = 4,3, IC[95%] = 225,2 a 274,8 gramas. Aceito H0, para qualquer α.
H0: X̅ (média da amostra) não é diferente de µ (média da População). H1: H0 é falsa. α = 0,05. 1.1- Caso σ > 0, a regra diz para usar o Teste da estatística Z (infelizmente ele é o principal fator de confusão uma vez que, em relação à amostra, a variância tem que ser despezível, caso contrário o que se chama de população é, na verdade, outra amostra): Calcule o Stat Z = |X̅ - µ| / σ/n0,5. Se Stat Z ≤ Zc tabelado... Conclusão: Aceito H0, a média da amostra não difere da média da População com, no mínimo, 95% de certeza. Comentário Se σ > 0 então trata-se de uma Amostra e portanto deve-se usar o Teste t... 1.2- Caso σ = 0, é o que se chama de Verdadeira Média de uma População (N ≥ 2). Teste t de Student para uma amostra: Calcule o Stat t = |X̅ - µ| / S/n0,5. Se Stat t ≤ tc tabelado... Conclusão: Aceito H0, a média da amostra não difere da média da População com, no mínimo, 95% de certeza. 2- Teste para comparar a variância (S2) da amostra com a (σ2) da População... 3- Teste para comparar uma proporção (p) da amostra com uma população Normal (po)...
IC(95%) e Teste Z para proporção, a variável categórica (em porcentagem) comparada com a da população.
1- Teste para comparar as médias entre 2 grupos (amostras)
1.1- Grupos pareados (vinculadas, em par, emparelhadas, dependentes, repetidas, "vocês 2 estão juntos?")...
1.1.1- Teste t de Student pareado para 2 médias, gl = na-1, Stat tpareado, pré-teste x pós-teste; antes x depois, D x E...
≡Teste não-paramétrico de Wilcoxon parado.
H0: H1 é falsa. H1: X̅A > X̅B, (unilateral à direita). α = 0,05.
≡Testes não-paramétricos de Mann-Whitney.
1.2.1- Teste t de Student não-pareado para 2 X̅ com S2 homocedásticas, gl = ng1+ng2-2, Stat tnão-par homocedástico
H0: X̅A - X̅A = 0. H1: X̅A > X̅B (unilateral à direita). α = 0,05. Use antes o Teste F da variância (S2) entre os 2 amostras. H0: S2A = S2B. H1: H0 é falsa. α = 0,05. Os graus de liberdade (gl) são calculados pela Equação de WelchSatterthwaite 1.2.2- Teste t de Student não-pareado para 2 X̅ com S2 heterocedásticas Use o Teste F para ter certeza de que em 95% dos casos as variâncias são diferentes... , gl = Eq. de Welch, Stat tnão-par heteroUse a Equação de Welch para calcular os graus de liberdade. Os testes paramétricos comparam a sopreposição dos Intervalos de Confiança da Média e, o cálculo do IC relativo, serve apenas p'ra se representar esta sobreposição mas "intuitivamente"!
2.1- Teste de proporção entre 2 grupos
Clique para ver as Equações e colar especial como texto no Excel , Stat z.
1- ANOVA com fator (tratamento) único pareado
2- ANOVA com fator único independente, Stat F, amostras independentes com variâncias equivalentes... O único Fator de variação (Tratamento) tem efeito em pelo menos 1 das X̅ das amostras A, B, C, D. α=0,05, e o Tratamento A é um forte candidato.
§Teste t de Student não-pareado para 2 médias com variâncias homocedásticas.
≡Teste não-paramétrico de Kruskal-Wallis. Pressuposto: S21 = S22 = ... = S2k H0: X̅A = X̅B = ... = X̅K. H1: H0 é falsa. α=0,05. Torça para rejeitar H0 ⇒ Testes post hoc ANOVA. Objetivos do Teste da ANOVA com 1 fator de variação (tratamento) e com repetições (replicações) de amostras independentes (não-pareadas). Há diferença entre as amostras de tratamento, considerando o um nível de confiança (1 - α), para α = 0,05 (mas não para α = 0,01). Comparar a média entre várias amostras independentes para uma determinada variável intervalar. Principios: 1- As amostras devem ser independentes entre si. 2- As populações devem ter distribuição Normal, exceto se o n amostral > 30. 3- As variâncias devem ser homocedásticas, exceto se o n de cada grupo for semelhante (balanceada), i.é, maior dimensão / menor dimensão < 1,5. Quando há apenas um fator de variação, isto é, quando o conjunto de dados consiste de várias amostras que devem ser comparados entre si, é possível realizar uma análise de variância desse conjunto mesmo que cada um das amostras tenha um número diferente de repetições. Esses grupos poderiam ser comparados dois a dois pelo teste t de Student. A ANOVA com 1 fator de variação tem a vantagem de comparar todos as amostras com um único teste. 3- ANOVA ponderada com fator único, Stat F, para amostras independentes e variâncias diferentes. D. ≥2 fatores com 3 ou mais grupos com variâncias equivalentes com X ~ N(µ; σ)
1- ANOVA com fator duplo sem repetição
H01: Não há qualquer efeito no fator linha. H11: H0 é falsa. α = 0,05.
H02: Não há qualquer efeito no fator coluna. H12: H0 é falsa. α = 0,05. Teste da ANOVA: fator duplo (2 ou mais fatores de variação) sem repetição (replicações) de grupos é identificar um eventual sinergismo (ou antagonismo) entre os Fatores de variação (os fatores que fazem a variável variar) na variável. A análise de variância em geral envolve amostras balanceadas (número igual de repetições), principalmente quando há diversos fatores de variação envolvidos. 2- ANOVA com fator duplo com repetição (bloco) Mesmos dados da ANOVA com fator duplo sem repetição e Valor-P completamente diferente... porque este é pareado) , Stat F, amostras pareadas com medidas repetidas...
≡Teste não-paramétrico de Friedman.
H01: Não há qualquer efeito no fator linha. H11: H0 é falsa. α = 0,05. H02: Não há qualquer efeito no fator coluna. H21: H0 é falsa. α = 0,05. Teste da ANOVA: fator duplo (2 ou mais fatores de variação) com repetição (replicações) de amostras pareadas. O número de fatores de variação não deve ser maior que 3, porque o número de interações possíveis aumenta exponencialmente (número de variâncias = 2n - 1), onde n é o número de fatores de variação. O objetivo é é identificar um eventual sinergismo (ou antagonismo) entre os Fatores de variação (grupos) na variável contínua dependente. Os princípios do teste são: 1- As amostras devem ser pareadas (vinculadas) entre si. 2- As populações devem ter a mesma variância. 3- As populações devem ter distribuição Normal. 4- Cada amostra deve ter o mesmo número linhas. 1- Variável: é a medida pela qual alguma coisa é avaliada, tais como o peso, altura, idade etc. É sempre uma só. 2- Fator de variação: é tudo aquilo que faz a variável realmente variar tais como tratamento que faça variar tais como o peso, altura, etc. Pode ser múltiplo. O teste pressupõe que o efeito final dos múltiplos fatores de variação que atuam ao mesmo tempo sobre uma variável pode ser decomposto e analisado por partes (fator com repetição). Esses efeitos parciais dependem de três tipos de Fatores de variação: 1- Fatores principais controlados - a variação é causada por fatores introduzidos de propósito no experimento e controlada pelo pesquisador; 2- Interação de fatores de interação - a variação é causada por interações entre alguns ou todos esses fatores experimentais controlados; e 3- Fatores de erro aleatórios - a variação é ocasional, não-controlada, decorrente de causas estranhas (erro experimental, variação residual ou resíduo) e é com ele que se mede o 'P' estatístico. Na Análise de variância com múltiplos fatores cada fator (ou interação) é analisado separadamente, ignorando-se os demais que são considerados como simples repetições. 1.3- ANOVA para modelos mistos E. Testes post hoc ANOVA com X ~ F(m; n) (Teste de Bonferroni, Tukey, Dunnett...)
1- Teste de Dunnett, Stat DMS, tamanhos balanceados, rigoroso, compara o grupo controle com os experimentais...
Rígido controle sobre o erro do tipo I.
2- Teste de Bonferroni, Stat Q, grupos balanceados ou desbalanceados, muito rigoroso, compara X̅ 2 a 2...
≠Correção (α) de Bonferroni: α = 0,05/k, onde k é o número de grupos (amostras) testada pela ANOVA. Lembre-se da correção (gl) de Student e da correção das varâncias heterocedásticas de WelchSatterthwaite.
H0: H1 é falsa. H1:X̅A = X̅B ou X̅A = X̅C ou ... ou X̅i = X̅j. α = 0,05. Teste de Fisher-Bonferroni, uma vez que o Stat Q ~ F(m,n). Para garantir maior controle do Erro tipo I (causado pelo número de amostras) usa-se a Correção de Bonferroni = α/número de amostras. Exemplo: α = 0,05 e número de amostras independentes k = 5, a correção (α) de Bonferroni é α = 0,05/5 = 0,01, ou seja, o será este αcorrigido que será susado para achar o P. Entretanto, a correção de Bonferroni aumenta o Erro tipo II, isto é, deixa-se de identificar diferenças que realmente podem existir. 3- Teste de Tukey HSD (honest significant difference), Stat Q, k > 30, grupos balanceados, muito Erro tipo II... Teste de Tukey-Kramer; Teste da diferença honesta significativa, proposto por Tukey, J.W. em 1953. (Compara 2 médias).
Em experimentos com muitos tratamentos e envolvendo uma variável muito instável (CV>25%) o teste favorecerá o aparecimento do erro tipo II. 4- Teste de Scheffé, Stat F um dos mais usados, mais rigoroso que o de Tukey...
Usado para amostras independentes e uma número não muito grande (10) de sub-hipóteses.
1 - Compara uma média com a combinação linear de outras ex: H0: µ2 = (µ1 + µ3) / 2. 5- Outros testes post hoc ANOVA (a ANOVA testa médias, não variâncias!!!)...
5- Teste de Duncan: poucas amostras com tamanhos semelhantes, menos poderoso que o de Tukey....
Teste pós ANOVA modificado em 1955 por Duncan, D.B. Ordena-se as médias e calcula-se a DMS .No conjunto ordenado das médias, a comparação entre a maior e a menor média corresponde a um intervalo que abrange todas as k medias. Se a diferença entre a maior e menor media for não significativa então as médias dentro desse intervalo será consideradas estatisticamente iguais e o processo pára.
6- Teste DMS de Fisher (LSD Test): amostras independentes, é o menos rigoroso e, portanto, mais Erro tipo I...
DMS (Desvio Mínimo Significativo). LSD (Least Significant Difference).
1- Compara as médias de duas em duas ex: H0: µ1 = µ2; H0: µ1 = µ3. 1 - É extremamente rigoroso na comparação de médias duas a duas e, por isso pouco usado para esta finalidade. 2 - Compara uma média com a combinação linear de outras ex: µ2 = (µ1 + µ3) / 2. 7- Teste SNK (Student-Newman-Keuls): semelhante ao teste t de Student para 3 ou mais amostras.
Ajusta o valor de t de acordo com as distâncias entre as médias ordenadas das amostras. O teste SNK é mais rigoroso do que o Teste t de Student (usado para comparar 2 amostras).
8- Teste de Games-Howell: tamanhos pequenos e variâncias heterocedásticas, mais potente (pouco Erro tipo II). 9- Teste de Hochberg GT2: muitas amostras, tamanhos diferentes e variâncias homocedásticas.
Na dúvida sobre homocesdásticidade / heterocedásticidade das variâncias, faça antes o teste de Levene.
10- Teste de Gabriel: muitas amostras com tamanhos semelhantes - mais potente.
H0: H1 é falsa. H1: A diferença das medianas entre os grupos é significativa se P < 0,05. H0: H1 é falsa. H1: A diferença das proporções entre as categorias é significativa se P < 0,05. 1- Teste de Wilcoxon para uma amostra, intervalar, Stat T, testa Md por postos, mais potente que o dos sinais...
≡Teste paramétrico Z e t de Student para comparar a X̅ da amostra com a µ da População.
§Teste de Wilcoxon para amostras aleatórias pareadas e independentes. H1: A Md da amostra = Md da população. H1: H0 é falsa. α = 0,05. Wilcoxon Signed-Rank Test; Teste de Postos com Sinais de Wilcoxon para uma mediana; Teste de Postos com Sinais de Wilcoxon para uma mediana (Wilcoxon signed rank) baseado nos postos (ranks = categoria) dos valores obtidos. Postos são as posições, representados por números que os valores ocupam quando colocados em ordem crescente. 2- Teste dos sinais para a mediana de uma amostra, ordinal, Stat P ~ B, testa a mediana por postos...
§Teste dos sinais para 2 amostras (pareadas e independentes).
A: Bilateral H0: M=M0 H1: M≠M0; x é o número de vezes que o sinal (de mais ou de menos) menos freqüente ocorreu. B: Unilateral H0: M≥M0 H1: M>M0; x é o número de vezes que o sinal de menos ocorreu. C: Unilateral H0: M≥M0 H1: M<M0; x é o número de vezes que o sinal de mais ocorreu. 3- Teste do χ2 para uma amostra, nominal, Stat χ2
Para p=0,5 use IC[95%] de eventos favoráveis = (n ± (n*Χ2(1,α))^0,5)/2 Observe que o limite mínimo é 40,2 e o máximo é 59,8, portanto o IC[95%] dos eventos favoráveis = 41 a 59. Uma moeda foi jogada 100 vezes e caiu 50 vezes cara (K). Ela está balanceada para um α = 0,05?
H0: H1 é falsa. H1: p(K) ≠ 0,5. Χ2c(1;0,025) = 3,84, IC[95%] = n ± (3,84n)^0,5)/2. Sim, e a reposta será a mesma para: IC[95%] = 41 a 59 caras. H0: A frequência observada do evento na amostra é igual à frequência esperada. H1: H0 é falsa...
É um teste que abrange o Binomial e, portanto, pode ser usado tanto para variáveis dicotômicas quanto politômicas. O Teste de aderência ao Χ2 é usado para compara se um conjunto qualquer de dados se aproxima ou não da frequência esperada de uma determinada distribuição.
No Teste de adesão ao χ2 ou de aderência ("goodnes of fit" ou bondade do ajuste) à distribuição χ2 só se observa uma amostra (ex: cara/coroa que %é uma variável nominal dicotômica), o outro a amostra é calculado de acordo com uma probabilidade pré-definida, que gera a frequência da amostra esperada. Ele mede quanto os valores observados se desviam dos valores esperados. Uma distribuição tem aderência ao Qui-Quadrado se: 1º Não existirem mais de 20% de categorias com valores esperados inferiores a 5 e, 2º Todas as categorias têm valores esperados superiores ou iguais a 1. H0: A frequência observada segue a padrão de uma moeda balanceada. p(K) = 0,5 A Tabela 2x1 é para TESTE DE ADERÊNCIA À UM VALOR ESPERADO, como no lançamento de moeda. . H1: H0 é falsa.A tabela 2x2 é para TESTE DE INDEPENDÊNCIA ENTRE 2 VARIÁVEIS, como no lançamento de moeda x dado. H0: A Proporção de votos entre os dois canditatos é igual. p(votos) = 0,5 CUIDADO: Este é o teste de Aderência (tabela 2x1), não o de Independência (tabela 2x2) do qui-quadrado.
H1: H0 é falsa.H0: A frequência observada segue a segue a distribuição de Poisson. H1: H0 é falsa.
B. 2 grupos (nominal dicotômico) pareados: Teste χ2 de McNemar, T+ de Wilcoxon...
1- Teste de Wilcoxon pareado, ordinal, Stat T, testa Δpar em relação à Md, muito usado na Psicologia...
≡95% da eficiência do Teste paramétrico t de Student pareado.
H0: As duas amostras têm medianas iguais. H1: H0 é falsa. α = 0,05. Teste de Postos com Sinais de Wilcoxon para amostras combinadas; Teste de Postos com Sinais de Wilcoxon para Pares Combinados; Wilcoxon Matched-Paris Signed-Ranke T. É uma extensão do teste dos sinais para amostras pareadas. É o teste de sinais com verificação da magnitude da diferença entre os pares, e não somente qual deles é maior (ou menor). Se a distribuição da população for simétrica devemos usar o teste de Wilcoxon. Relativamente ao teste do sinal, o teste de Wilcoxon tem a vantagem de ser mais potente, i.e., é menor a probabilidade de se cometer o erro de aceitar H0 sendo H0 falsa. Somente é aplicado em amostras não paramétricas (determinadas pelo teste de distância K-S). Exige um tamanho de amostra maior do que o teste t pareado. Ex: comparando os escores de paciente na entrada na UTI e no dia do início da alimentação parenteral. Uma amostra A1 submetida a um tratamento T1, e o seu efeito medido. Posteriormente, essa mesma amostra, chamada agora de A2, é submetida a um segundo tratamento T2, medindo-se o seu efeito pela mesma variável usada no primeiro tratamento. Comparando-se o efeito dos dois tratamentos em cada elemento da amostra, podem ocorrer 3 alternativas: H1: O efeito aumentou; H1: O efeito diminuiu; c) O efeito permaneceu o mesmo (=). Até este ponto, o teste seria idêntico ao chamado teste dos sinais. A diferença porém é que, no teste de Wilcoxon, leva-se em conta a magnitude do aumento ou da diminuição, e não apenas a direção da variação para mais ou para menos. Assim, para cada par vinculado A1/A2, calcula-se a diferença numérica T1 - T2. Essa diferença poderá ser positiva, negativa, ou igual a zero (quando não houver variação, sendo T1 = T2). Uma vez calculadas todas as diferenças entre os valores obtidos para cada par de dados, essas diferenças são ordenadas pelo seu valor absoluto (sem considerar o sinal), substituindo-se então os valores originais pelo posto que ocupam na escala ordenada. Feito isso, atribui-se a cada um desses novos valores dos dados o mesmo sinal que eles tinham antes da transformação em postos. A filosofia do teste presume que, se os tratamentos forem idênticos, a soma dos postos com sinais positivos será equivalente à soma dos postos com sinais negativos. O teste de Wilcoxon calcula um valor z, ao qual está associada um valor de probabilidade. Essa probabilidade traduz o grau de possibilidade de ocorrência desse valor de z por mero acaso, e não por efeito dos tratamentos efetuados (T1 = T2). No caso do GMC software, o programa já faz automaticamente o cálculo da probabilidade do z obtido pelo teste, não havendo necessidade de consultar qualquer tabela. Análise Não-paramétricas que executa o teste de Wilcoxon para modelos em que a variável independente possua somente 2 (dois) níveis. 2- Teste de McNemar
§Teste Q de Cochran (no RealStatistics substitui o McMemar) para 3 ou mais grupos pareados (é a ANOVA das nominais dicotômicas). ≡Teste t pareado que pode ser subistituído pela ANOVA!). Usar a correção de continuidade de Yates para n pequeno E não usar se a soma dos 2 grupos < 25.
Hipóteses: H0: Não existe diferença antes e depois do tratamento. H1: H0 é falsa. α = 0,05. Ou teste de McNemar para a Significância de Mudanças. É o teste de sinais aplicado a 2 amostras com variável nominal dicotômica. Uma amostra A1 submetida a um tratamento T1, e o seu efeito medido. Posteriormente, essa mesma amostra, chamada agora de A2, é submetida a um segundo tratamento T2, medindo-se o seu efeito pela mesma variável usada no primeiro tratamento. Comparando-se o efeito dos dois tratamentos em cada elemento da amostra, podem ocorrer 4 alternativas: a) Foi positivo em A1 e A2 : T1+ e T2+ ; b) Foi negativo em A1- e A2- : T1- e T2- c) Foi negativo em A1 e positivo em A2 : T1- e T2+ d) Foi positivo em A2 e negativo em A1 : T1+ e T2- Calculando-se a frequência em cada uma das 4 alternativas, constrói-se uma tabela de contingência 2 x 2 (ou de dupla entrada). A decisão estatística é dada por um teste do χ2 de McNeamar, não de Pearson!, cujo resultado dirá se a distribuição de frequências encontrada pode ser considerada puramente casual, ou se as diferenças de frequência devem ser atribuídas realmente ao tratamento realizado. 3- Teste de Walsh, intervalar, Stat H, média ≈ mediana.
≡63% da eficiência do Teste paramétrico t de Student.
H0: A frequência dos sinais entre os pares é zero. H1: A frequência do sinal (+) do grupo A é maior que a do grupo B. α = 0,05. Uma amostra A1 submetida a um tratamento T1, e o seu efeito medido. Posteriormente, essa mesma amostra, chamada agora de A2, é submetida a um segundo tratamento T2, medindo-se o seu efeito pela mesma variável usada no primeiro tratamento. Os dados serão codificados apenas como 1 ou 0, para os valores maior e menor de cada par. O valor real do dado não afeta o teste. A decisão estatística envolve o cálculo binomial da probabilidade de os sinais + e - terem aquelas frequências por mero acaso. C. 2 grupos (nominal dicotômico) independentes: Teste de Mann-Whitney...
1- Teste de Mann-Whitney, intervalar, Stat U, testa Medianas, mais potente que o K-S (menor o Erro β)...
≡Teste paramétrico t de Student não-pareado.
H0: As amostras A e B são da mesma população. H1: H0 é falsa. Teste de Wilcoxon rank sum; Teste de Wilcoxon-Mann-Whitney; Teste U de Mann-Whitney-Wilcoxon. 1- Somente é aplicado em amostras não paramétricas (determinadas pelo teste de distância K-S). 2- Exige um tamanho de amostra maior do que o teste t não pareado. Se 2 amostras forem amostradas ao acaso de uma mesma população (variável), a ordenação crescente e conjunta dos dados das 2 amostras tende a misturá-los uniformemente e isto faz com que os dados se encaixem de maneira equitativa, tal como se intercalam os números pares e ímpares na sequência natural dos números reais. 2- Teste do χ2 para duas amostras categorizadas, nominal, Stat χ2, n≥5.
http://www.amendes.uac.pt/monograf/monograf01estatNparamt.pdf
3- Teste de Kolmogorov-Smirnov (K-S) para duas amostras, ordinal, Stat D, testa proporções...
≡Teste t de Student, embora menos eficiente, tem menos restrições já que usa apenas com as ordens das duas variáveis.
4- Teste da Soma dos Postos com Sinais de Wilcoxon, ordinal, testa medianas.
≡95% da eficiência do Teste paramétrico T de Student não-pareado.
≡Teste U de Mann-Whitney. Teste de Postos com Sinais de Wilcoxon para duas amostras independentes. O teste da mediana visa a verificar se 2 amostras diferem em relação às suas tendências centrais, uma vez que a mediana e o valor que marca o centro da distribuição amostral. Como a hipótese deseja testar a probabilidade de ocorrência de uma situação mais extrema, devemos calcular as probabilidades referentes as freqüências observadas e das demais situações extremas, assim como no Teste exato de Fisher. Assim, o teste exige que as amostras possam ser pelo menos passíveis de uma ordenação por valores ascendentes dos dados, para que se possa calcular o valor que divide o conjunto de dados das amostras reunidas exatamente ao meio, ou seja, com 50% dos dados acima e 50% abaixo desse valor. Esse valor é a mediana. A filosofia do teste admite que, se duas amostras provêm de uma mesma população (isto é, se são estatisticamente iguais), a mediana do conjunto de dados reunidos não difere significantemente da mediana de cada uma delas considerada isoladamente. O teste é, no final, um teste do χ2 em que as frequências comparadas se referem ao número de dados em cada uma das amostras comparadas que se encontram acima ou abaixo da mediana comum, calculada para o conjunto das amostras reunidas. 5- Teste de interações de Wald-Wolfowitz, ordinal. 6- Teste de Moses para reações extremas, ordinal.
Este teste se aplica em situações em que existe uma suspeita de que uma determinada condição experimental afetou de certa forma uma amostra de indivíduos, e de forma oposta, a outra amostra. Explicando de outra forma, imagine a ordenação dos dados observados das amostras controle (C) e experimental (E). Suspeita-se então que os valores E se encontram concentrados em uma (ou ambas) extremidade(s) da série.<
D. 3 ou mais grupos pareadas: Teste de Cochran, Friedman com fator duplo...
1- Teste de Friedman com fator duplo com repetições, ordinal, Stat χ2r ~ χ2, ⇒ Teste post hoc de Dunn...
Análise de variância de dupla classificação por postos.
H0: As distribuições são as mesmas em todas as medidas repetidas e a estatística do teste é um χ2 com (número de medidas repetidas - 1) grau de liberdade. Compara amostras n<15, variável quantitativa ou ordinal em 3 ou mais tempos diferentes. O teste de Friedman é uma espécie de análise de variância a dois critérios de variação, para dados amostrais vinculados. Por exemplo: a superfície de corpos-de-prova construídos com diversos tipos de materiais poderia ser avaliada sucessivamente por dois ou mais métodos diferentes. Nesse caso, os dois critérios de variação seriam: 1) os métodos de avaliação; e 2) os materiais utilizados. as amostras são vinculadas porque as avaliações se fazem na mesma superfície de cada corpo-de-prova. O teste responde a este tipo de pergunta: seria idêntica a avaliação da superfície pelos vários métodos, em relação aos diversos materiais? Ou então: responderiam os materiais igualmente aos diversos métodos de avaliação? Ou ainda: haveria concordância entre os diversos métodos em relação à avaliação da superfície dos corpos-de-prova? A resposta do teste depende de qual dos fatores esteja colocado nas colunas de uma tabela de dados com k colunas e n linhas. Desse modo, a organização da tabela de dados é muito importante, uma vez que depende dela a interpretação do resultado do teste. O fator comparado principal deve ser colocado nas colunas, e os dados serão introduzidos no sentido das linhas da tabela. O teste de Friedman não utiliza os dados numéricos diretamente, mas sim os postos ocupados por eles, após a ordenação por valores ascendentes desses dados. A ordenação numérica é feita separadamente em cada uma das amostras, e não em conjunto. A filosofia do teste considera que, se as diversas amostras provêm de uma mesma população, isto é, se elas são estatisticamente iguais (hipótese de nulidade, ou de (H0), a distribuição dos postos nas diversas colunas será mais ou menos equivalente, de modo que a soma dos postos em cada coluna será aproximadamente igual. A hipótese alternativa (H1) seria de que as amostras não pertenceriam à mesma população, isto é, seriam diferentes e nesse caso haveria diferenças entre as somas das diversas colunas. 2- Teste de Cochran, nominal, Stat Q ~ χ2, o post hoc é o teste de McNemar (mas não deveria ser!).
1.4- Regressão linear múltipla interativa completa (22n-1)
É o teste de McNemar generalizado.
Hipóteses: H0: A proporção p é igual em todas as amostras emparelhadas. H1: H0 é falsa. Cochrans Q Test is a non-parametric test for ANOVA with repeated measures where the dependent variable is dichotomous. O teste procura responder a perguntas do tipo: Os resultados dos diversos métodos de julgamento testados seriam equivalentes? Os (n) elementos de uma mesma amostra (A) são julgados segundo (k) padrões ou métodos diferentes de avaliação (P1,P2,P3,...Pk). Os dados experimentais devem apresentar-se como respostas do tipo (+/-), (Sim/Não), ou (Positivo/Negativo). Os dados amostrais (reduzidos a 0 e 1) devem ser reunidos em uma tabela com (n) linhas e (k) colunas. A filosofia do teste considera que, se os diversos métodos produzem efeitos semelhantes sobre os elementos que compõem a amostra, a distribuição dos 1 e 0 nos vários métodos comparados será aproximadamente igual (a não ser pelas variações aleatóias). Torna-se possível, assim, definir se a proporção (ou frequência) de respostas é a mesma em cada uma das (k) colunas comparadas, ou se, pelo contrário, houve influência sobre ela dos métodos ou dos padrões de julgamento utilizados para avaliá-las. O teste é, fundamentalmente, o teste do χ2, para (k-1) graus de liberdade.
3- Teste de de Kendall, coeficiente de concordância W de Kendall...
3- Teste de homogeneidade de Marginais
É uma extensão do Teste de McNemar para variáveis ordinais e faz praticamente o mesmo que o teste de Wilcoxon pareado.
E. 3 ou mais grupos independentes: Teste de Kruskal-Wallis, χ2 para K grupos one-way...
1- Teste da ANOVA nâo-paramétrica de Kruskal-Wallis (KW) fator únicoNew table & graph: Grouped. Bug no SPSS.v20: Duplo click na tab, vai em campos e escolha uma linha tab significativa, na visualização aparece a comparação de pares! , ordinal, Stat H ~ χ2, ⇒ Post hoc de Dunn...
≡95% da eficiência da Análise de variância ANOVA one-way (Teste F); Dunn's test would help analyze the specific sample pairs for stochastic dominance.
Análise de variância de uma classificação por postos. Análise de variância pelos números de ordem (ranks) e não há suposições de Normalidade ou Homocedasticidade. No lugar das medidas, utiliza-se os postos que eles ocupam numa série de dados ordenados por valores crescentes, série essa que reúne num só conjunto os dados de todas as amostras que vão ser comparadas. Os dados são introduzidos amostra após amostra. Se as k amostras comparadas provierem da mesma população (amostras iguais), a média dos postos correspondentes a cada amostra será aproximadamente igual. Embora o teste tenha sido idealizado para testar um único fator de variação, parece viável utilizá-lo também em casos de mais de um critério de variação, desde que se faça a análise de um deles de cada vez, reunindo em amostras todos os dados que tenham em comum esse fator, considerando os demais como simples repetições. Do SPSS: Dunn's test- comparações de pares usando a abordagem Dunn-Bonferroni são gerados para os grupos nas quais o teste de Kruskal-Wallis é significativa. 2- Teste do χ2 para k amostras one way, nominal, Stat χ2, se a variável for intervalar® categorize...
Cuidado com as Regras de Cochran (Regras de restrições para χ2 de grau de liberdade = 1)
H0: A amostra segue o equilíbrio Hardy-Weinberg. p(AA) = ¼ , P(Aa) = ½ e P(aa) = ¼. H1: H0 é falsa. H0: A frequência observada segue a distribuição probabilistica de Mendel. H1: H0 é falsa.
3- Extensão do Teste da mediana (para k amostras), ordinal, testa medianas.
O teste da mediana visa a verificar se duas ou mais (k) amostras diferem em relação à mediana (valor que marca o centro da distribuição amostral).
Assim, o teste exige que as amostras possam ser pelo menos passíveis de uma ordenação por valores ascendentes dos dados, para que se possa calcular o valor que divide o conjunto de dados das amostras reunidas exatamente ao meio, ou seja, com 50 % dos dados acima e 50 % abaixo desse valor. Esse valor é a mediana. O teste é, no final, um teste de χ2 em que as frequências comparadas se referem ao número de dados em cada uma das amostras comparadas que se encontram acima ou abaixo da mediana comum, calculada para o conjunto das amostras reunidas. 4- Teste de Nemenyi You begin by inserting a 1 and -1 in cells G3 and G4 to compare the New and Old groups. , ordinal, Stat q, testa medianas.
O Teste de NemenyiDamicoWolfeDunn é uma espécie de análise de variância não-paramétrica, para um fator único de variação, que faz comparações entre várias amostras independentes. O fator de variação estudado é colocado nas colunas, com as repetições dispostas verticalmente, ao longo das colunas. Os dados são introduzidos no computador seguindo o sentido vertical da tabela, repetição após repetição, e não no sentido horizontal. Os dados de todas as amostras são ordenados por valores crescentes, sendo os valores originais substituídos pelo número de ordem ocupado por eles na série do conjunto ordenado. Em caso de empates, faz-se a média dos postos correspondentes, e se atribui esse mesmo valor a todos os dados empatados. Se as amostras pertencerem à mesma população, isto é, se forem iguais as médias dos seus postos serão mais ou menos iguais. A avaliação estatística é feita pela comparação dessas médias.
H0: H1 é falsa. H1: Existe uma Equação linear ou logística simples cuja variável (X) prevê significativamente (P < α) o valor da variável desfecho (Y) com uma determinada porcentagem mínima de acerto (r2). Nesta etapa o que interessa são os coeficientes (parâmetros) da equação. explica a forma e a Análise de correlaçãoO termo correlação (r) significa relação em dois sentidos (co+relação) e é usado em estatística para designar a força que mantém unidos dois conjuntos de valores (X,Y). O de determinação (r2 é a proporção de variação total da variável dependente Y que é explicada pela variação da variável independente X. quantifica a força da relação."As medidas do grau de relacionamento entre duas ou mais variáveis quantitativas são chamadas coeficiente de correlação (=covariância/DP) ou coeficiente de associação para variáveis qualitativas. Padronize as unidades (diferentes) com Z-score! Os pressupostos para o uso da Regressão Linear Simples são: HILE Gauss! Pronounced highly Gauss. Portanto, determinar os coeficientes (parâmetros) da função Linear é apenas o começo... a Análise dos resíduos é mandatória! Exogenidade estrita, significa que as variáveis preditoras podem ser tratadas como valores fixos, em vez de variáveis "aleatórias", ou seja, as variáveis preditoras deverão ser assumidas como isentas de erro, não estando contaminadas com erros de amostragem.
1º) n ≥ 50 + 8*nro de preditoras, 2º) A variável preditora tem Exogenidade estrita (valores fixos, não aleatórios), 3º) Linearidade: Y = a+bx, se o coef. angular b (Teste t) e o de correlação Cuidado p'ra não confundir o coeficiente do correlação r de Pearson com a Matriz de correlação das preditoras. linear r ≈ |1| forem significativos (P<α),
4º) A Análise dos resíduos mostra: Normalidade (Teste W) e Homocedásticidade (Teste F).
1- Regressão linear simples
O pesquisador não sabe, mas além da massa (r2 = 30%), há mais 2 variáveis (altura e idade) que "fechariam" o modelo de consumo de Energia (adulto, masculino) com P < 0,01... , intervalares, Stat t, Y ~ f(x) = a+bx+ε, onde, ε ~ NID(0; σ2), coef. de correlação...
Há relação estatísticamente significativa entre X e Y?. A mais famosa é a Regressão que determina 0ºK. Um pressuposto no uso da Análise da regressão linear é que a haja evidências de Linearidade nos parâmetros. Em outras palavras, o adjetivo "linear" é usado para indicar que o modelo é linear nos parâmetros b1,..., bk e não porque Y seja função linear dos Xs. Tem ainda o problema dos coeficientes padronizados.
1- Médodo de ajuste (estimativa) dos parâmetros do modelo (cálculo dos coeficientes 'a' e 'b')...
1.1- No caso em que as duas variáveis (preditiva e preditora) são contínuas. Nota: y = a + b*x, onde os coeficientes (parâmetros) a é o de intersecção e b é o de inclinação, angular ou de regressão. O pressuposto deste modelo de regressão é de que os erros (resíduos, desvios, ruídos ou componente aleatório) são independentes e variam aleatoriamente segundo uma distribuição (de probabilidade) Normal com média e covariância zero e variância constante.
1.2- Método da máxima verossimilhança - Consiste em determinar uma função, chamada função de verossimilhança [L(y,Md)],que é a função de probabilidade de ocorrência daquele específico conjunto de dados e estimar os parâmetros que maximizam a mesma. 2- Medidas de correlação: Coeficiente de correlação 'r' de Pearson, Coeficiente de determinação r2...
2.1- Coeficiente de correlação 'r' de Pearson
Dica: se acostume com o uso da matriz de correlação (Análise de dados) , coeficiente de correlação de Pearson, coeficiente de correlação linear de Pearson, coeficiente de correlação paramétrico de Pearson ou coeficiente de correlação produto-momento (-1 ≤ (correlação negativa) r ≤ 1 (correlação positiva)) r = 0 indica ausência de correlação, é uma medida do grau de relação linear entre duas variáveis quantitativas. A significância do coeficiente 'r' de Pearson: H0: r = 0. H1: H0 é falsa. 1º- Determinar t = r*RAIZ[(n-2) / (1 - r2)]. 2º- Deterninar tc = t(α; gl), onde α = 0,05 e gl = n - 1 - variáveis independentes. 3º- Se Stat t > tc, então P < 0,05.
2.2- Coeficiente de determinação r2: Indica quanto da variação total é comum aos elementos que constituem os pares analisados, portanto, a qualidade da regressão é indicada por este coeficiente. r2 = Variação explicada de Y / Variação total de Y. É importante notar que r2 varia entre 0 (zero) e 1 (um), e, quanto mais próximo da 1, maior a validade da regressão. Exemplo: r2 = 0,296, explica 29,6% da variação da variável dependente, o restante, 70,4%, é explicado por variáveis não estudadas. ATENÇÃO: r2 NÃO é uma medida apropriada para avaliar a linearidade do modelo. O r2 ajustado, corrige o valor do coeficiente de determinação r2 levando em conta inclusive, o número de preditoras, já que qualquer adição de uma varíável expúria SEMPRE aumenta o r2. 4- Análise dos resíduos: Gráficos e Teste de Durbin-Watson...
Na análise de regressão linear os erros E1, E2, ..., En são as diferenças entre o valor observado e o estimado calculado pela equação. O Objetivo da Análise dos resíduos é detectar violações nos seguintes pressupostos:
1º- seguem uma distribuição Normal - Avaliação: Teste de Kolmogorov-Smirnov, Teste da Normalidade de Lilliefors ou uso de gráfico de probabilidade normal (Normal P-P Plot ou Normal Q-Q Plot) onde se os erros tiverem distribuição Normal, os pontos devem posicionarem-se quase numa reta. Alternativa: ANOVA não-paramétrica; 2º- têm média zero e variância semelhantes (homocedasticidade) - Avaliação: Teste de Levene, Teste de Brown Forsythe, Teste de Bartlett ou uso de gráfico de probabilidade Normal; 4º- os resíduos também são independentes independentes - Avaliação: Teste de Durbin-Watson para a medida da autocorrelação (dependência) nos resíduos de uma regressão: 1º- Valores próximo de 0: existe uma autocorrelação positiva. 2º- Valores próximo de 2: não existe autocorrelação dos resíduos. 3º- Valores próximo de 4: existe uma autocorrelação negativa. 2- Regressão linear simples com BC[95%] ATENÇÃO: As bandas de confiança delimitam a área que contém a verdadeira reta de regressão é, portanto, diferente das Bandas de predição (Prediction bands), que delimitam os valores amostrais. As Bandas correspondem a IC da média e as Predições do IC dos valores. , Stat t, p'ra se determinar a banda de predição dos valores.
1- Regressão Logística nominal simples
http://statpages.info/logistic.html. É nominal por causa do out(Y)come!!! , Stat WaldO teste de Wald frequentemente falha em rejeitar coeficientes que são estatisticamente significativos, aconselha-se que estes coeficientes não significativos sejam testados novamente pelo teste da razão de verossimilhança. , Stat TRV, X ~ p(x) = 1/(1 + e-(α + βx)), e ≅ 2,72, Odds = eβ...
É possível que a palavra Logística se refira não ao Log da função, mas a variável desfecho nominal dicotômica, ou, lógica (sim ou não)!
A Resultados na "unha" (modelo logístico ou classificador de máxima entropia??????
Quando uma ou as duas são categóricas temos que transformá-las. Quando a variável independente categórica é nominal, ela pode ter mais de duas classes e para isso cria-se variáveis codificadas chamadas de variáveis dummies.
) é um modelo estatístico que permite calcular o valor de uma variável desfecho (outcome), a partir de uma variável preditora contínua ou binária. Os princípios são: 1- A variável dependente está limitada a dois resultados possíveis (binária ou dicotômica, mas pode ser estendido para 3 ou mais classes como alta, média ou normal e baixa). 2- Só se deve incluir as variáveis independentes relevantes. 3- Há um mínimo de 30 casos por variável independente. 4- Há o risco de se criar um modelo instável se duas ou mais variáveis independentes medirem um mesmo efeito (o modelo papoca...).
Problemas quando a variável resposta é binária 1. Os erros não tem distribuição normal. 2. Variâncias heterogêneas. 3. Restrição na função resposta. 2- Medidas de associação: Na Regressão Logística o coeficiente β estimaça diretamente o Odds (chance) = e β. 3- As 3 funções (transformações) utilizadas na modelagem de dados cuja variável é binária são: 3.1- Transformação logit - é relacionada com a propriedade que a função logística ser linearizada e a variável dependente pode ser associada a uma variável aleatória de Bernoulli. 3.2- Transformação probit - obtida transformando E(Y) por meio da distribuição normal acumulada e limitado a apenas uma variável preditora. 3.3- Complemento log-log - Diferentemente das transformações logit e probit, esta transformação não é simétrica em torno de E(Y) = 0,5. 3.3- Complemento log-linear - Quando a variável dependente é associada a uma variável aleatória de Poisson. 4- Usos da função logística 4.1- Descritivo: descrever a natureza do relacionamento entre a resposta média (isto é, a probabilidade de comprar, por exemplo) e uma (ou mais) variáveis regressoras. 4.2- Preditivo: saber se uma pessoa irá comprar um automóvel no próximo ano, dado o seu rendimento. 3.2- Significância dos parâmetros a e b: Teste de Wald, Razão de verossimilhança... H0: b = 0, ou seja, a reta de regressão é paralela ao eixo da abscissa. H1: b ≠ 0, ou seja, H0 é falsa. 3.2.1- Teste de Wald: Pressupõe que X tenha distribuição normal. Algoritmo: 1º - Calcular b e o erro padrão de b, 2º- Calcular o Stat t = b/erro padrão de b, 3ª- Calcular os gl = n-2 onde n é o número de pares (x,y), 4º- Localizar o valor de t na tabela t, e, 5º se t ≤ tc aceite H0. Este teste segue a distribuição Normal e frequentemente aceita H0 quando esta é falsa (Erro tipo II) especialmente quando n é pequeno. 3.2.2- Teste da razão de verossimilhança (likelihoold ratio): Este teste recursivo baseado na estatística de Deviance do modelo (função desvio) e é indicado quando o 'n' é pequeno ou moderado ou quando o teste de Wald aceita a H0. O TRV = -2*[log da verossimilhança com a constante - log da verossimilhança sem a constante]. O valor com a constante é obtido no passo interativo 0 e o valor sem a constante no último passo (quando o modelo estabiliza). Este teste segue a distribuição do χ2 com 1 grau de liberdade, portanto se χ2 > 3,84 então P < 0,05. 2- Regressão Logística ordinal simples, use o teste ante hoc do χ2 para tendência linear.
C. Intervalar x intervalar, relação paramétrica mas não-linear
1- Modelos farmacocinéticos de 1ª ordem, tempo x clearance, X ~ E(λ), C(t) = C0e-kt, onde k = -Ln(2)/λ...
Parâmetros: 1- Clearance plasmático. Meia-vida plamática. 3- Volume de distribuição do fármaco.
1.1- Modelo linear aberto de um compartimeto (via de administração endovenosa) Características: 1. Absorção instantânea. 2. Eliminação de primeira ordem. 3. Distribuição instantânea. Modelo matemático: Cpt = Cp0 . e-ke.t (ke = constante de eliminação). 1.2- Modelo linear aberto de um compartimeto (via de administração oral) Características: 1. Absorção lenta. 2. Eliminação de primeira ordem. 3. Distribuição instantânea. Modelo matemático: Cpt = Cp0 . e-ka.t + Cp0 . e-ke.t (ka = constante de absorção). 1.3- Modelo linear aberto de dois compartimeto (via de administração endovenosa) Características: 1. Absorção instantânea. 2. Eliminação de primeira ordem. 3. Distribuição lenta. Modelo matemático: Cpt = (D*F*ka)/(Vd(ka-ke)) * e-ke.t (D= Dose administrada, F = fração absorvida, Vd = volume de distribuição aparente). 2-
Curva Dose-Resposta, log x linear, Stat r2,
Clique para ver as Equações e colar especial como texto no Excel. X ~ DR(S; pD2), E = 1/(1 + S(pD2 - pDx))2.1- A Teoria dos Receptores John Langley (1852-1925), fisiologista britânico, observou que a Nicotina (agonista) age apenas numa pequena área da fibra muscular (junção neuro-muscular) que pode ser bloqueada pelo Curare (antagonista) e, propôs a existência de Substâncias receptivas, hoje Receptores farmacológicos... .
2.2- Modelo hiperbólico de Clark & Ariens Alfred Clark (1885-1941), farmacologista britânico e Everhardus Ariëns (1918-2002), farmacologiasta alemão, contribuiram com o modelo matemático hiperbólico: E = (Em * D)/(Kd + D), da interação droga-receptor (teoria dos receptores). - Não é mais usada devido à dificuldade de se determinar o valor da constante de dissociação (Kd). D= Dose, Em = Efeito máximo.
2.3- Modelo da dupla inversa de Lineweaver & Bury Hans Lineweaver (1907-2009), físico-químico americano e Dean Burk (1904-1988), bioquímico americano, contribuiram com o modelo matemático da dupla inversa: 1/E = Kd/Em * 1/D + 1/Em, da interação droga-receptor (teoria dos receptores). - convenientemente esquecida, quem a utiliza comumente fica constrangido com os valores de kd (constante de dissociação) e de Em (Efeito máximo).
2.4- Modelo do duplo Log de Hill Archibald Hill (1886-1977), *1922, fisiologista inglês, contribuiu com o modelo matemático do duplo Log: Log(Em/E - 1) = -Log(D) + Log(Kd), da interação droga-receptor (teoria dos receptores). - a mais importante, se o coeficiente angular de Hill for estatísticamente diferente de 1, a equação não mais representa a de Ariens.
2.5- Modelo sigmóide Apesar dos dados serem os mesmos, há uma grande discrepância tanto na constante de dissociação de Clark & Ariens quanto no Efeito máximo de Lineweaver & Bury, e isto se deve ao fato de que o coeficiente de Hill ser diferente de 1. - atualmente é a mais usada. Note que a constante hiperbólica S = 10^coef. de Hill representa uma família de curvas hiperbólicas. pDx = -Log(D).
Além disto se pode representar as curvas com Agonistas parciais. 5- Regressão linear-Log A média foi usada para se "centrar" os valores e, NÃO se pode fazer a Regressão Linear em cima dos valores Log, daí a necessidade de convertê-los em lineares. , Stat t
D. Intervalar x intervalar, relação não-paramétrica: Coeficiente de correlação rs de postos de Spearman E. Ordinal x nominal dicotômica, relação não-paramétrica 1- Teste do χ2 de Mantel-Haenszel ou teste do χ2 para tendência linear...
≡91% da eficiência da Regressão linear simples (intervalar x intervalar)
H0: Não existe um relacionamento linear entre as duas variáveis. H1: H0 é falsa. α = 0,05. O Teste de associação linear de Mantel-Haenszel (para 2 amostras independentes) - é um teste de hipótese onde: 1- as amostras são independentes, 2- os itens de cada amostra são selecionados aleatoriamente, 3- as observações devem ser frequências ou contagens, 4- cada observação pertence a uma e somente uma categoria e 5- a amostra deve ser relativamente grande (pelo menos 5 observações em cada célula). 2.3- Coeficiente de correlação rs de Spearman, de postos ou coeficiente ρ (rô), ≡Coeficiente de correlação 'r'. Medida de correlação entre duas variáveis pelo menos ordinais de modo que os elementos em estudo possam ser dispostos por postos em duas séries ordenadas.. É menos sensível do que o de Pearson quando os valores estão muito distantes do esperado. Este coeficiente avalia uma função monótona arbitrária que pode ser a descrição da relação entre duas variáveis, sem fazer nenhuma suposição sobre a distribuição de frequências. 2.4- Coeficiente de correlação por postos de Kendall, t (tau)- 2.4- Coeficiente de correlação parcial por postos de Kendall F. Nominal x nominal, teste não-paramétrico, Odds ratio, Risco relativo, coeficiente de contingência 1- Teste do χ2 de independência de Pearson ou de associação: NÃO CONFUNDA o Teste do χ2 de independência com o χ2 de aderência, este último é para 1 variável dicotômica como é o caso da moeda (cara x não_cara)!!! P(A∩B) = P(A)*P(B), compara proporções...
≠Teste do χ2 de aderência de 1 ou mais amostras à uma frequência esperada (pré-definida), este, é para 2 variáveis.
H0: As duas variável nominal são independentes. H1: H0 é falsa. α = 0,05. Regras de Cochran ou restrições para grau de liberdade = 1: 1) n ≥ 40 (n = número total de observações por casela); 2) 20 ≤ n < 40, o teste só pode ser aplicado se todas as frequências esperadas forem ≥ 5; 3) n < 20 e se a frequência esperada n < 20, usar o teste exato de Fisher. O Teste do χ2 de independência (já que é não-pareado) ou Teste de correlação (A correlação quantifica quão bem o X e Y variam em conjunto, ou seja mede o grau de associação), compara frequências observadas com frequências teóricas (esperadas). O estudo da frequência é feito através de matrizes (tabelas de contingência ou de frequência) e a mais famosa é a 2 x 2. O grau de liberdade é o produto do número do linhas (l) - 1 vezes o número do colunas (c) - 1: (2-1) x (2-1) = 1 x 1 = 1. No caso da 2 x 2, gl = 1 e α = 0,05 o valor crítico do χ2c = 3,841, se o Stat χ2c estiver acima deste valor, rejeita-se H0. Medidas de força (ou intensidade) de associação entre as 2 variáveis nominais (qualitativas) 1- Odds ratio (OR) ou Razão de Chances (RC) ou Razão de produtos cruzados. OR = pacientes com anormalia / pacientes sem anormalia = (a*d) / (c*b) = paciente expostos / paciente não exposto = (a/b) / (c/d) Este índice é usado em Estudos de Caso-Controle e em Coortes. Deve-se também determinar o IC95% de OR. 2- Risco relativo (RR) = Incidência do desfecho entre sujeitos expostos / Incidência do desfecho entre sujeitos não expostos = a/(a+b) / c/(c+d). Este índice só pode ser usado em Coortes, não pode ser usado em Estudos de Caso-Controle. Tem como base a observação empírica de que nem todos têm a mesma probabilidade (risco) de sofrer um desfecho, mas que para algumas (amostra) este risco é maior do que para outros. Grau de Risco é uma classificação do valor do Risco (alto grau de risco, baixo risco, etc). Deve-se determinar o seu IC95% do RR, uma vez que é possível obter um valor do RR alto, mas se o tamanho da amostra for pequeno, o seu valor será duvidoso. 3- Coeficiente de contingência C um indicador do grau de associação entre duas variáveis analisadas pelo Qui quadrado. Quanto mais próximo de 1, melhor o coeficiente de contingência, que varia de 0 a 1. 4- Risco Atribuível (RA) Taxa de Incidência na amostra com o fator de risco menos a Taxa de Incidência na amostra sem o fator de risco É uma medida de associação entre fatores de risco e o desfecho. É definido com a diferença entre a probabilidade ter o desfecho nos que estão expostos ao fator e a probabilidade de ter o desfecho nos que não estão expostos.
5- Fração Atribuível (FA): É a medida do efeito da eliminação do Fator de Risco para determinado desfecho, ou seja, mede o quanto a ocorrência do desfecho pode ser diminuída se o Fator de Risco fosse eliminado. 6- Fração Atribuível Populacional (FAP): É a medida da proporção da incidência do desfecho na população, atribuída à exposição de um determinado fator. 7- Coeficiente de associação Q de Yule Algoritmo de execução: 1º - Montar a tabela de contingência 2x2, 2º- Calcular o valor de Q = (ad - bc) / (ad - bc), 3º- Calcular o desvio padrão (s) de Q: s = ((1 - Q2) / 2) * ((1/a + 1/b + 1/c +1/d)^0,5), 4º- Calcular o IC(95%) = Q ± t*s. 5º- Calcular t = (r/(n-2)^0,5)/((1-r2)0,5). 6º- Se t > tc rejeitar H0. 8- Coeficiente V de Crámer. Apesar de sua popularidade o coeficiente de contingência C tem a desvantagem de que o número de linhas e colunas influencia o resultado. A alternativa é utilizar o coeficiente V (de Cramer), 9- Método de correlação não-paramétricos de Kendall.
2- Teste do χ2 com correção de continuidade de Yates: Só tabela 2x2 (20 ≤ n ≤ 40 e frequências esperadas ≥ 5)
H0: A probabilidade do evento A é independente da de B - P(A∩B) = P(A)*P(B). H1: H0 é falsa.
O Teste do χ2 ou Teste de independência (já que é não-pareado) do χ2, compara frequências observadas com frequências teóricas, calculadas matemáticamente para o mesmo número de dados da amostra. O estudo da frequência é feito através de matrizes (tabelas de contingência ou de frequência) e a mais simples é a 2 x 2 (duas linhas e duas colunas). O grau de liberdade é igual ao produto do número do linhas menos 1 vezes o número do colunas menos 1: (2-1) x (2-1) = 1 x 1 = 1. O teste calcula a relação: quadrado da diferença entre as frequências obtida e esperada em cada uma das quatro células da tabela de contingência (ou de dupla entrada), dividido pela frequência esperada, e soma esses quadrados. No caso da 2 x 2, gl = 1 e α = 0,05 o valor crítico do χ2c = 3,841, se o Stat χ2c estiver acima deste valor, rejeita-se H0. As restrições para 1 grau de liberdade (matriz 2x2) são: 1) pode ser aplicado para n maior que 40 (n = número total de dados); 2) para n entre 20 e 40, o teste só pode ser aplicado se todas as frequências esperadas forem maiores ou iguais a 5; 3) se a menor frequência n < 20, ou se 'n' for menor que 20, será preferível usar o teste exato de Fisher. B. Para mais de 1 grau de liberdade: a) nenhuma casela pode ter valor menor que 1; b) o número de caselas com valores esperados menores do que 5 não pode ultrapassar 20 % do número total de caselas; e c) se isso ocorrer, reformule a tabela (somando caselas vizinhas). 3- Teste exato de Fisher ou Χ2 de 'n' pequeno, ≡Teste paramétrico t de Student não-pareado...
Variáveis: nominal; para n < 20 ou 20 < n < 40 e frequência esperada < 5 ou frequência esperada < 1
O teste exato de Fisher (Probabilidades exatas de Fisher) testa diferenças entre duas variáveis independentes que só admitam duas alternativas como resposta: Sim/Não, Positivo/Negativo, ou +/-. Isso leva à construção de uma tabela de contingência 2 x 2. O teste é basicamente um χ2, particularmente adequado para pequenas amostras (com 20 dados ou menos), caso em que o teste do χ2 estaria contra-indicado, entretanto, quando o número de dados da amostra é grande, o teste de Fisher é que não deve ser usado, porque envolve o cálculo de fatoriais, o que pode conduzir a números excessivamente elevados. Nesses casos, a opção deve ser pelo teste do χ2. 4- Teste do χ2 para k amostras independentes, nominal, Stat χ2, tabela m x n...
Regras de Cochran ou restrições para grau de liberdade > 1:
1- nenhuma casela pode ter valor < 1; 2- o número de caselas com valores esperados < 5 não pode ultrapassar 20% do número total de caselas e, 3- se isso ocorrer, reformule a tabela (somando caselas vizinhas). O teste do χ2 é um teste que compara frequências obtidas experimentalmente com frequências teóricas calculadas matemáticamente, ou seja, compara proporções. A tabela de contingência é formada de (m) linhas e (n) colunas. O grau de liberdade é dado pelo produto de (m-1) x (n-1), quando m E n ≥ 2. O teste calcula a relação: quadrado da diferença entre as frequências obtida e esperada em cada casa da tabela de contingência, dividido pela frequência esperada, e soma esses quadrados. Pode-se determinar ainda (SPSS): 1- Qui-Quadrado de Pearson; 2- Corrigido de Yates ou Correção de Continuidade; 3- Razão de verossimilhança; 4- Teste exato de Fisher; 5- Qui-Quadrado de Mantel-Haenszel ou teste de associação linear ou ainda associação linear por linear. Os Fatores encontrados são formados por variáveis com forte colinearidade (polos gravitacionais). É p'ra casualidade, previsão (Regressão e Redes Neurais) ou otimização (Simplex e Planejamento fatorial) Para entrada das covariáveis (explicativas) no modelo usa-se um α de [0,10:0,25] usando o Teste do χ2 de tendência linear. Cov(X,Y) = 0 ou Covariância nula significa ausência de correlação linear. Corr(X,Y) = Cov(X,Y) / DPX*DPY 6º) Não há colinearidade O VIF (Variance Inflation Factor) é o inverso da tolerância. Valores altos de VIF indicam alto grau de multicolinearidade. , Independentes (Stat d) ou multicolinearidade entre as variáveis preditoras.7º) Pontos outlines eliminados ou pontos aberrantes usando a medida da distância Cook (Di ≤ 1). H1: Existe uma Equação linear ou logística múltipla com variáveis (Xi) que prevêm significativamente (P < α) o valor da variável desfecho (Y) com uma determinada porcentagem mínima de acerto (r2).
A tabela para a Análise Estatística usando o método da Regressão linear múltipla tem um (univariada) ou mais desfechos (multivariada), onde Y1, Y2..., são variáveis intervalares (na logística, normalmente, são binárias) e duas ou mais variáveis independentes, onde X1, X2, X3..., chamadas de covariáveis. O objetivo é determinar os parâmetros (β0, β1, β2, β3...), destas covariáveis. Quando uma variável "independente" é função da outra (colinearidade), ou uma delas é retirada do modelo ou o modelo é multivariado (Regresão multivariada). Seus 2 modelos são:
1.1- Regressão linear múltipla (21 - 1 equações), intervalar, Stat r2, y = b0 + b1*x1 + ... + bn*xn + ε (Obs-Esp)...
1- modelo preditor ou explicativo (roda de macumba com Y no centro): a associação entre a preditora e o desfecho deve ser independente de qualquer variável de interação (X2 modifica a relação entre X1 e Y). 2- modelo causal ou de causalidade (time de futebol, modelos fisiopatológicos, com o Y no final): a associação deve ser independente de variáveis de confusão (X1 modifica X2 e Y). Fazer o ajuste dos dados, ou seja determimnar o efeito de uma variável X, ajustando ou levando em conta outras variáveis independentes. Obter uma equação linear para predizer valores de Y a partir dos valores de várias variáveis X1, X2, ...,Xk. Explorar as relações entre múltiplas variáveis ( X1, X2, ..., Xk ) para determinar que variáveis influenciam Y. 3- Significância estatística: Coeficiente de correlação 'r', ANOVA e para os parâmetros 'a' e 'b'... 3.1- ANOVA 3.1.1- A variável contínua é Normal e NÃO HÁ covariadas para serem controladas: ANOVA - two-way 3.1.2- A variável contínua é Normal e HÁ covariadas para serem controladas: Análise de covariância...
A análise da covariância é assim denominada quando se procede a análise da variância simultaneamente para duas ou mais variáveis. Geralmente, como resultado de um experimento, têm-se uma variável (Y) dependente principal e uma ou mais variáveis (X1,X2,...) independentes denominadas de covariáveis.
3.1.3- A variável contínua NÃO é Normal, n > 5, não-pareado: ANOVA não-paramétrica de Kruskal-Wallis. O objetivo da análise de regressão linear múltipla, assim como de todos os tipos de regressão, é encontrar uma equação (chamada de equação de regressão, variável estatística de regressão ou modelo de regressão) que prevê a variável resposta (outcome, desfecho) a partir de uma combinação das variáveis explicativas.
1.2- Regressão linear múltipla completa (2n-1): y = b0 + ∑ni bi*xi + ∑ni+1 bi,i+1*xi,i+1 + ... + ∑ni+1,...,n ...,n
1.3- Regressão linear múltipla interativa simples (2n-1)Na Regressão linear interativa, o #monômios é (2n-1) e os expoentes de cada variável de cada monômios = 1. : y = b0 + ∑ni bi*x1i + ∑ni+1 bi,i+1*x1i,i+1 + ... + ∑ni+1,...,n ...,nNa Regressão linear interativa plena, o #monômios é (22n-1) e os expoentes de cada variável de cada monômios = 1. : y = b0 + ∑ni bi*x1i + ... + ∑ni+1,...,n ...,n
Na Regressão linear múltipla interativa o número de monômios = 2n No Excel 2007 o máximo de monômios é 16.384 (equivale a processar apenas 13 variáveis "cheias"). (onde n = #variáveis e incluindo b0) e as 'n' camadas de interações (= #variáveis) se distribuem de acordo com as linhas do Triângulo de PascalBlaise Pascal (1623-1662), matemático francês, estudou as propriedades de um triângulo numérico infinito formado por números binomiais. Ex: n = 7, k = 3, o número de monômios 35, i.é, a parcela com maior número de monômios é quando k = n/2. Ele pode ter sido "inspirado" pelos números "triangulares" de Pitágoras. .
1.5- Regressão linear multivariada, intervalar, várias variáveis dependentes (variada) simultâneas.
B. A variável desfecho é intervalar e as preditoras são categóricas com Y ~ N(Yxi, XY/Xi)
2.3- Algoritmo hierárquico, há uma estratégia prévia (modelo biológico) para a sequência de entrada das preditoras...
1- ANCOVA
www.ufpr.br/~aanjos/CE213/ancova.pdf ou Análise de Covariância, Stat F, desfecho numérico e preditores categóricos/numéricos...
A covariável tem que estar correlacionada com a variável resposta para que se possa fazer uso da ANCOVA. como se fosse a média das retas de amostras não-pareadas aos pares...
C. 2 ou mais desfechos: Análises multivariadas (mais de uma variada) com Yi ~ N(Yxi, XY/Xi)
O teste Λ* (lambda) de Wilk é o mais utilizado para testar a hipótese H0 da MANOVA. Outros testes também são utilizados, tais como Pillai, Hotelling-Lawley e o teste de Roy, os quais podem apresentar resultados diferentes para a mesma análise.
D. As variável de desfecho é ordinal, preditoras quaisquer e a incidência (tempo) não é importante
1- Logit ordenada E. A variável desfecho é binária, as preditoras quaisquer e a incidência não é importante 1º- As preditoras são independentes entre si (não devem vir de medições repetidas ou dados correspondentes). 2º- Pouca ou nenhuma multicolinearidade entre as variáveis independentes. 3º- Linearidade entre as variáveis independentes e os log odds. 4º- n grande. Mínimo 10 casos com o resultado menos frequente para cada variável independente. Ex: para 5 preditoras e com probabilidade esperada do menos frequente é 0,10, então o n mínimo = 500 (10 * 5 / 0,10). Regressão Logística múltipla (≥ 2 preditoras) dicotômica ou politômica (>2 classes de desfecho ordinal)...
Pressupostos: 1- ausência de colinearidade, 2- singularidade e ausência de observações aberrantes, 3- Homoscedasticidade, 4- normalidade dos erros e erros independentes, 5- linearidade.
1- Exclusão de estudo de variáveis importantes para a explicação do fenômeno em questão, as quais podem estar correlacionadas com uma variável multicolinear. 1 e 2- No caso da inclusão de variáveis multicolineares ou singulares, perde-se graus de liberdade com diminuição do poder de teste estatístico. 3- a homogeneidade variâncias pode ser reduzida por intermédio da transformação de variáveis que não possuem distribuição normal (e.g., assimetria positiva ou negativa). 4- A violação do pressuposto de normalidade (teorema do limite central) pode ser atenuada por meio do aumento do tamanho da amostra da população pesquisada. Quando o pressuposto da linearidade é violado, deve-se estar ciente de que o modelo de regressão linear não é o melhor modelo explicativo para o estudo das variáveis envolvidas, e que outros modelos (e.g. o quadrático) devem ser utilizados. A qualidade do modelo é avaliada pelo valor do coeficiente de determinação, r2 e da distribuição dos resíduos. Em outras palavras, o R2 é a quantidade da variância da variável dependente que é explicada conjuntamente pela(s) variável(is) independente(s) e é a estatística mais utilizada para interpretar os resultados da regressão. Mediação: No caso do uso da regressão para verificar se o relacionamento entre as variáveis é linear ou não, a RM pode ser empregada na identificação de variáveis mediadoras e moderadoras. O conceito de mediação implica suposição de relacionamentos causais entre as variáveis envolvidas. Uma variável mediadora é aquela que, ao estar presente na equação de regressão, diminui a magnitude do relacionamento entre uma variável antecedente e uma variável dependente ou critério. Para melhor ilustrar a definição de uma variável mediadora, podemos analisar o relacionamento entre três variáveis hipotéticas, sendo a variável B a mediadora do relacionamento de A com C (A -> B -> C). Note-se que a relação entre as variáveis A e C ficará enfraquecida na presença da variável B. No caso de uma variável mediadora pura, o relacionamento entre A e C deixa de existir na presença da variável B. A identificação de variáveis mediadoras pode ser feita, por exemplo, com base na observação dos padrões assumidos pelos pesos b das variáveis envolvidas. No caso de uma variável mediadora pura, tem-se um b significativo de A para C, antes da entrada de B na equação. Contudo, uma vez que B é adicionado à equação, o b de B torna-se significativo, enquanto a significância do b de A desaparece. No caso de uma mediação pura, o B captura totalmente a relação entre A e C. Contudo, quando a mediação não é total, pode ainda existir uma relação entre A e C mesmo na presença de B. Moderação: o conceito de moderação implica influência entre as variáveis e não suposição de causalidade, como no caso da mediação. Para testar a moderação, o pesquisador deve observar a interação entre A e B. Para tal, procurase observar se A é um bom preditor de C. Em caso positivo, verifica-se se A e B predizem C, e se a interação entre A e B, calculada por meio do produto A x B, também prediz C. Caso a interação seja uma preditora estatisticamente significativa de C, diz-se que B é uma variável moderadora. A existência de uma interação entre A e B só é um indicador de moderação quando, adicionada à equação, é preditora do critério. Logo, na moderação, o relacionamento entre A e C depende do valor assumido pela variável B. Vale salientar que, no caso da mediação, a relação entre A e C fica enfraquecida com a entrada de B na equação. No caso do moderador, além da interação A x B tornar-se um preditor significativo, a relação entre A e C poderá aumentar ou diminuir, dependendo do valor de B. Pedhazur (1982) discute detalhadamente a diferença entre moderadores e mediadores. Os trabalhos de Gordon (2000) e Torres (1999) exemplificam o uso da RM na identificação de mediadores e moderadores, respectivamente. O´Connor (1998), comparando testes e programas estatísticos, discutiu detalhadamente procedimentos para identificação de moderadores por meio da regressão múltipla. Redundância: este fenômeno refere-se à entrada de preditores correlacionados positivamente entre si na equação, acarretando perda de parcimônia na explicação de um critério. A redundância pode ser observada quando os pesos b e os Sr2 (i.e., soma das contribuições únicas de cada variável) para cada preditor são menores do que a correlação ivariada entre cada um desses preditores e o critério. Por exemplo, Abbad (1999) identificou redundância em variáveis preditoras que mantinham fortes correlações (0,70 £ r ³ 0,50) com a variável critério e que, ao entrarem na equação de regressão múltipla, resultaram em coeficientes de correlação múltipla muito menores (e.g., bs variando de 0,11 a 0,23 e Sr2s de 0,07 a 0,14). Este fenômeno reflete que cada preditor explica parte da variância do critério que já foi explicada por outro preditor. Nas Ciências Sociais, em geral (Cohen & Cohen, 1975), grande parte das variáveis são correlacionadas entre si. Na Psicologia Organizacional, em particular, este fato se deve ao uso de múltiplas medidas edundantes (Dunlap & Landis, 1998), estratégia esta considerada ecessária para conferir validade de conteúdo e consistência interna aos instrumentos. Complementaridade: refere-se a um padrão pouco freqüente de associação entre preditores e critério, em que a soma da contribuição única de um conjunto de preditores excede a soma das contribuições individuais de cada preditor na explicação do critério. Na complementaridade, dois preditores (x1 e x2) devem ter uma alta correlação negativa entre si (Tabachnick & Fidell, 1996), bem como uma correlação bivariada positiva com a variável critério (Keppel, 1991). Em alguns casos, observa-se um decréscimo no valor do b de x1, podendo o mesmo assumir valores negativos quando a variável x2 entra na equação. Nestes casos, os dois preditores (x1 e x2) são considerados interdependentes ou complementares. A conseqüência da complementaridade é uma diminuição no poder estatístico da pesquisa devido à inclusão de duas variáveis que, juntas, acrescentam pouca explicação à variância do critério e, portanto, representam uma diminuição nos graus de liberdade. Um exemplo de complementaridade pode ser observado na pesquisa de Torres (1999), que utilizava, como preditores da preferência por estilos de liderança (y), as variáveis padrão cultural (x1) e país de origem (x2) dos participantes, medidas por escala intervalar de altitude (x1) e dados categóricos (x2). Torres observou uma correlação negativa (rx1x2 = - 0, 11) entre x1 e x2 e correlações positivas entre x1 e y (rx1y = 0, 22) e entre x2 e y (rx2y = 0,29). Na análise de regressão hierárquica, foi observado um forte decréscimo com inversão de sinal do bx1 depois que a variável x2 entrava na equação (de 0,29 para - 0,61). Neste caso, x1 foi caracterizado como uma variável complementar a x2. Complementaridade, na verdade, é um caso especial do fenômeno de supressão, que será descrito a seguir. Supressão: refere-se à situação na qual uma variável (x1), que mantém uma fraca correlação bivariada com a variável critério (y), entra como preditora na equação de regressão múltipla com um b de sinal oposto ao da correlação bivariada que mantém com y. Trata-se de um fenômeno estatístico raro. A supressão pode ser um sinal de relações complexas entre variáveis preditoras na explicação da variável critério. Esse fenômeno é inicialmente identificado por meio da análise do padrão assumido pelos coeficientes de regressão e de correlação de cada preditor com o critério. Entre os sinais de supressão, deve-se observar, segundo Tabachnick e Fidell, os dois seguintes: (1) o valor absoluto da correlação simples entre as variáveis x1 e y deve ser substancialmente menor que o peso b para a variável supressora x1; e (2) a correlação simples e o peso b dessa variável devem ter sinais opostos. Para Cohen e Cohen (1975), há mais dois indicadores importantes da supressão: (1) a soma das contribuições únicas de cada variável (Sr2) na explicação da variável critério excede o valor assumido por R2; e (2) em alguns casos, o valor de b pode ser maior do que 1. Uma variável supressora é identificada quando se observa que esta variável aumenta a importância de outras variáveis preditoras ao se suprimir parte da variância irrelevante em outros preditores, ou na variável critério (Tabachnick & Fidell, 1996). Um exemplo de supressão pode ser encontrado na pesquisa de Abbad (1999), que investigou o relacionamento entre variáveis organizacionais, características do treinamento, características do treinando, satisfação com treinamento e aprendizagem, com a variável critério impacto do treinamentono trabalho (y). A variável aprendizagem (x1) mantinha uma correlação próxima de zero com o critério (rx1y = 0,002). Na análise de regressão múltipla stepwise, encontrou- se que x1, apesar de não se correlacionar com y, entrou na equação com o peso b de sinal negativo (b = - 0,07), suprimindo a variância de outro(s) preditor(es). Neste caso, observou-se ainda que a soma dos Sr2 era superior ao valor do R2 (Sr2 = 0,94 > R2 = 0,61), caracterizando assim o fenômeno da supressão. 1- Regressão Logística múltipla dicotômica (padrão)
Diferenciar da Regressão Logística Multinomial (Politômica) , desfecho binário, p(x) = 1/(1 + e-( β0 + β1x1 + β2x2 + ... + βkxk))...
Onde βi são os parâmetros do modelo, estimados pelo método de máxima verossimilhança. O primeiro teste de significância importante na regressão logística é o teste da razão de verossimilhança, onde a hipótese de que pelo menos um dos parâmetros βij é diferente de zero (exceto os interceptos parâmetros βi0) é testada.
2- Regressão Logística múltipla dicotômica com algoritmos de pesquisa, estratégia de entrada das preditoras.
É equivalente à Regressão Linear Múltipla para 2 ou mais variáveis preditoras não-paramétricas. Permite que a variável desfecho seja predita a partir de duas ou mais variáveis independentes (covariadas ou determinantes). Antes de iniciar a análise de regressão múltipla deve-se calcular os coeficientes de correlação de todas as variáveis tomadas aos pares. Se houver duas ou mais variáveis com coeficientes de correlação muito altos (r igual ou superior a 0,95) elas interferirão nos cálculos de regressão múltipla, neste caso deve-se escolher apenas uma delas. Exemplo http://www.cultura.ufpa.br/dicas/ - Laboratório de Informática - ICB - UFPA : H1 - Amostra de 36 hansenianos de sexo masculino há correlação entre a quantidade de uma determinada droga presente no sangue 6 hs após a sua ingestão (variável dependente) com a idade (x1), peso corporal (x2), duração da doença (x3), anos de sulfonoterapia (x4), valor do hematócrito (x5), taxa de hemoglobina (x6), nível de globulinas (x7) e nível de albumina (x8). Conclui-se que o nível sanguíneo da droga após 6 hs de ingestão depende apenas da variável x5 pois entre todos os coeficientes de regressão calculados somente o b (-0,2317) dessa variável é significativamente diferente de zero (pois t(27) = -2,340), que determina um P < 0,05.
Regressão stepwise introduz os preditores passo-a-passo no modelo, começando com a variável independente mais correlacionada com y. Depois do primeiro passo, o algoritmo seleciona a amostra de variáveis remanescentes aquela que dá a maior redução na variâncial residual (não-explicada) da variável dependente, i.e. a variável cuja correlação parcial com y é a maior. O programa então executa um teste-F parcial na entrada para checar se a variável absorverá uma quantidade significante da variação em relação aquela removida por variáveis já na regressão. O usuário pode especificar um valor de F mínimo para a inclusão de qualquer variável; o programa avalia se o valor de F obtido em um dado passo satisfaz o mínimo, e se satisfizer, a variável entrará. Similarmente, o programa decide a cada passo se qualquer variável previamente incluída ainda satisfaz um mínimo (também fornecido pelo usuário) e, caso contrário, remove-se tal variável. Em qualquer passo do procedimento, os resultados são os mesmos de como seriam em uma regressão padrão usando-se um conjunto particular de variáveis; portanto, o passo final de uma regressão stepwise mostra os mesmos coeficientes que uma execução normal usando as variáveis que sobreviveram" ao procedimento stepwise.
É um modelo de regressão que permite selecionar as variáveis independentes por ordem decrescente de intensidade de correlação com a variável dependente. matemáticamente se chega à formula do coeficiente de determinação r2, que mede o componente da regressão que decorre da variação concomitante das variáveis estudadas. (Como já foi visto, a expressão 1 - r2 indica o quanto da variância não depende dessas variáveis em estudo). Nessa análise se ordena as variáveis independentes de acordo com o valor de bSP. E, depois desse ordenamento se faz a análise de regressão simples da variável dependente sobre a independente que apresentou o maior valor de bSP. Finalmente,inicia-se a análise de regressão múltipla introduzindo as outras variáveis independentes pela ordem de grandeza decrescente do valor de bSP. Ao final, verifica-se se o acréscimo de r2 é significativo ou não por meio de um teste t : t = (b / sb). A tabela que se segue mostra o resultado da análise de regressão múltipla escalonada aplicada aos mesmos dados que foram usados para a tabela anterior. 2.1- Algoritmo de entrada forçada, forced entry, todas as preditoras entram simultâneamente no modelo. 2.2- Algoritmo de blocos, blockwise ou setwise, preditoras incluidas em blocos com pouca relação entre si...
Visão geral: Logistic Organ Dysfunction System (LODS)
Fluxograma recursivo de análise de bloco onde o nome de cada bloco é um desfecho. Modelo empírico... Vantagem: 1- Pergunta tudo. 2- Não há necessidade de estratégia de análise. Desvantagem: 1- Grande número de variáveis. Entrada: Das centenas de perguntas o PI elege as "mais importantes" para um determinado DESFECHO e solicita a análise estatística. Saída: Lista de variáveis ordenadas usando o método de Regressão logística múltipla. (empirical model)
...diagrama de bloco... Base: Lista de variáveis ordenadas na etapa "Modelo empírico". Vantagem: 1- Organizar as variáveis em bloco, o nome de cada bloco é um DESFECHO. Desvantagem: 1- Bidirecionamento entre os blocos. Entrada: Conjunto de variáveis afins para ser classificadas (ex: situação sócio-econômica). Saída: Variável classificatória "ponte" (modelo SES) que é a única saída de todo o bloco, é a variável DESFECHO auxiliar. Nova análise... (modelo reducionista ou framework)
...modelo clínico epidemiológico... Vantagem: 1- Total de monômios razoável (variáveis independentes e de seus interrelacionamentos, máximo 2n), 2- Criação de um banco de análise "desmontável". Desvantagem: 1- Limitação do número de variáveis. Entrada: Determinar o porcentual de explicação do desfecho (ex:70%) e estabelecer a equação da regressão (deduzida a partir do modelo fisiopatológico). O estatístico calcula os coeficientes e o P. (sistema especialista ou relationships model)
Ao contrário da sequencial, aqui a redundância não é bem vinda, já que ela aumentaria a confiabilidade da predição, por manter no modelo de regressão apenas variáveis não-correlacionadas (ou fracamente correlacionadas) entre si. Nos casos dos estudos
exploratórios, eliminar a variável redundante pertencente a um mesmo construto subjacente pode gerar um efeito indesejável, pois a variável preditora eliminada da equação pode ser uma das mais importantes na explicação da variável latente que prediz o critério.
A regressão hierárquica é utilizada em estudos confirmatórios, uma vez que este tipo de análise busca a explicação sobre o relacionamento entre variáveis descrito em modelos teóricos consistentes, ou seja, em modelos que apresentam um conjunto de proposições empíricas que já indicam a magnitude e direção da relação entre variáveis, mas que, apesar de já terem sido testados, ainda carecem de validação. Neste caso, a ordem de entrada dos preditores na equação de regressão é definida pelo pesquisador, que baseia sua decisão em teorias ou outras pesquisas relacionadas, como, por exemplo, no caso das pesquisas sobre liderança internacional (Torres, 1999). A exemplo do que ocorre com a regressão stepwise, a regressão hierárquica tem o objetivo de determinar os melhores preditores de um critério. Diversos autores, entre os quais Keppel (1991), ao descreverem a regressão hierárquica como forma de se preparar uma path analysis, sugerem que esta regressão é capaz de identificar relações de causalidade entre variáveis. Contudo, é importante lembrar que, como qualquer outra técnica de análise correlacional, a regressão hierárquica não pode identificar causalidade, mas apenas a relação (ou correlação) entre variáveis. Mesmo quando utilizada para testar modelos teóricos que apenas teoricamente indicam uma relação de causa e efeito entre variáveis, a regressão hierárquica está, no máximo, descrevendo padrões de relacionamento entre variáveis. 2.4- Algoritmo de exclusão sequencial, backward elimination, descendente ou r2 decrescente, critério estatístico...
No algoritmo de backward elimination - modelo mais complexo para o mais simples.
1º- Algoritmo de exclusão sequencial para ajuste do modelo completo, com os p preditores; 2º- Verificar se existe alguma variável cujo coeficiente bi não difira significativamente de zero. Em caso negativo, passar ao ponto seguinte. Em caso afirmativo, qualquer dessas variáveis é candidata a sair do modelo. 3º- Se apenas existe uma candidata a sair, excluir essa variável; 4º- Se existir mais do que uma variável candidata a sair, excluir a variável associada ao maior p-value (isto é, ao valor da estatística t mais próxima de zero). Em qualquer caso, reajustar o modelo após a exclusão da variável e repetir este ponto 5º- Quando não existirem variáveis candidatas a sair, ou quando sobrar um único preditor, o algoritmo pára. Tem-se então o modelo final. 2.5- Algoritmo de inclusão sequencial, forward selection, ascendente ou 1-r2 crescente...
No algoritmo de inclusão sequencial (forward selection - modelo mais simples para o complexo) o submodelo inicial é a regressão linear simples com o maior valor de r2, ou seja, classifique as variáveis de forma ascendente em função de 1- r2 e, sequencialmente, se acrescenta cada variável até a última ou até se alcançar uma condição de paragem e, em cada passo, é necessário ajustar tantos submodelos quantas forem as variáveis ainda não incluídas.
1º- ajustar o modelo de regressão linear simples, com a variável preditora mais fortemente correlacionada com Y (menor 1-r2); 2º- ajustar os submodelos constituídos pela(s) variável(is) preditora(s) já incorporadas, e mais um preditor de entre os que ainda não foram incluídos no submodelo; 3º- verificar se nalgum dos submodelos assim criados, a variável cuja inclusão se ensaiou tem coeficiente b que seja diferente significativamente de zero. Em caso negativo, passar ao ponto seguinte. Em caso afirmativo, qualquer dessas variáveis é candidata a entrar no modelo. 1- se apenas existe uma candidata a entrar, incluir essa variável; 2- se existir mais do que uma variável candidata a entrar, incluir a variável associada ao menor p-value (isto é, ao valor da estatística t mais longe de zero) 3- Reajustar o modelo com a nova variável e repetir este ponto. 4- Quando não existirem variáveis candidatas a entrar, o algoritmo pára. Tem-se então o modelo final. 2.6- Algoritmo de exclusão/inclusão alternada, Stat F, stepwise selection, passo-a-passo ou escalonada...
A regressão stepwise geralmente é a estratégia escolhida para estudos exploratórios. Quando se está utilizando este tipo de regressão, o pesquisador, desprovido de uma teoria consistente sobre os fenômenos estudados, está interessado apenas em escrever relacionamentos pouco conhecidos entre variáveis, e não em os explicar. Neste tipo de regressão, a seleção da seqüência de entrada dos preditores na equação é feita estatisticamente, sem um modelo teórico consistente a ser seguido. Em estudos exploratórios, o pesquisador elabora um modelo teórico de investigação que inclui hipóteses sobre relacionamentos entre variáveis, mas que ainda não possibilita afirmações consistentes sobre a magnitude ou direção desses relacionamentos. Além disso, este tipo de estudo ainda não encontra apoio empírico às hipóteses a serem testadas.
Material Mínímo de duas tabelas com as variáveis do modelo biológico em tempos diferentes (Estudo de Coorte). Um bloco é definido como qualquer vértice (variável) com suas causas imediatas. H1: O modelo é (total ou parcialmente) válido estatísticamente. 2ª etapa: Par - Aplicar a regressão logística para cada par (orientado) de variáveis. F. As variáveis de desfecho são nominais, as preditoras quaisquer, incidência não é importante 1- Regressão Logística múltipla politômica (multinomial), o desfecho tem 3 ou mais categorias...
Polytomous LR, multiclass LR, softmax regression, multinomial logit, maximum entropy (MaxEnt) classifier, conditional maximum entropy model.
G. A variável de desfecho é binária, as preditoras quaisquer e a incidência é importante
1.1.1- Há apenas 1 amostra: Regressão de Poisson para uma amostra.
1.1.2- Há 2 amostras: Teste de comparação de taxa de incidência para 2 amostras. 1.1.3- Há 3 ou mais amostras: Teste de incidência para taxa de incidência.
1.2- A taxa de incidência NÃO é constante no tempo (Análise de sobrevivênica...) (tempo até o evento)
Testes de significância para comparar amostras em análise de sobrevida - Univariada: Teste de log-rank, multivariável: Regressão de Cox...
H. Outros testes não-paramétricos para 3 ou mais variáveis
Curvas de sobrevivência de Kaplan-Meier... 1.2.1- Comparação de curvas de sobrevivência de 2 amostras com controle limitado de covariâncias: 1.2.1.1- Teste de log-rank. 1.2.1.1- Teste de associação linear de Mantel- Haenszel ou Qui-quadrado de Mantel-Haenszel (para 2 amostras independentes). 1.2.1.1- Conditional proportional hazards regression (para 2 amostras pareadas)... 1.2.2- Efeito de alguns fatores de risco na sobrevivência: Regressão de Cox de riscos proporcionais (proportional-hazards) para 2 ou mais amostras independentes, Regressão condicional proporcional (conditional proportional hazards regession) para 2 ou mais amostras pareados.. 1.1- Fração Atribuível Populacional Agregada (FAPA): Determina a proporção total da incidência do desfecho na população, atribuída à combinação de diversos fatores de exposição. 1.2- Fração Atribuível Populacional por Componentes (FAPC) - Determina a proporção total da incidência do desfecho na população, atribuída à cada componente de exposição. 1.3- Fração Atribuível Populacional Ajustada por Estratificação (FAPAE). 1.4- Fração Atribuível Populacional Ajustada Sequencial (FAPAS). 1.5- Fração Atribuível Populacional Ajustada pela Média (FAPAM).
1- Teste de Mantel-Haenszel-Cochran (MHC test)
3- Redes Neurais, estima-se a estrutura (aproximada) da função, os parâmetros são pesos.
: Use the MHC test to conditionally test the associations of two binary variables in the presence of a third categorical variable.
2- Método Solver de aproximação. 4- Série de Fourier (função base senoidal). 5- Redes RBF com centro e dispersão fixas (gaussiana, multiquadrática, etc). 6- Perceptron (função-base logística). F. Técnicas de Agrupamento e Redução de Variáveis
Análise de conglomerados ou dendrograma (Cluster Analysis)
2- Análise de componentes principais (ACP)...
Prof. Lorí Viali, Dr. PUCRS FAMAT: Departamento de Estatística O termo Análise de Conglomerados, Aglomerados (Cluster analysis ) foi utilizado pela primeira vez por Tryon em 1939 e a técnica é de fato um conjunto de técnicas (algoritmos) de classificação. É uma técnica multivariada que tem como objetivo agrupar dados de acordo com as similaridades entre eles. É uma ferramenta estatística com a qual é possível formar grupos com homogeneidade dentro do agrupamento e heterogeneidade entre eles. Como são determinados os grupos? Existem diferentes métodos para isto, que deverão ser selecionados em função da quantidade de dados disponíveis e do número de agrupamentos a serem formados. As Hipóteses 9 A amostra deve ser representativa da população; 9 A colinearidade múltipla entre as variáveis deve ser mínima; 9 A amostra deve estar livre de outliers e a razão n/k deve ser razoável Outras nomenclaturas Técnicas similares tem sido independentemente desenvolvidas em vários campos, dando origem a nomes diferentes para esta técnica estatística (p. e. Biologia, Arqueologia, etc.) . Análise de Conglomerados Taxionomia Numérica Análise Q Análise de Tipologia Análise de Classificação Variações Existem várias técnicas diferentes de aglomeração dependendo do: Procedimento utilizado para medir a similaridade ou distância entre os objetos e do algoritmo de agrupamento empregado. Metodologi a No estágio inicial, quando cada item representa seu próprio grupo, as distâncias entre os itens são definidas pela distância escolhida. No entanto, uma vez que vários itens tenham sido agrupados, como determinar a distância entre os grupos formados? Em outras palavras, é necessário uma regra de agrupamento para determinar quando dois grupos são semelhantes o suficiente para serem transformados em um novo grupo. Existem várias possibilidades. Por exemplo, se poderia juntar dois grupos quando dois itens quaisquer nos dois grupos estão mais próximos do que a distância de agrupamento. Colocando de outra forma: será utilizado o vizinho mais próximo ( nearest neighbors ) entre grupos para determinar as distâncias entre os aglomerados. Este método é denominado de encadeamento simples ( single linkage ). Esta regra produz grupos ligados por itens que estão próximos por acaso. De forma alternativa pode-se utilizar vizinhos que estão o mais distante possível um do outro dando origem ao método de encadeamento completo (complete linkage). Existem muitos métodos de encadeamento semelhantes aos dois propostos. Passo 1 - A análise inicia com o estabelecimento de uma base de dados nxk; Passo 2 - Utilizando um dos vários métodos, uma matriz nxn é criada para indicar as similaridades (ou dissimilaridades) de cada objeto para os demais basedo nas k variáveis Passo 3 - Utilizando um dos vários algoritmos, os objetos são colocados nos diferentes grupos, onde: os objetos dentro dos grupos são os mais homogêneos possíveis e os grupos são os mais diferentes possíveis entre si. Medidas de similaridades ou diferenças A análise de aglomerados inicia criando uma matriz que indica a similaridade (ou distância) entre cada par de objetos relativos às k variáveis contidas na base de dados. Existem várias formas de se fazer isto. 3- Análise de Fatores (FacAn)... •É um nome genérico dado a uma classe de métodos estatísticos multivariados, cujo propósito principal é definir uma estrutura fundamental em uma matriz de dados (Hairetal., 1995). O termo análise de fatores foi introduzido por Thurstone em 1931. 1) Identificar dimensões latentes, isto é, fatores que justifiquem as correlações observadas entre as variáveis 2) Substituir o conjunto original de variáveis (em geral grande) e correlacionadas por um conjunto menor de variáveis sem correlação ou com baixa correlação. 3) Objetivo Global: parcimônia, isto é, redução da complexidade. Reduzir diversas variáveis, provavelmente correlacionadas, a uma quantidade menor e mais facilmente gerenciável. Analisar a estrutura das correlações entre um grande número de variáveis, definindo um conjunto menor de dimensões básicas comuns, chamadas fatores. Identificar, em um conjunto maior de variáveis, um conjunto menor que se destaque para uso em uma futura análise multivariada; Sumarizar os dados, para obter uma melhor percepção do objeto de pesquisa. Autovalor: é a variância padronizada associada com um particular fator. A soma dos autovalores não pode exceder o número de variáveis (itens), uma vez que cada item contribui com a unidade na soma das variâncias. Fator: uma combinação linear das variáveis (itens) no sentido de uma regressão, onde o escore total do teste é a variável dependente e os itens são as variáveis independentes. Carga do fator:a carga de um fator expressa a correlação do fator com a variável. O quadrado da carga do fator indica a proporção da variância partilhada entre a variável e o fator. Escore do fator: Medida composta criada para cada observação em cada fator da análise. Os pesos dos fatores são utilizados em conjunto com os valores originais da variável para calcular cada um dos escores. Os escores dos fatores são padronizados da mesma forma que o escore z. Matriz padrão dos fatores: uma matriz contendo os coeficientes ou cargas utilizadas para expressar um item em termos do fator. Ela coincide com a matriz de estrutura se os fatores são ortogonais (não-correlacionados). Matriz estrutura dos fatores: uma matriz contendo as correlações dos itens com cada um dos fatores. Solução rotada dos fatores: uma solução, onde os eixos são girados com o propósito de mostrar um padrão mais visível das cargas dos fatores. Gráfico de declividade (Scree plot): um diagrama mostrando os autovalores de cada fator. Teste de esfericidade de Bartlett: Verifica se todas as correlações dentro da matriz de correlações são significativas. Matriz de correlação anti-imagem: é a matriz das correlações parciais entre as variáveis (itens) após a análise de fatores. Representa o grau com que os fatores explicamum ao outro nos resultados. Análise de factores comum: modelo de fatores na qual os fatores são baseados numa matriz de correlação reduzida, isto é, as comunalidades são inseridas na diagonal da matriz de correlação e a extração dos fatores é baseada somente na variância comum excluindo as variâncias específicas e do erro. Variância do erro: variância de uma variável devido a erros na coleta ou medida dos valores. Medida de adequação da amostra (MAS - Measure of Sampling Adequacy): medida calculada tanto para a matriz de correlação quanto para cada variável individualmente avaliando a adequação da aplicação da análise de fatores. Valores maiores do que 0,5 tanto para a matriz como um todo quanto para as variáveis indivualmente indicam que o método é adequado. Etapas 1. Formular o problema 2. Montar matriz de correlações 3. Validar a Análise de Fatores 4. Determinar o método 5. Determinar Número de Fatores 6. Rotacionar Fatores 7. Interpretar Fatores 8. Atribuir Nomes aos Fatores 1- Árvore de Decisão
r1 e r2 são as regras (filtros) de decisão da árvore. - CART (Classification - categóricas - and Regression - intervalares - Tree)...
Classification and regression trees (CART) are a non-parametric decision tree learning technique that produces either classification or regression trees, depending on whether the dependent variable is categorical or numeric, respectively.
2- Teste do χ2 de Pearson para testes diagnósticos: Estudo metodológico sobre acurácia de testes diagnósticos...
A árvore de decisão (binária, mas pode ter mais divisões) consiste numa hierarquia de nós internos e externos que são conectados por ramos (Na teoria dos grafos: nó = vértice, ramos = aresta). O nó interno, também conhecido como nó decisório ou nó intermediário, é a unidade de tomada de decisão que avalia através de teste lógico qual será o próximo nó descendente ou filho. O nó externo (não tem descendente), também conhecido como folha ou nó terminal, está associado a um rótulo ou a um valor. Em geral, o procedimento de uma árvore de decisão é: aplicase a regra a um conjunto de dados ao nó inicial (ou nó raiz; nó interno), dependendo do resultado do teste lógico, a árvore ramifica-se para um dos nós filhos e este procedimento é repetido recursivamente até que um nó terminal seja alcançado. Quando os dados satisfazem o teste lógico do nó intermediário seguem para o nó esquerdo (VERDADEIRO) se não para o nó direito (FALSO). O aprendizado de uma árvore de decisão é supervisionado, ou seja, o método aproxima funções-alvo de valor discreto, na qual a função aprendida é representada por uma árvore de decisão. As árvores treinadas podem ser representadas como um conjunto de regras Se-Então para melhoria da Árvore de Decisão compreensão e interpretação. Árvores de decisão usadas para problemas de classificação são chamadas de Árvores de Classificação. Nas árvores de classificação, cada nó terminal ou folha contém um rótulo que indica a classe predita para um determinado conjunto de dados. Neste tipo de árvore pode existir dois ou mais nós terminais com a mesma classe. Para ilustrar uma árvore de classificação, encontra-se na Figura 2 a representação gráfica deste tipo de árvore para duas classes. Figura 2 - Árvore de Classificação Na árvore de classificação ilustrada na figura anterior as classes formadas são Classe 1, representada pelos nós 3 e 5 , e a Classe 2, representada pelo nó 4. As regras obtidas após a árvore treinada são: Regra para Classe 1 Se (x1 > 0.7) ou Se (x1 = 0.7 e x2 > 0.5) Regra para Classe 2 Se (x1= 0.7 e x2= 0.5) Árvores de decisão usadas para problemas de regressão são chamadas de Árvores de Regressão. Nas árvores de regressão, cada nó terminal ou folha contém uma constante (geralmente, uma média) ou uma equação para o valor previsto de um determinado conjunto de dados. Empregando a mesma representação gráfica da árvore de classificação (Figura 2), temos para cada nó terminal um modelo linear. -ésimo parâmetro ß do modelo linear do k-ésimo nó; ruído do modelo linear do k-ésimo nó; x : dados de entrada Y : dados de saída Existem dois aspectos que merecem destaques em uma árvore de decisão, o crescimento e a poda, que serão abordados na seção 3.1. Por fim, um dos mais conhecidos e mais completos algoritmos de árvore de decisão é o CART Classification and Regression Tree - que foi proposto por Breiman (1984). Como este algoritmo será empregado em uma das etapas da modelagem proposta nesta tese, é conveniente realizar uma breve descrição do CART na seção 3.2. Árvore de Decisão 25 3.1. Crescimento e Poda As árvores de decisão são construídas usando um algoritmo de partição recursiva. Este algoritmo constrói uma árvore por divisões recursivas binárias que começa no nó raiz e desce até os nós folhas. Têm-se dois fatores principais no algoritmo de partição: a forma para selecionar uma divisão para cada nó intermediário (Crescimento) e uma regra para determinar quando um nó é terminal (Poda). O problema chave, no algoritmo de partição recursiva, é a confiabilidade as estimativas do erro usado para selecionar as divisões. As escolhas da divisão em níveis maiores da árvore produzem, freqüentemente, estatísticas não- confiáveis apesar da estimativa do erro de resubstituição (estimativa obtida com os dados de treinamento usado durante o crescimento da árvore) manter-se decrescendo. Com isto, a precisão das estimativas do erro é fortemente dependente da qualidade da amostra. Como o algoritmo divide recursivamente o conjunto de dados de treinamento original, as divisões estão sendo avaliadas com amostras cada vez menores. Isto significa que as estimativas de erro têm menos confiabilidade à medida que crescemos a árvore. Com intuito de minimizar este problema e evitar o superajustamento dos dados de treinamento com árvores muito complexas, tem-se a estratégia conhecida como método de podagem. Há dois procedimentos alternativos para podagem da árvore de decisão: a pós-podagem e a pré-podagem. A pós-podagem é o processo pelo qual uma árvore é crescida ao tamanho máximo e então métodos de evolução confiáveis são usados para selecionar a árvore podada de tamanho certo desde o modelo inicial. Este algoritmo considera a podagem como um processo de dois-estágios. No primeiro estágio, um conjunto de árvores podadas de Tmax (árvore de tamanho máximo) é gerado de acordo com algum critério, enquanto no segundo estágio uma dessas árvores é selecionada como o modelo final. Os métodos de pós-podagem podem ser computacionalmente ineficientes, no sentido que não é usual achar domínios onde uma árvore extremamente grande (por exemplo, com milhares de nós) é pós-podada em poucas centenas de nós - isto parece um desperdício computacional. Uma alternativa de parada no Árvore de Decisão procedimento de crescimento da árvore é interromper o crescimento tão logo a divisão seja considerada não-confiável. Isto é conhecido como a pré-podagem da árvore. O método de pré-podagem usa um procedimento passo único. Este algoritmo corre através dos nós da árvore ou de baixo para cima ou de cima para baixo, decidindo para cada nó, se é para podar de acordo com algum critério de avaliação. Os métodos de pré-podagem também apresentam um ponto negativo no seu algoritmo. A pré-podagem corre o risco de selecionar uma árvore subótima ao interromper o crescimento da árvore (Breiman, 1984). Breiman (1984) descreveu duas alternativas para a seleção da árvore final baseada nas estimativas dos erros obtidos. Ou seleciona a árvore com menor erro estimado ou escolhe a menor árvore na seqüência, cujo erro estimado está dentro do intervalo: Errb + SE(Errb), onde Errb é o menor erro estimado e SE(Errb ) é o erro padrão desta estimativa. Mas tarde, este método será conhecido como a regra 1-SE. Para maiores detalhes sobre essas alternativas consultar Breiman (1984) ou Zighed (2000). Destaca-se que para árvores de classificação a podagem é em função da complexidade do custo mínimo (erro de resubstituição) e para árvores de regressão, a podagem é em função da complexidade do erro mínimo. 3.2. CART A metodologia do modelo CART (Breiman, 1984) é tecnicamente conhecida como partição recursiva binária. O processo é binário porque os nós pais são sempre divididos exatamente em dois nós filhos e recursivamente porque o processo pode ser repetido tratando cada nó filho como um nó pai. As principais características do CART são: definir o conjunto de regras para dividir cada nó da árvore; decidir quando a árvore está completa; associar cada nó terminal a uma classe ou a um valor preditivo no caso da regressão. Para dividir um nó em dois nós filhos, o algoritmo sempre faz perguntas que tem apenas um sim ou um não como resposta. Por exemplo, as questões podem ser: a idade é <=55? ou o crédito é <=600? Árvore de Decisão 27 O próximo passo é ordenar cada regra de divisão com base no critério de qualidade de divisão. O critério padrão usado para classificação é o Índice de Gini que tem por base o cálculo da entropia (Zighed, 2000 e Lamas, 2000)(2) onde p é a frequência encontrada de cada classe j, e o processo de divisão da árvore de regressão procura minimizar R(T). (3) sendo t o identificador de cada nó da árvore e R(T) o valor esperado da soma dos erros quadráticos da regressão utilizando uma constante como modelo preditivo (a média). Como pode-se notar na equação 3, o CART não apresenta na árvore de regressão, um modelo linear em seus nós terminais e sim uma média. Uma vez encontrada a melhor divisão, repete-se o processo de procura para cada nó filho, continuamente até que a divisão seja impossível ou interrompida. No procedimento do CART, ao invés de determinar quando um nó é terminal ou não, continua-se proporcionando o crescimento da árvore até que não seja mais possível fazê-lo, como por exemplo ao atingir um número mínimo de dados na amostra. Depois que todos os nós terminais foram encontrados, é definida a árvore como maximal, ou seja, a árvore de tamanho máximo. Após encontrar a árvore maximal, começa-se a podar alguns ramos da mesma árvore de modo a aumentar o poder de generalização. Algumas sub-árvores, obtidas através da poda de alguns ramos desta árvore, são examinadas testando taxas de erros e a melhor delas é escolhida.
1- SENSIBILIDADE é a proporção de resultados positivos em doentes (VP) / (VP + FN).
2- ESPECIFICIDADE é a proporção de resultados negativos em não-doentes (VN) / (VN + FP). 3- EFICIÊNCIA é a proporção entre (VP + VN) / (VP + VN + FP + FN), ou seja, a porcentagem correta do resultado dos testes. 4- ÍNDICE DE YOUDEN (J) é a uma medida probabilidade de classificação correta que não depende da prevalência da doença (Se + Ep - 1). 5- VALOR PREDITIVO POSITIVO (+) é a probabilidade da pessoa com um teste positivo tenha a doença (VP) / (VP + FP). É baseada na PREVALÊNCIA da doença na população. 6- VALOR PREDITIVO NEGATIVO (-) é a probabilidade da pessoa com um teste negativo NÃO tenha a doença (VN) / (VN + FN). É baseada na PREVALÊNCIA da doença na população. 7- VALIDADE EXTRÍNSECA é a capacidade do teste em detectar a real situação da população em relação à doença em estudo, além de também avaliar o desempenho do teste nesta população (é medida pela PRECISÃO, ACURÁCIA (EXATIDÃO) e REPRODUTIBILIDADE). 8- CLASSIFICAÇÃO INCORRETA 9- RAZÃO DE VERSOSSIMINLHANÇA POSITIVA (+) 10- RAZÃO DE VERSOSSIMINLHANÇA NEGATIVA (-) Estudos sobre a reprodutibilidade de testes Índice de cocordância Kappa: variáveis com respostas categóricas Coeficiente de Correlação Intraclasse (CCI) Razões de probabilidade Estudos sobre o efeito dos resultados do teste nas decisões clínicas Estudos sobre factibilidade, custos e riscos de testes Estudo sobre efeito do teste nos desfechos 1) Método não paramétrico: 2) Kaplan-Meier e Modelos Probabilísticos: 3) Exponencial; 4) Weibull; 5) Log-Normal; 6) Gama. Fatores de risco = Só pode ser empregado quando existe uma relação de Causa e Efeito, caso contrário se usa Fatores associados. RP: razão de prevalência = prevalência entre os expostos / prevalência entre os não-expostos. PE (prevalência entre os expostos) = nº de casos conhecido de uma dada doença na pop. exposta / população exposta. PNE (prevalência entre os não expostos) = nº de casos conhecido de uma dada doença na pop. não exposta exposta / população não exposta. Dados absolutos podem ser transformados em valores relativos, uma escala de resultados-padrão com média zero e desvio-padrão 1, resultando no chamado z-score, calculado pela seguinte expressão: valor relativo = Z-score = (X - média aritmética) / desvio padrão. 3- Curvas ROC: Estudo metodológico sobre acurácia de testes diagnósticos...
A fim de diminuir o cálculos é recomendável tranformar as duas curvas normais em Normais reduzidas
Cutoff < 276,6 tem α < 0,05 de ∈ S(200;50) e cutoff > 282,2 tem α < 0,05 de ∈ D(400;75). Usada nos estudos de comparação entre testes diagnósticos (padrão-ouro x novo teste). As Hipóteses Quanto menor o "cutoff point" maior a sensibilidade e menor a especificidade. são: H0: O indivíduo é doente (D = 1). X H1: H0 é falsa. "O estímulo é apresentado ou não, ou modificando-se o estado motivacional do observador por meio de recompensas (benefícios) ou punições (custos) às respostas emitidas." As curvas ROC são expressas pelas taxas de acertos e em função das respectivas taxas de falso alarme.
A Curva ROC (Receiving Operating Characteristics) é o gráfico da relação entre sensibilidade x (1 - especificidade), portanto as duas amostras são independentes e sem relação com a prevalência. A curva ROC teórica pode ser formada por duas curvas Normais (portanto de variáveis independentes contínuas) originadas de duas populações (doentes x não doentes), representadas pela Sensibilidade x Especificidade. Z-score. Exemplo_1, Exemplo_2, Exemplo_4 Exemplo_5, Exemplo_6
Na Curva TG-ROC (Two-Graph Receiving Operating Characteristics) a variável é plotada na abscissa e os parâmetros Sensibilidade e a Especificidade na ordenada, o ponto onde elas se cruzam é o ponto de corte que divide em o resultado do exame em negativo e positivo. 4- Estatística Kappa (K): Estudo metodológico sobre a de concordância entre diferentes observadores...
O Teste de Kappa é uma medida de concordância interobservador e mede o grau de concordância além do que seria esperado tão somente pelo acaso.
Índice de Concordância de Kappa 5- Análise de correspondência.
1- Análises diretas: padrões de ordenação calculados a partir de dados bióticos e ambientais concomitantemente.
1.1- Análise de gradientes 1.2- Análise de correspondência canônica (CANOCO) 1.3- Análise de redundância 1.4- Análise de correlação canônica - o objetivo é explicar a relação entre dois conjuntos de variáveis encontrando um pequeno número de combinações lineares, para cada um dos conjuntos de variáveis, de modo a maximizar as correlação possíveis entre as amostras. 2- Análises indiretas: padrões de ordenação explicados por variáveis ambientais não analisadas diretamente. 2.1- Análise de componentes principais 2.2- Análise discriminante 2.3- Análise de correspondência 2.4- Escalonamento multidimensional "Talvez a melhor resposta não esteja em estatísticas melhores, mas em um melhor pensamento ou elaboração sobre a natureza do problema." Kromrey e Foster-Johnson (1999). "Se você acha que o texto que você escreveu está maravilhoso, rasgue e jogue fora, porque com certeza ele não presta!" Oscar Wilde (1854-1900), escritor irlandês. "Espere pelo pior e prepare-se para uma surpresa!" a. (1954-amanhã), professor brasileiro. |
{kind=link}
{kind=link}
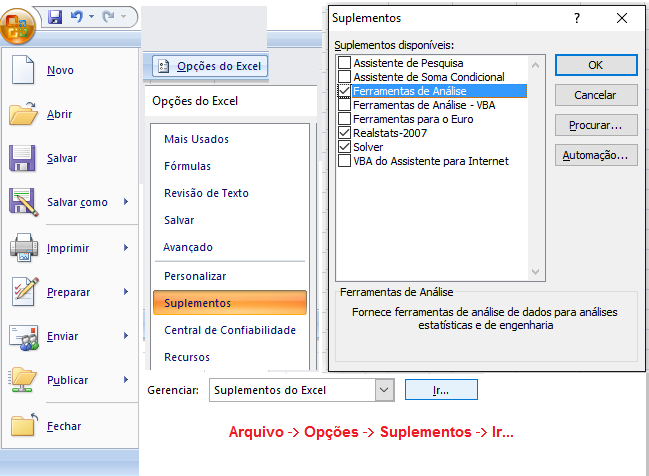{kind=link}
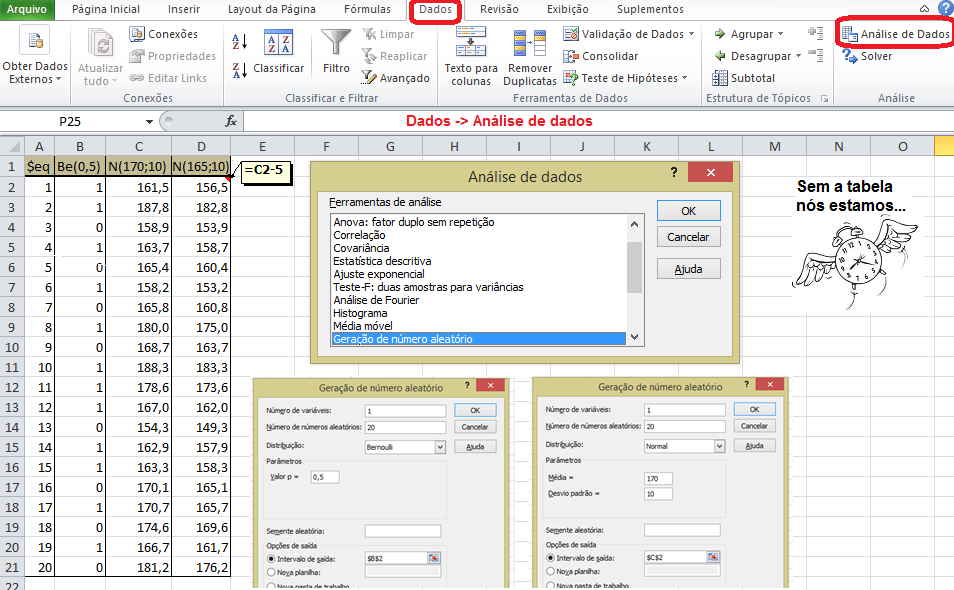{kind=link}
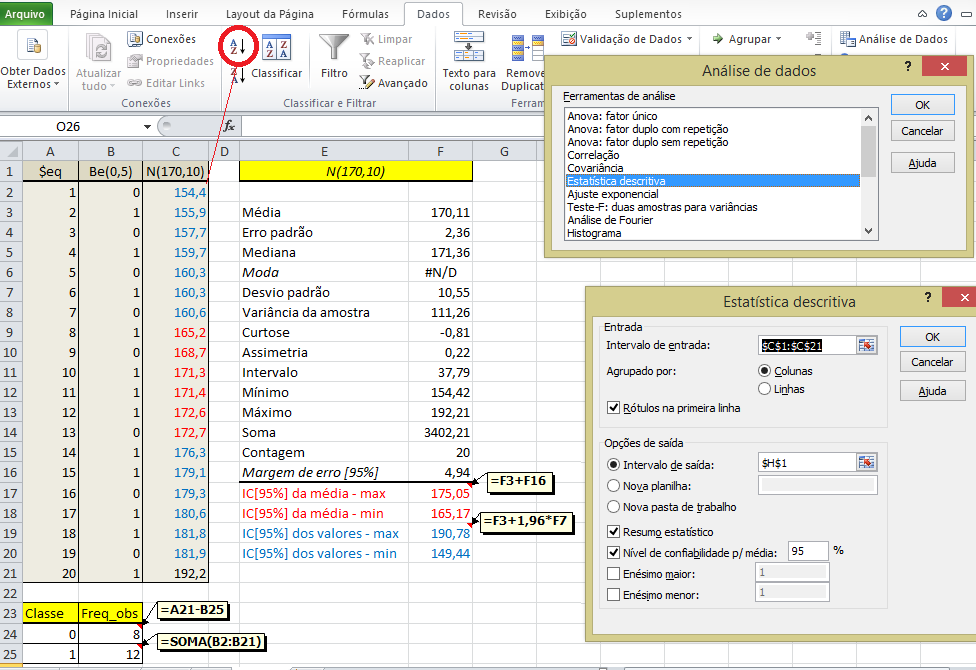{kind=link}
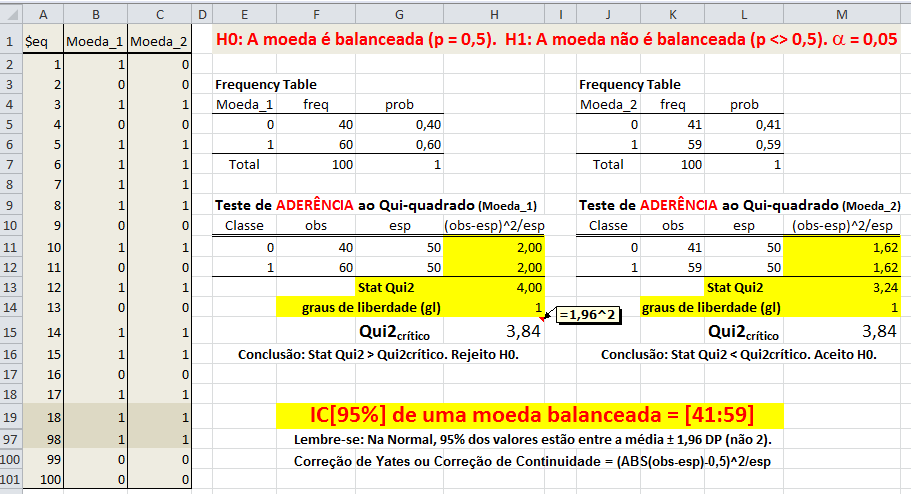{kind=link}
{kind=link}
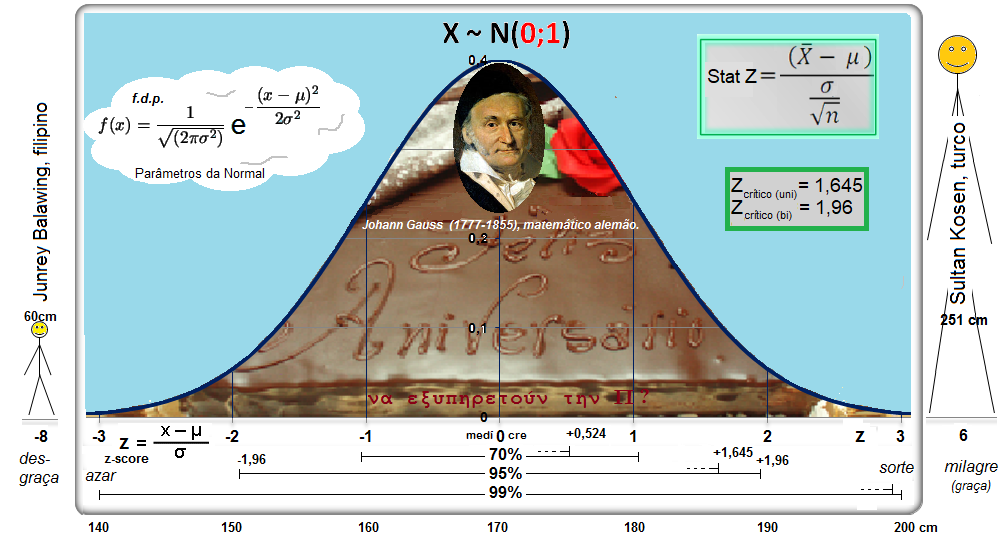{kind=link}
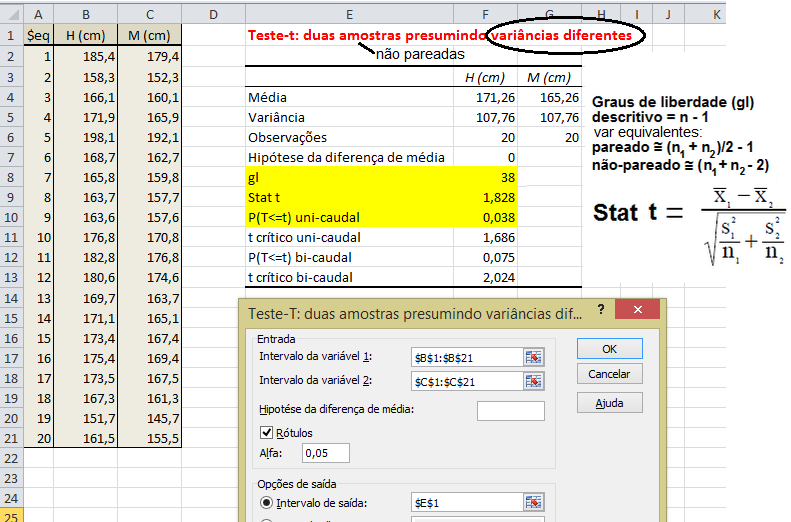{kind=link}
{kind=link}
{kind=link}
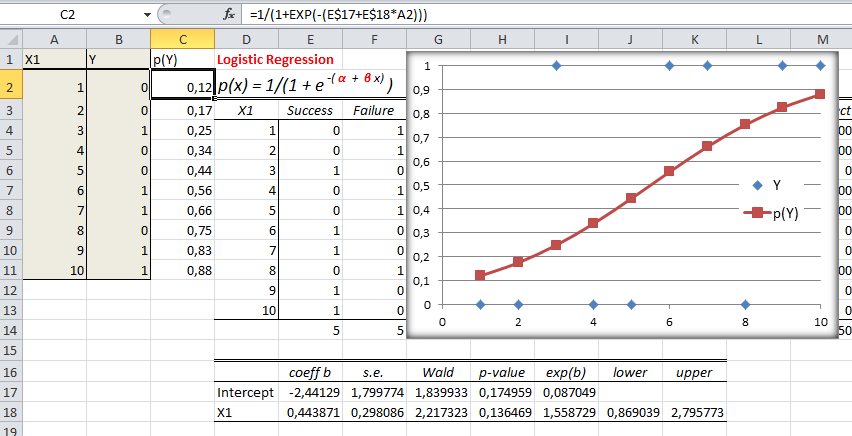{kind=link}
{kind=link}
{kind=link}
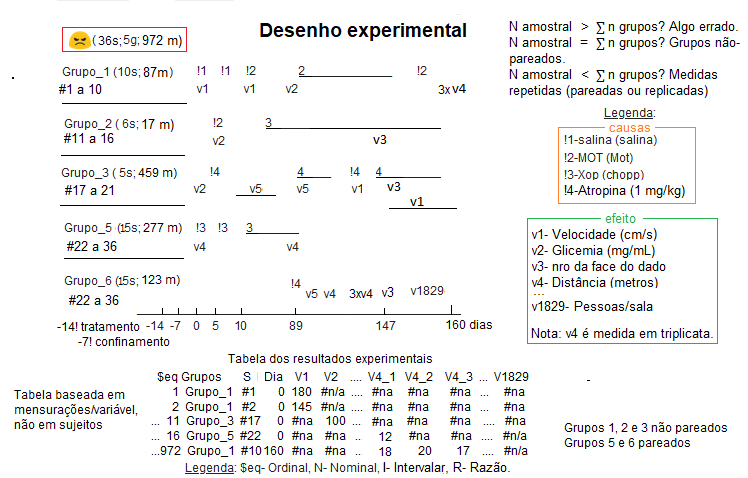{kind=link}
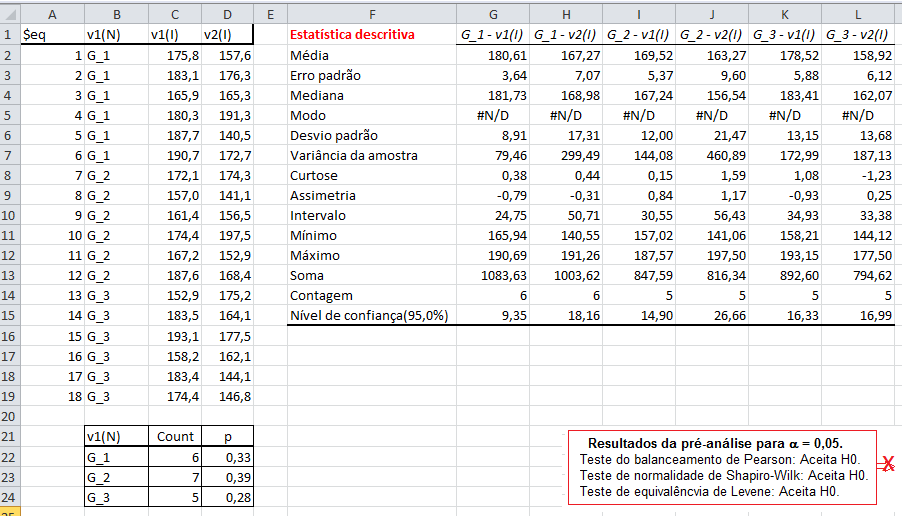{kind=link}
{kind=link}
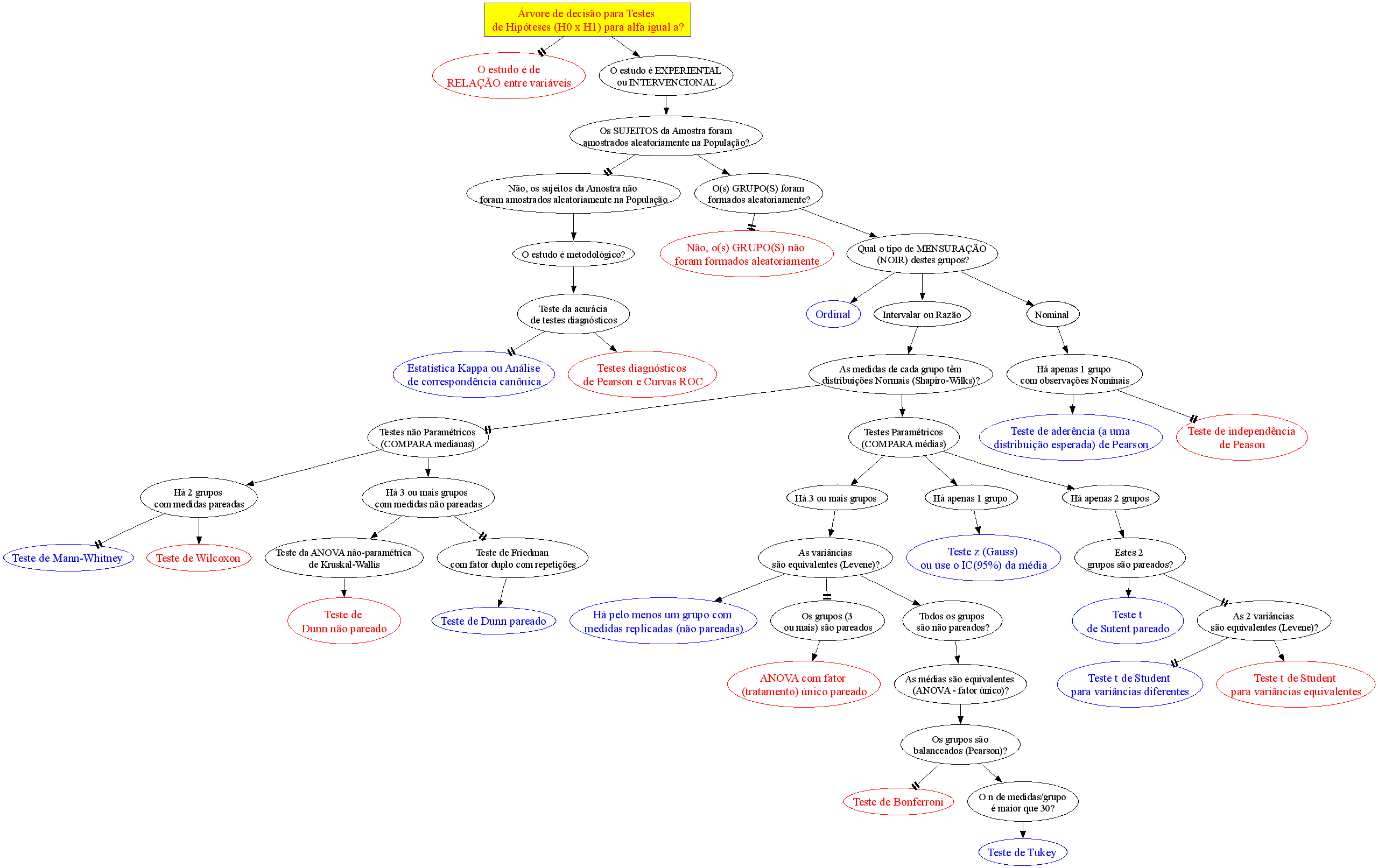{kind=link}
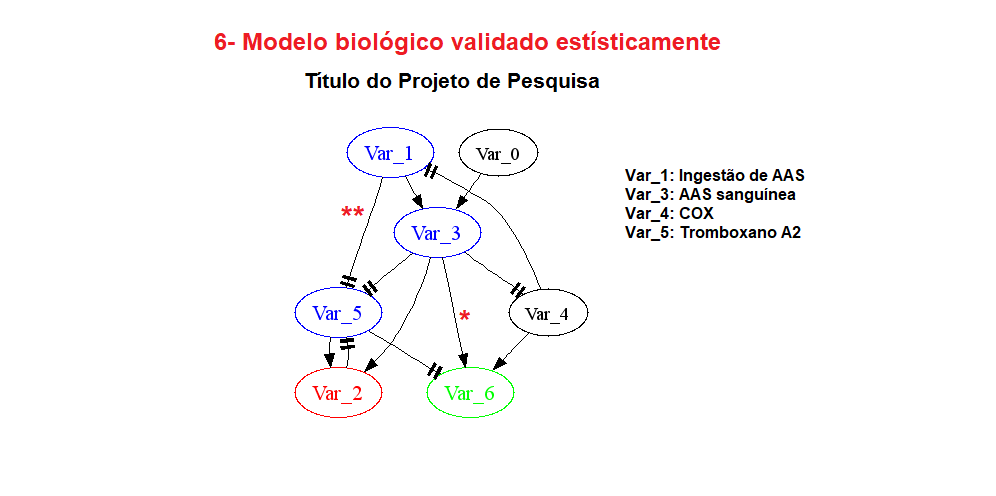{kind=link}
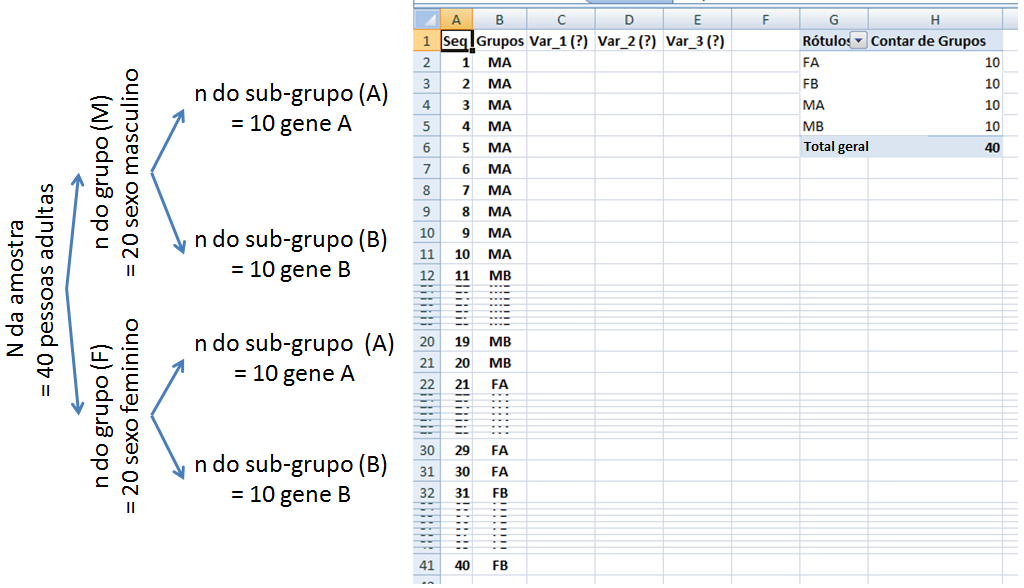{kind=link}
{kind=link}
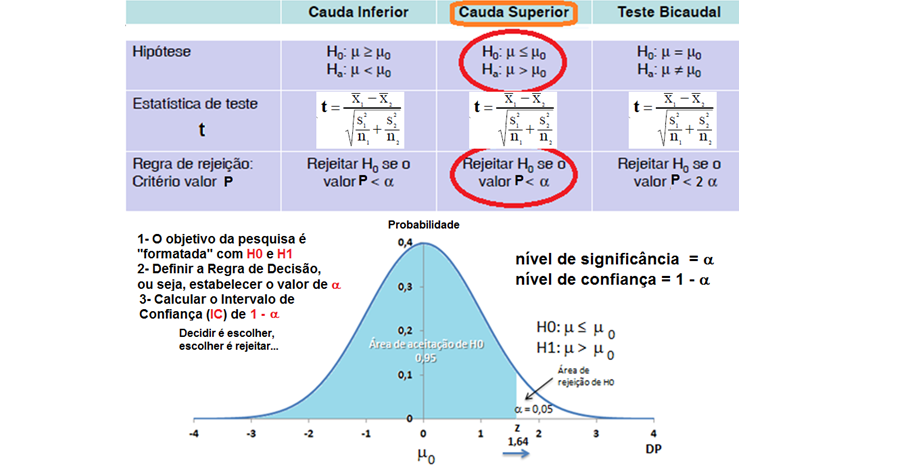{kind=link}
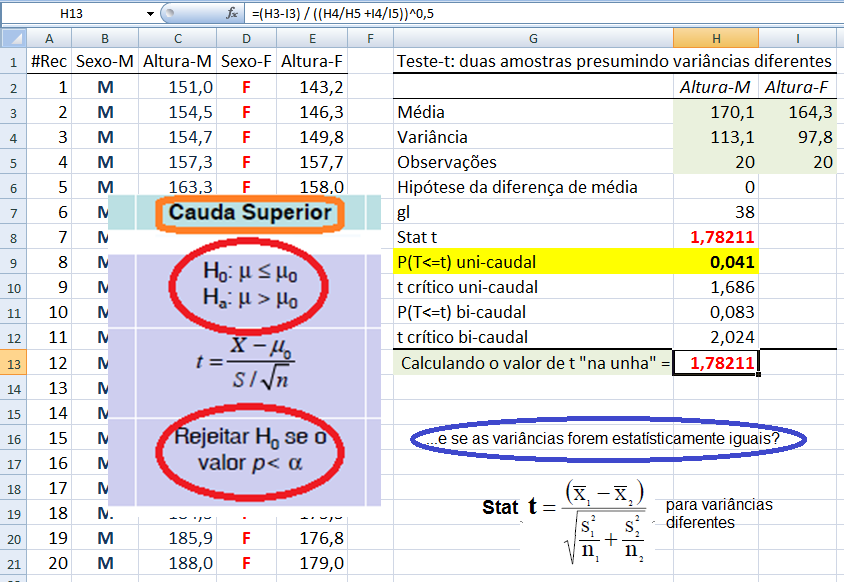{kind=link}
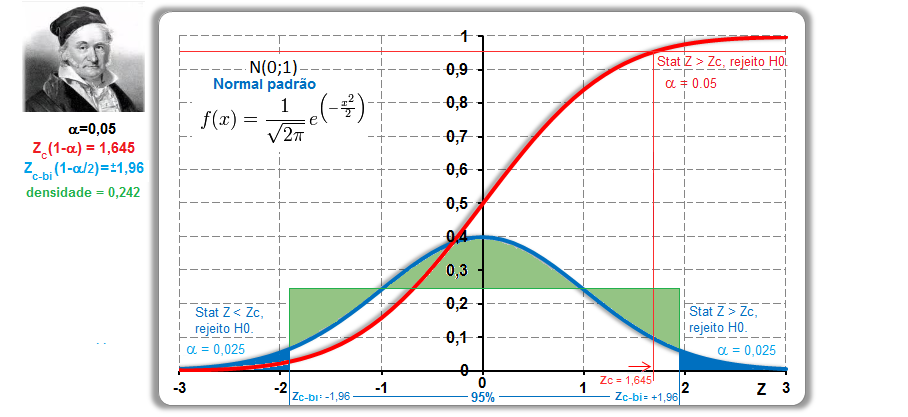{kind=link}
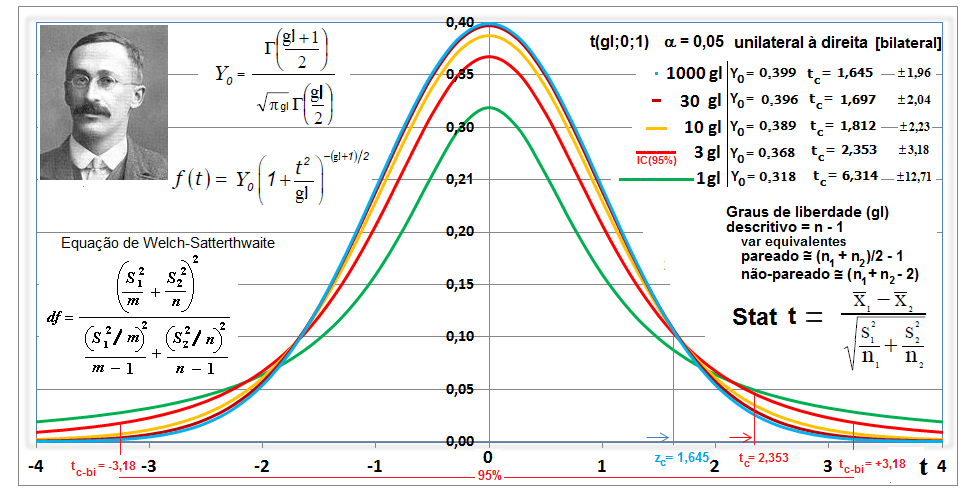{kind=link}
{kind=link}
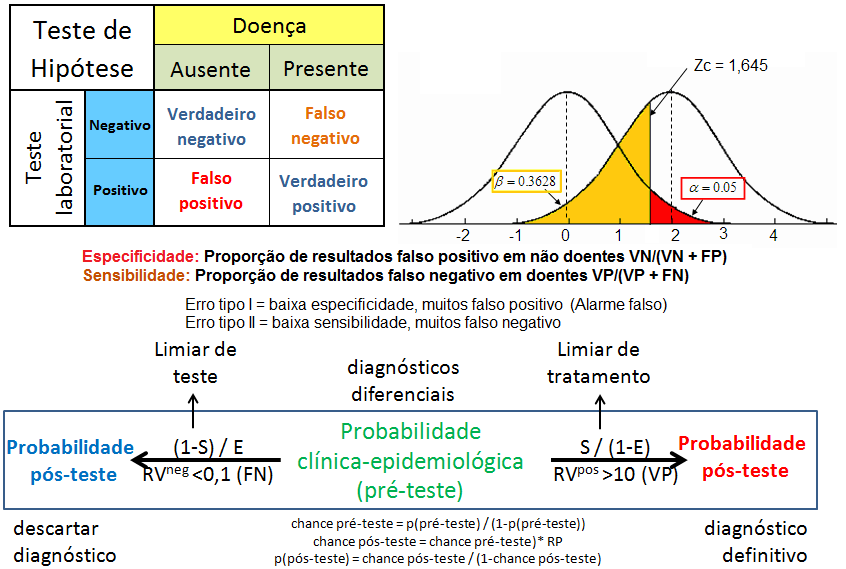{kind=link}
{kind=link}
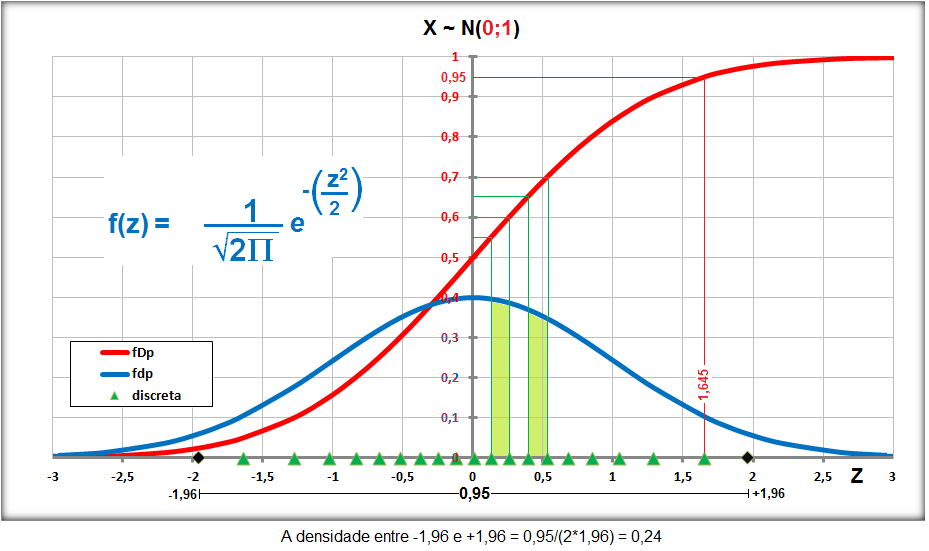{kind=link}
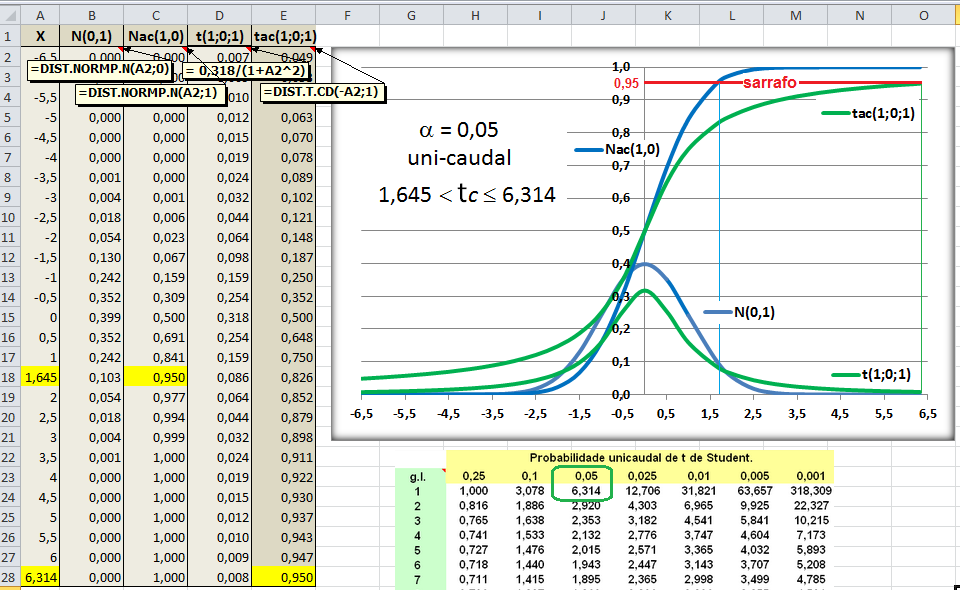{kind=link}
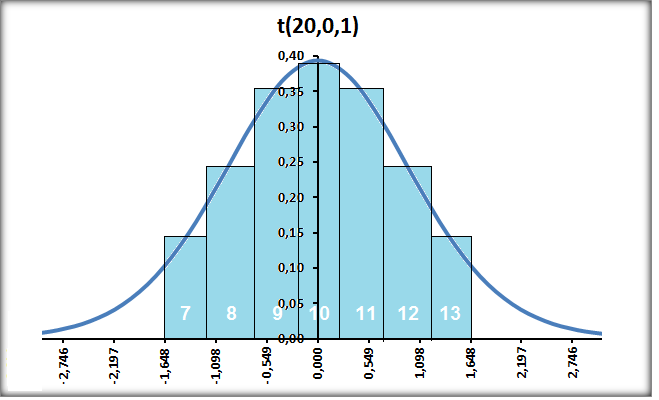{kind=link}
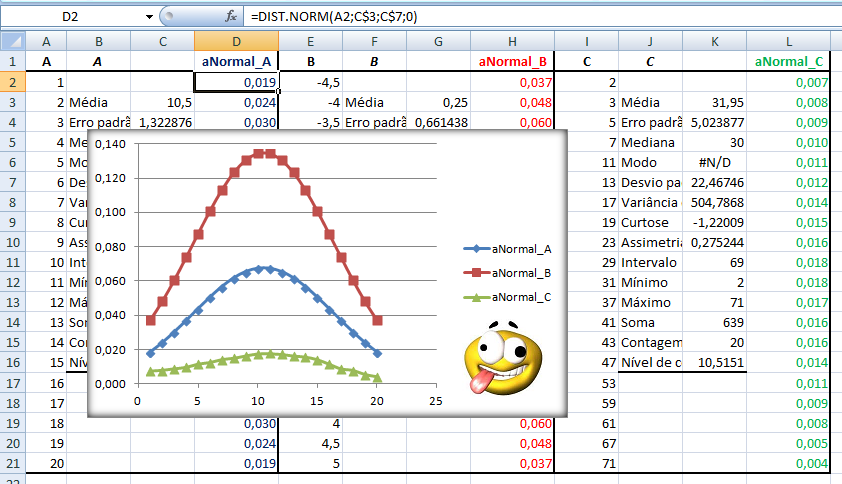{kind=link}
{kind=link}
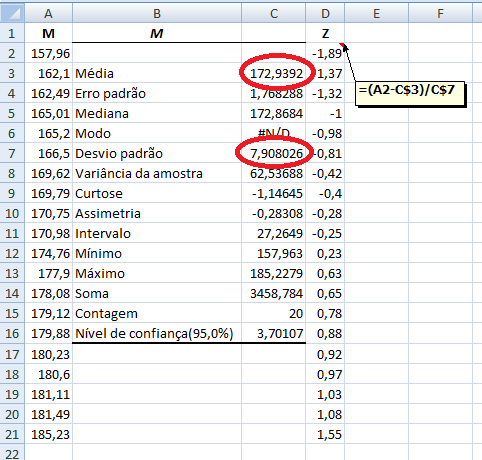{kind=link}
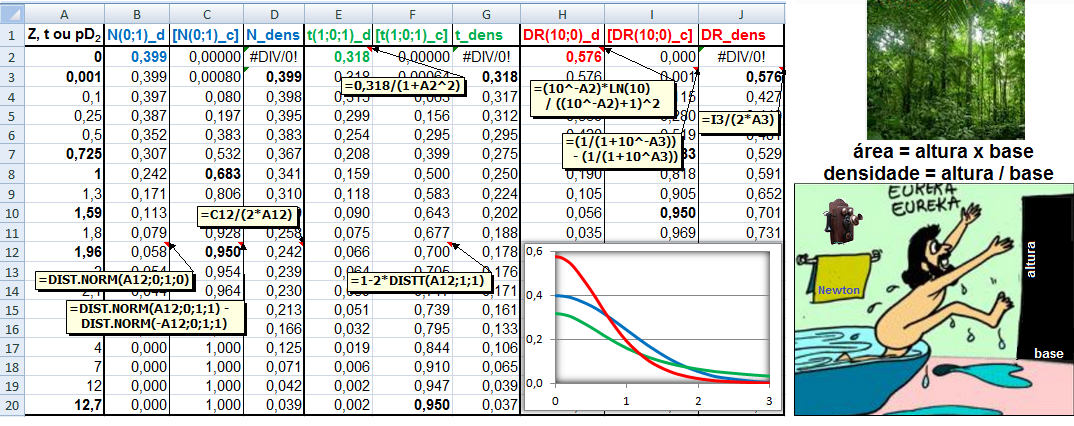{kind=link}
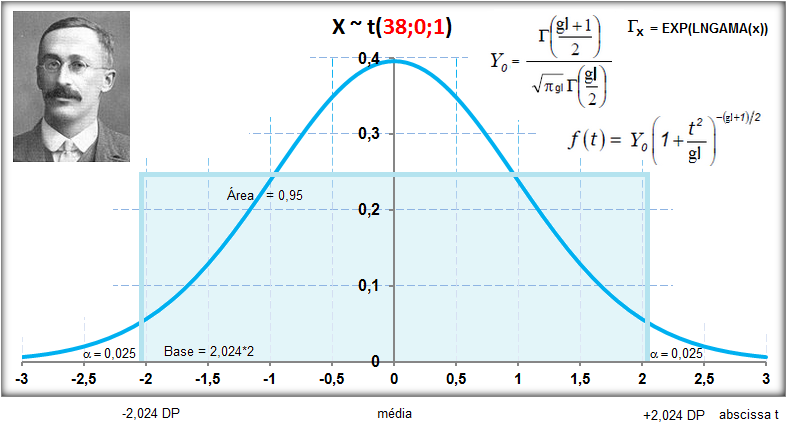{kind=link}
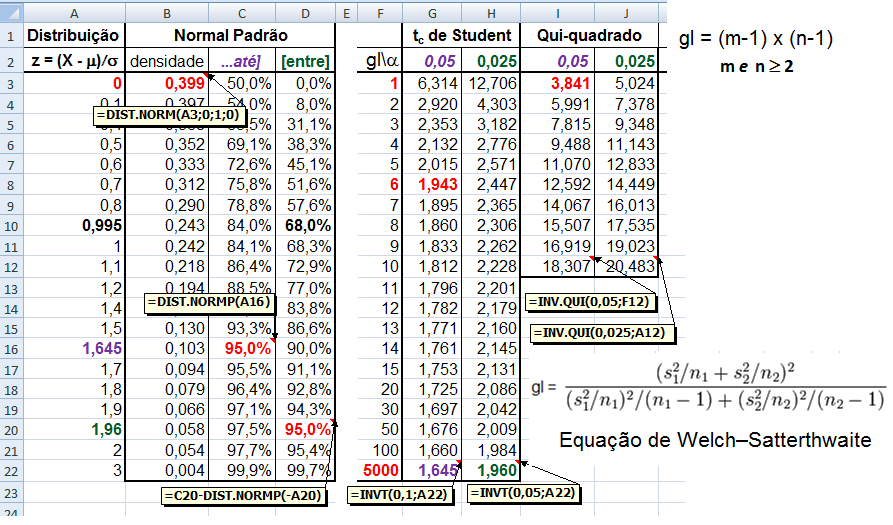{kind=link}
![Valores de t crítico bicaudal (tc_bi) e IC[95%] dos valores.](./info/ic_5.png){kind=link}
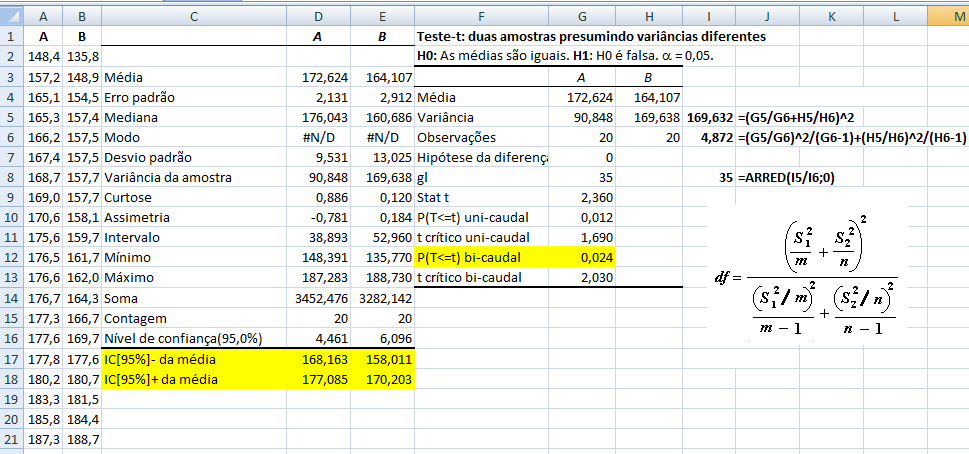{kind=link}
![IC[95%] entre médias de amostras com variâncias bem diferentes.](./info/ic0.png){kind=link}
![ICr[95%] entre médias de amostras com n e S2 iguais.](./info/ic01.png){kind=link}
![Teste t para 2 amostras e ICr[95%] para as X̅](./info/grafico.png){kind=link}
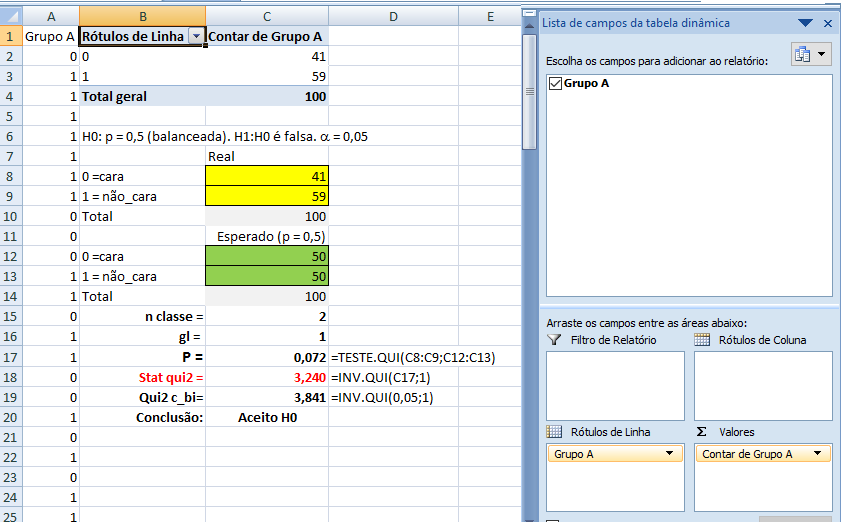{kind=link}
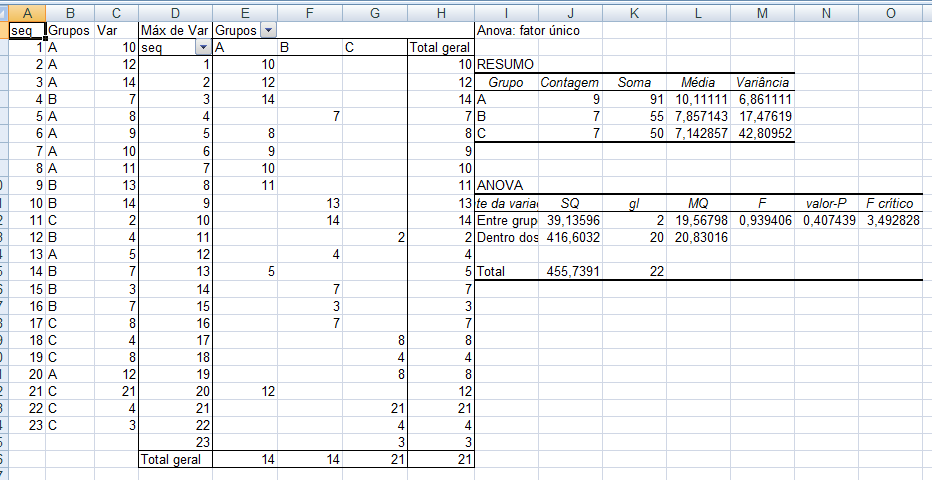{kind=link}
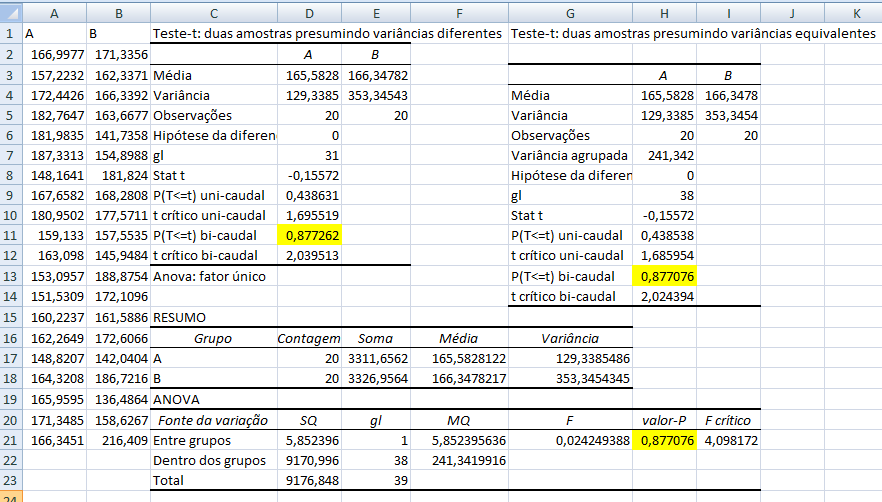{kind=link}
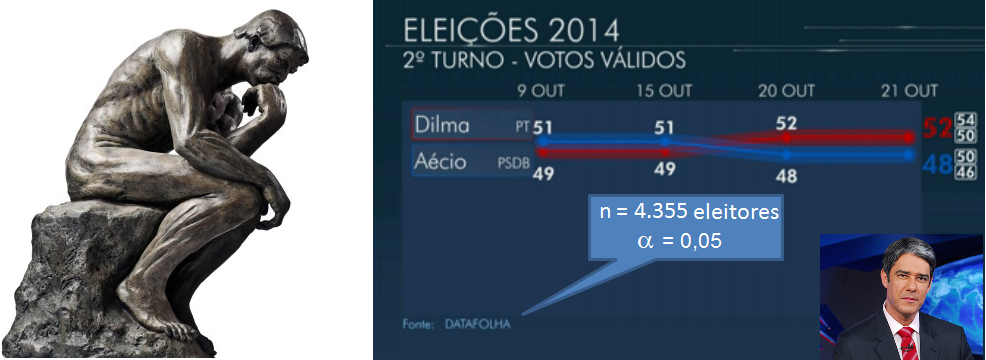{kind=link}
{kind=link}
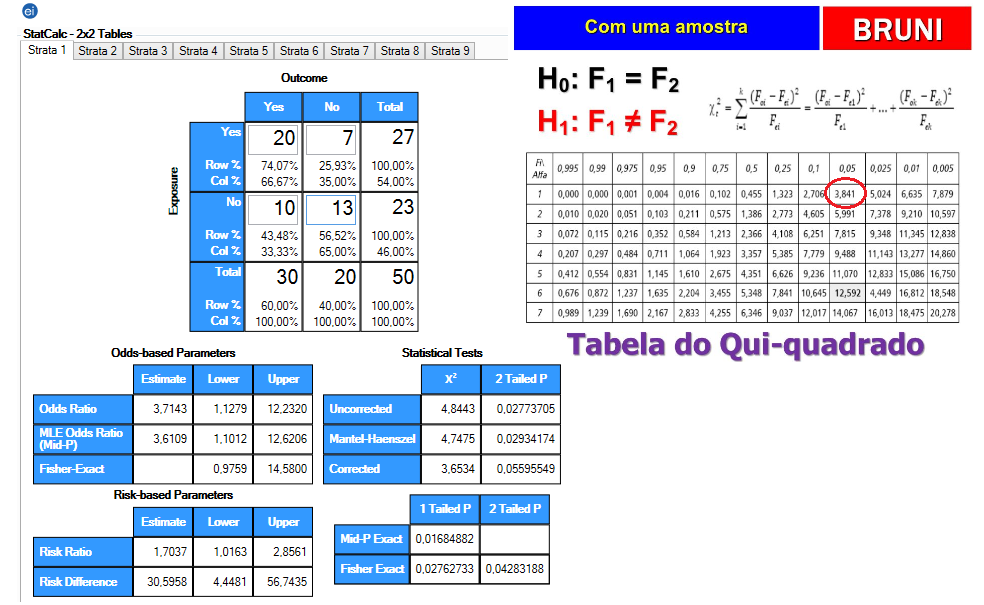{kind=link}
{kind=link}
{kind=link}
{kind=link}
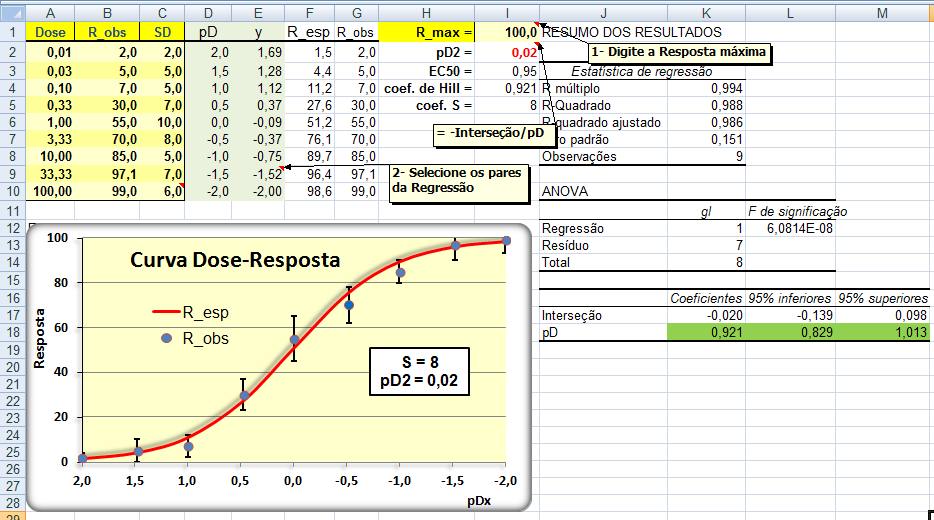{kind=link}
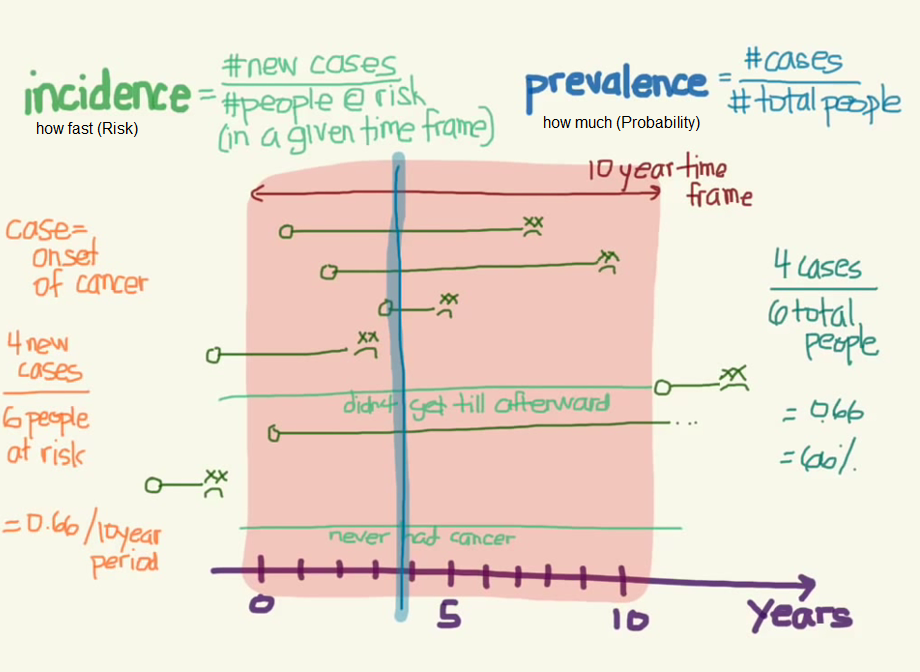{kind=link}
{kind=link}
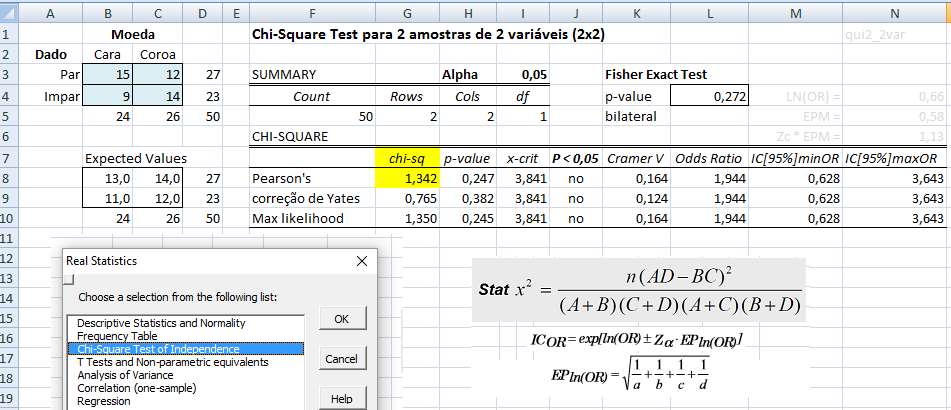{kind=link}
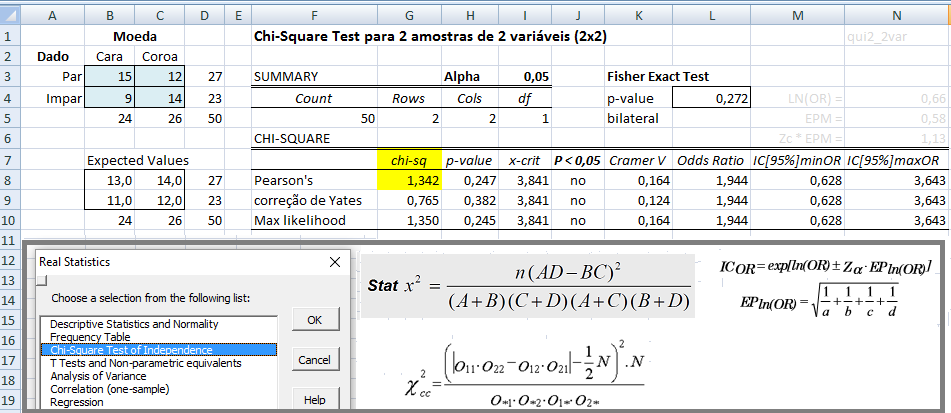{kind=link}
{kind=link}
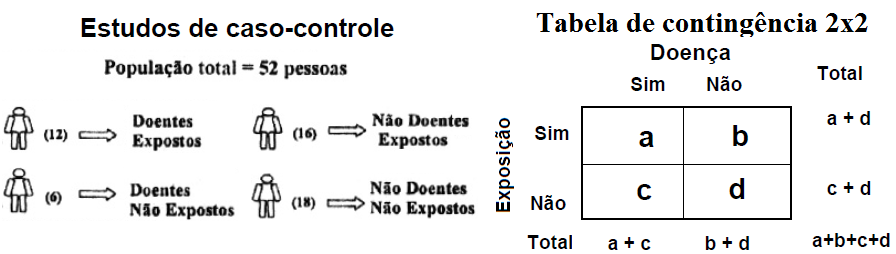{kind=link}
{kind=link}
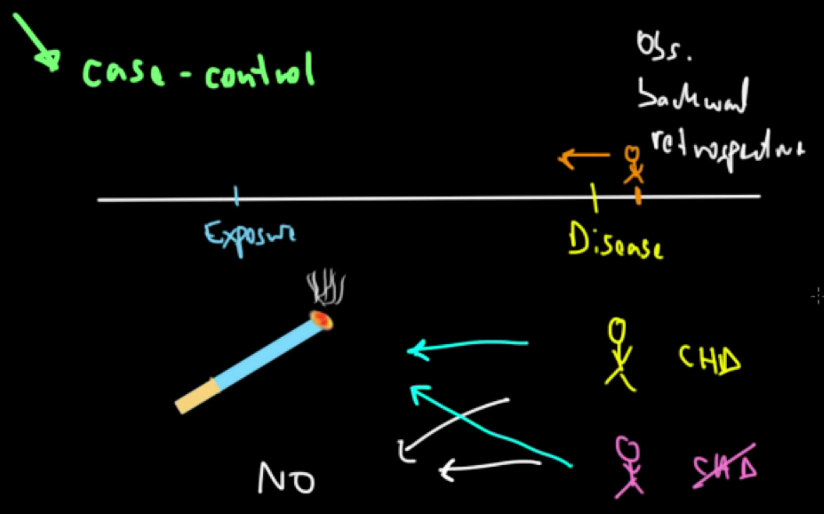{kind=link}
{kind=link}
{kind=link}
{kind=link}
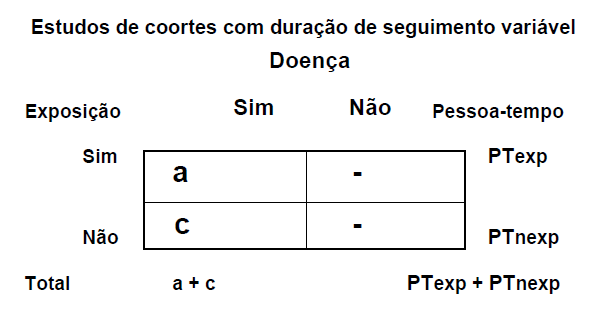{kind=link}
{kind=link}
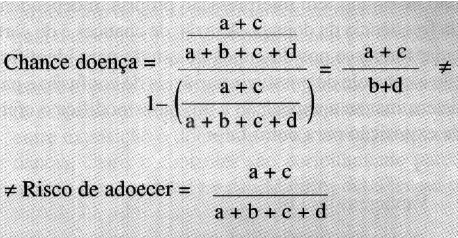{kind=link}
{kind=link}
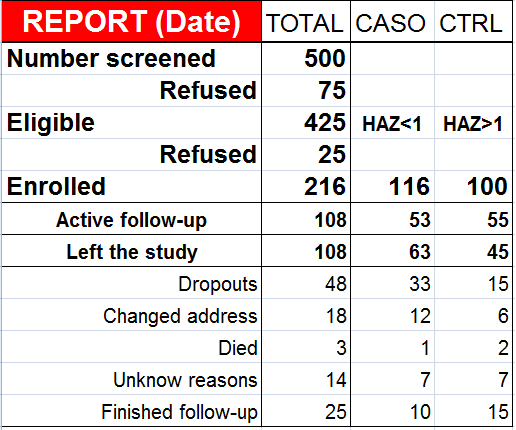{kind=link}
{kind=link}
{kind=link}
{kind=link}
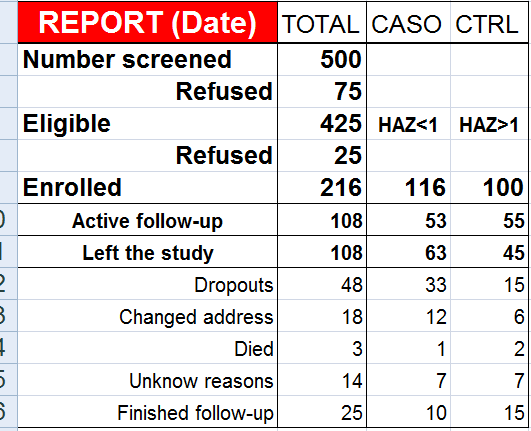{kind=link}
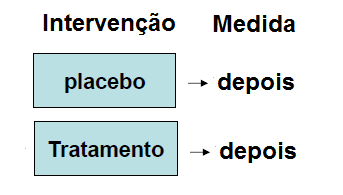{kind=link}
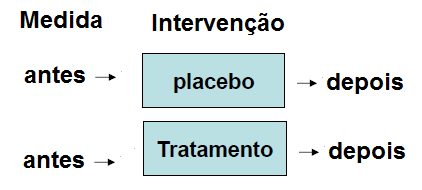{kind=link}
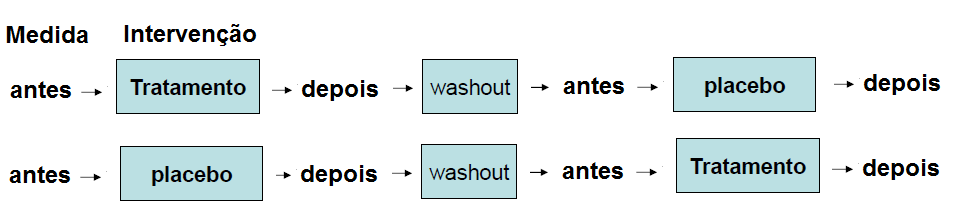{kind=link}
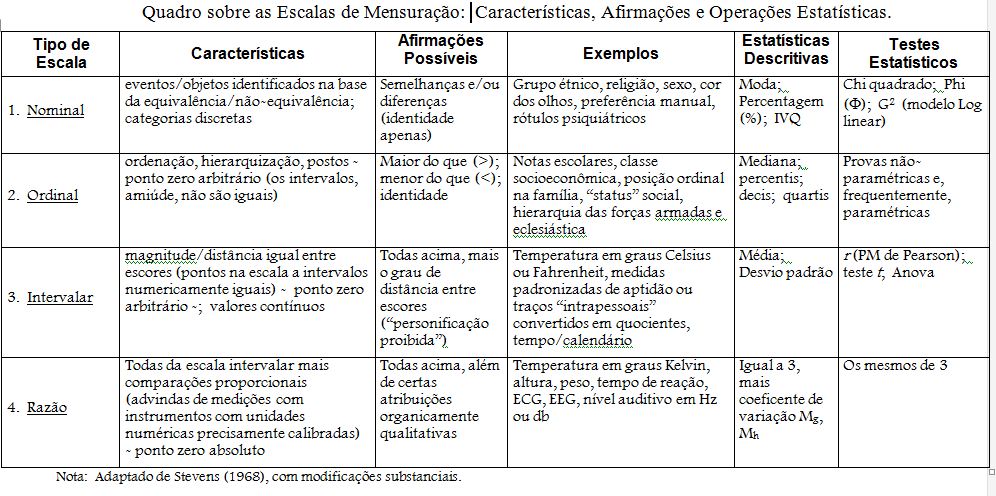{kind=link}
{kind=link}
{kind=link}
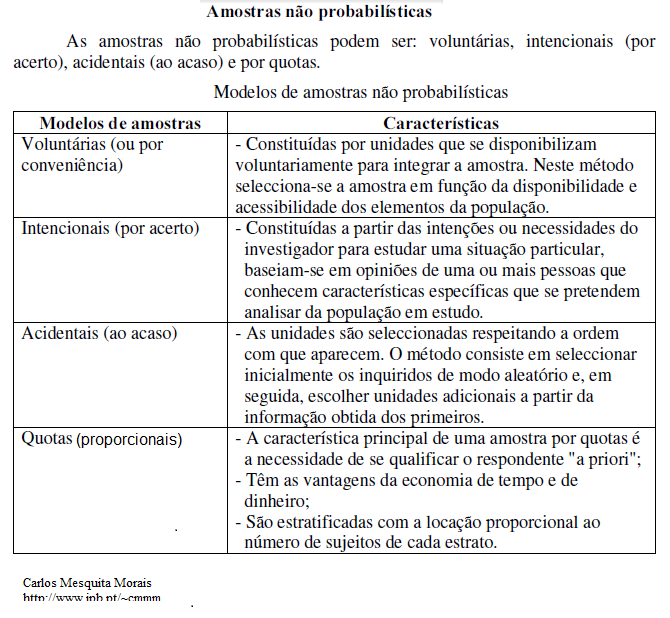{kind=link}
{kind=link}
{kind=link}
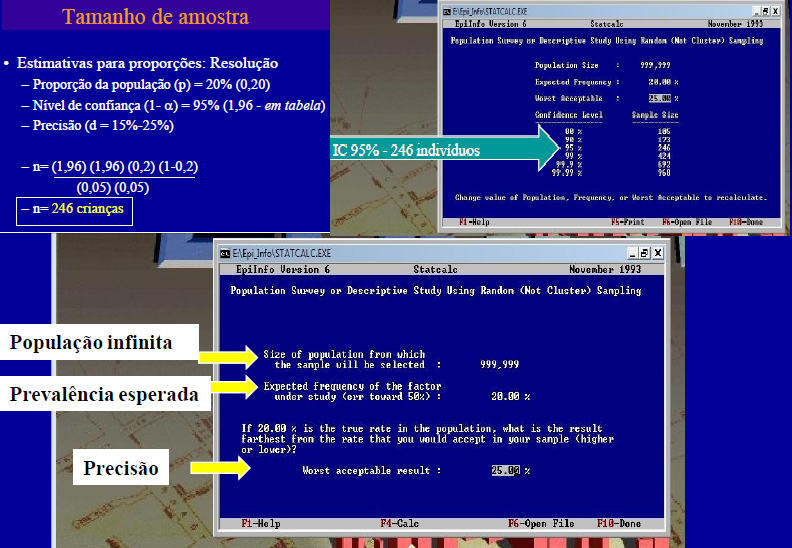{kind=link}
{kind=link}
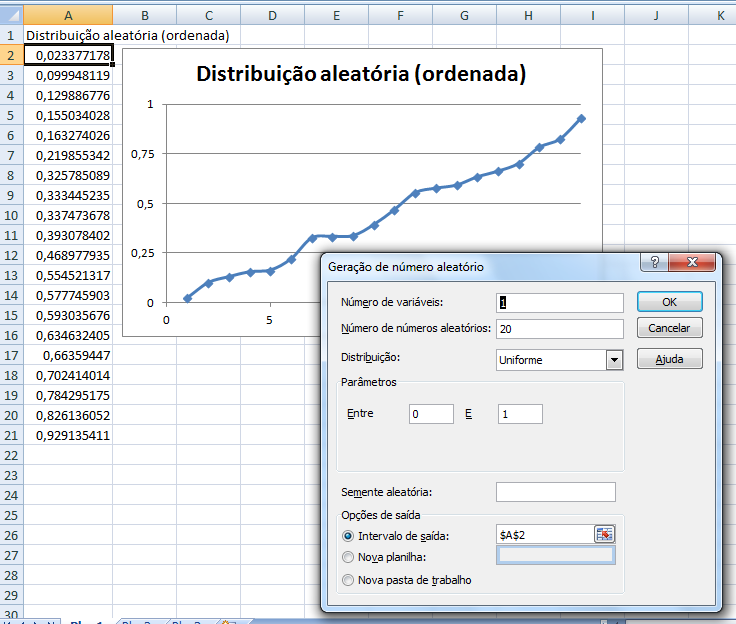{kind=link}
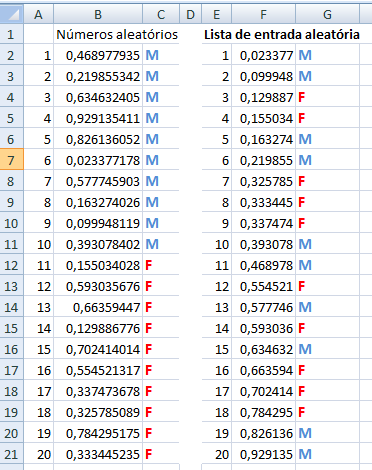{kind=link}
{kind=link}
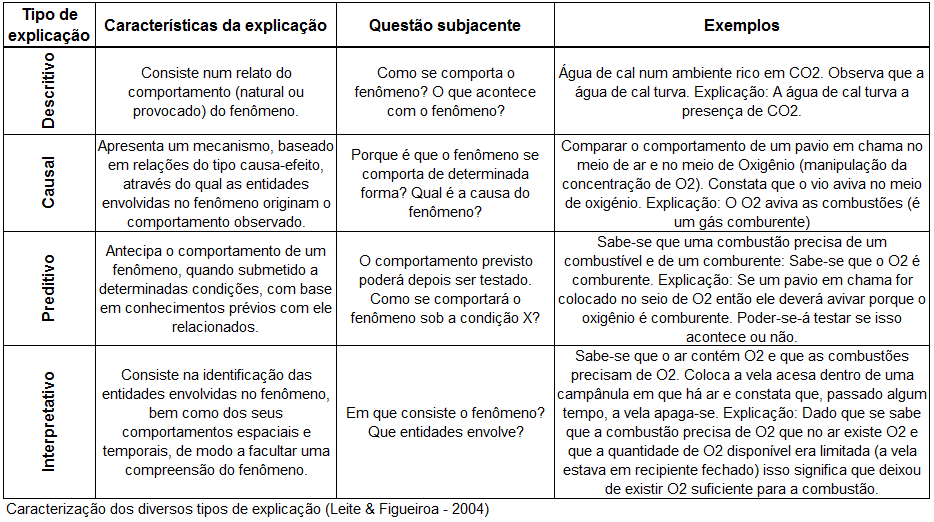{kind=link}
{kind=link}
{kind=link}
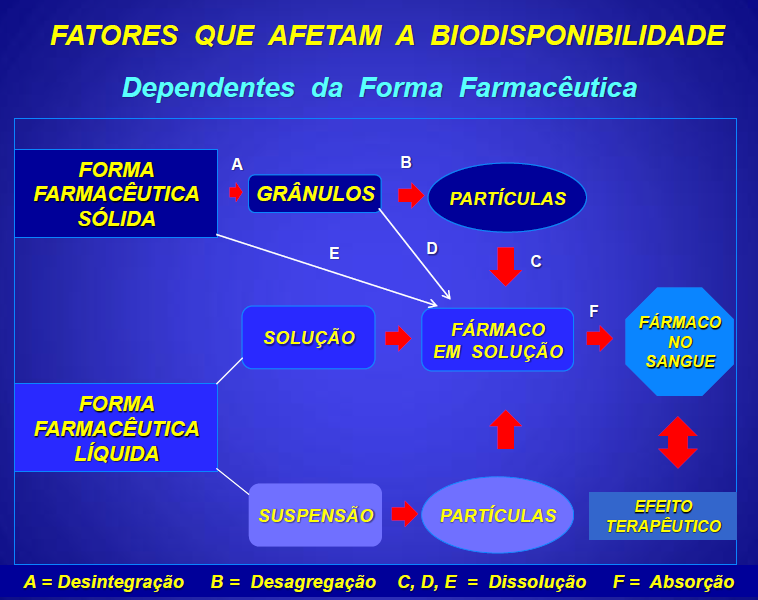{kind=link}
{kind=link}
{kind=link}
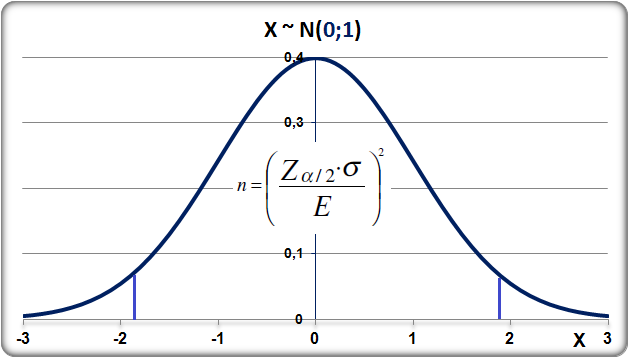{kind=link}
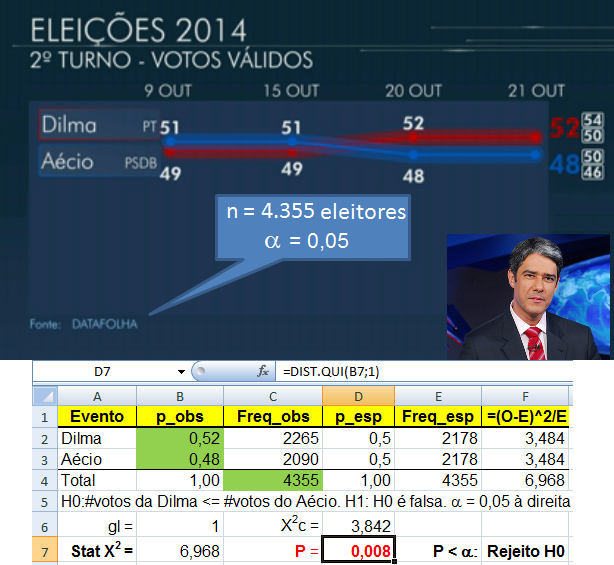{kind=link}
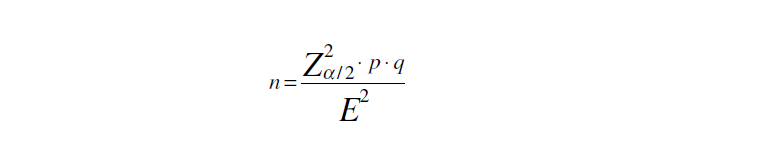{kind=link}
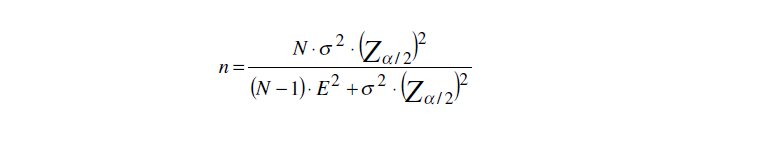{kind=link}
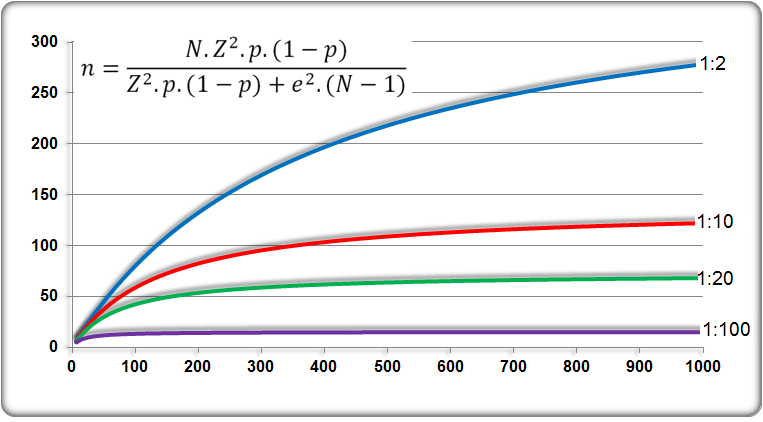{kind=link}
{kind=link}
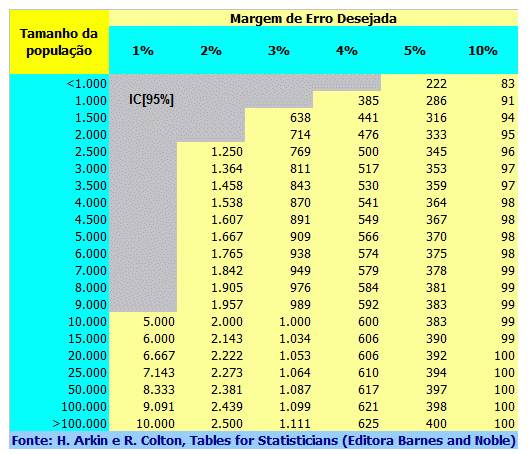{kind=link}
{kind=link}
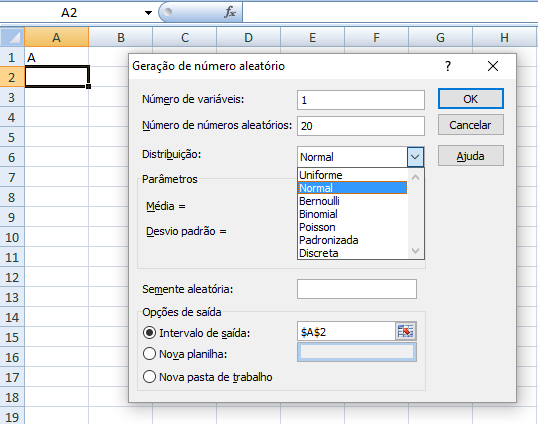{kind=link}
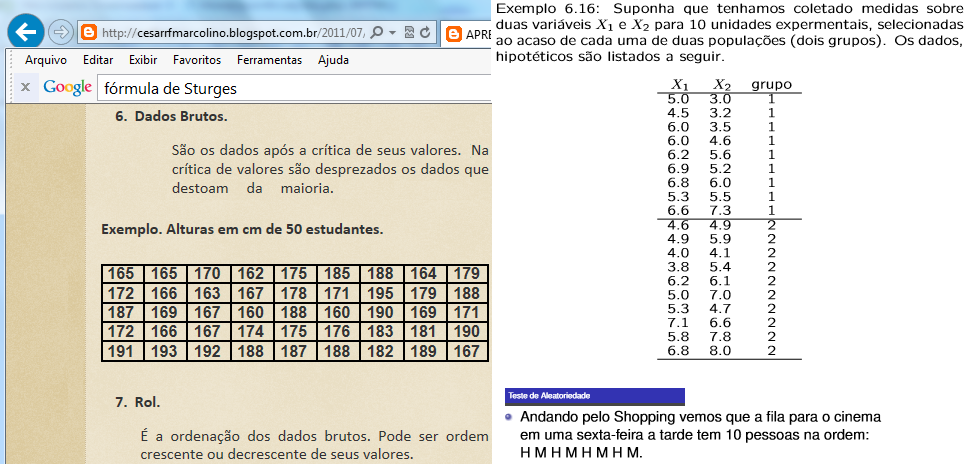{kind=link}
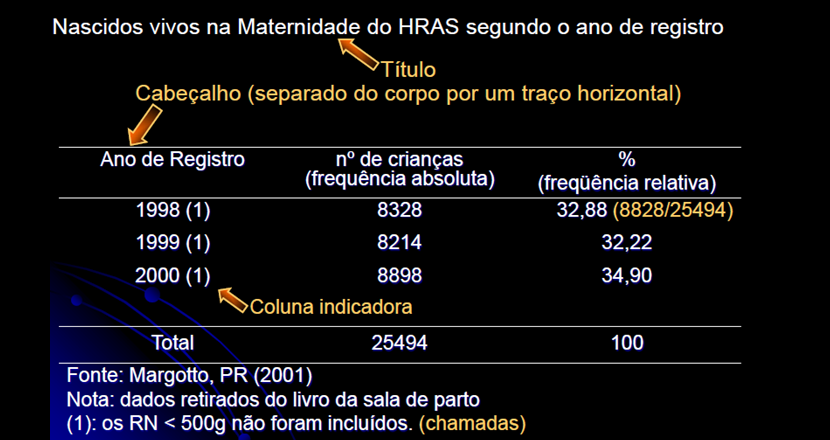{kind=link}
{kind=link}
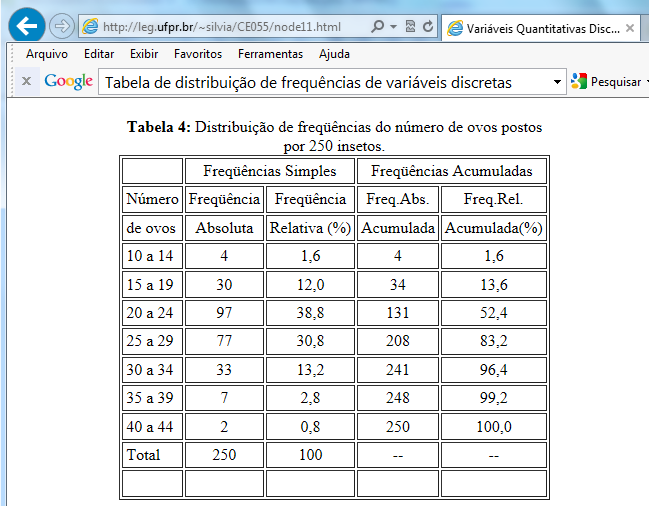{kind=link}
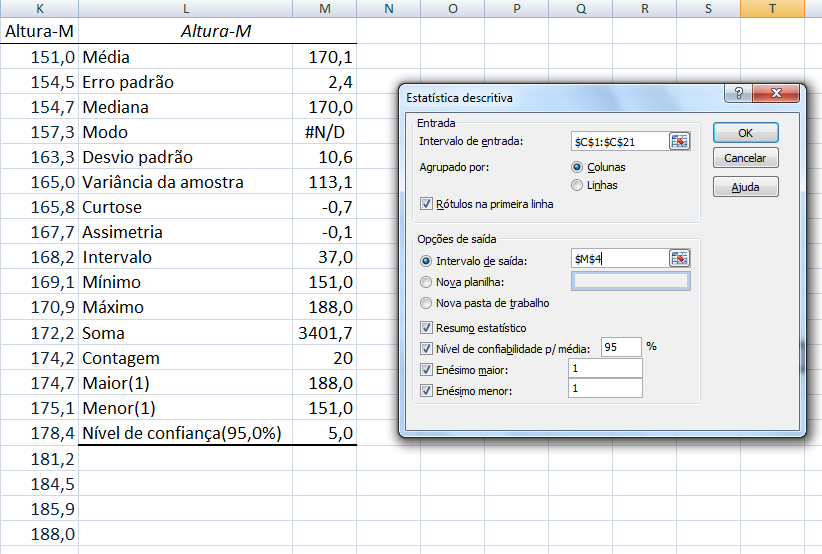{kind=link}
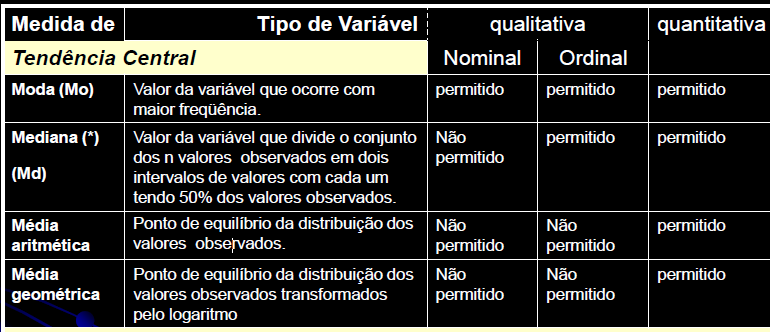{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
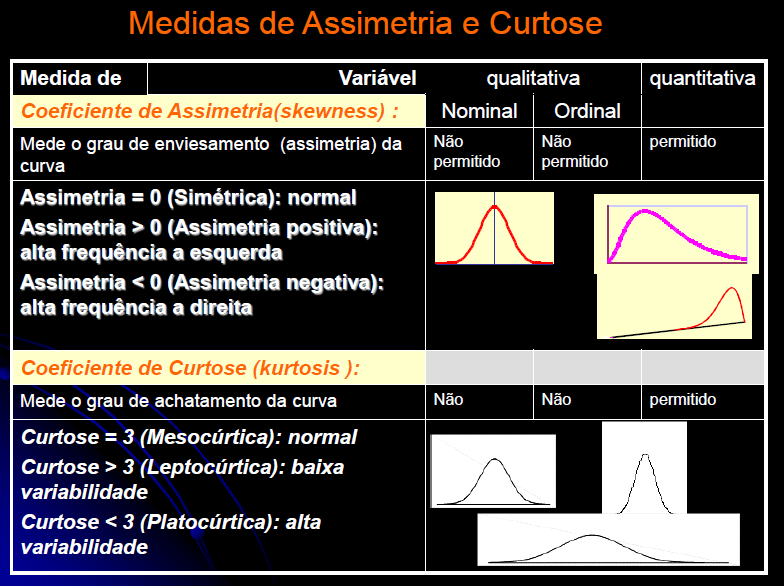{kind=link}
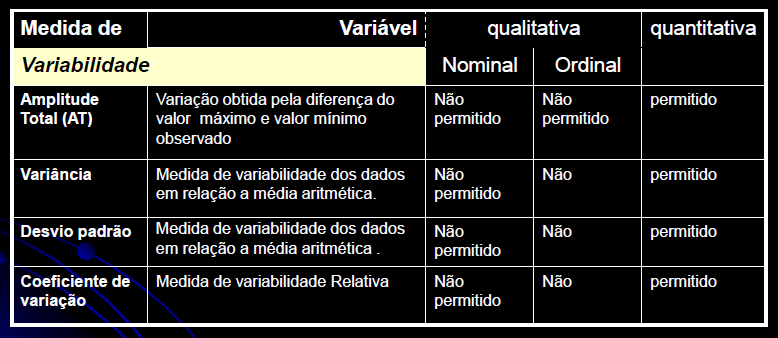{kind=link}
{kind=link}
{kind=link}
{kind=link}
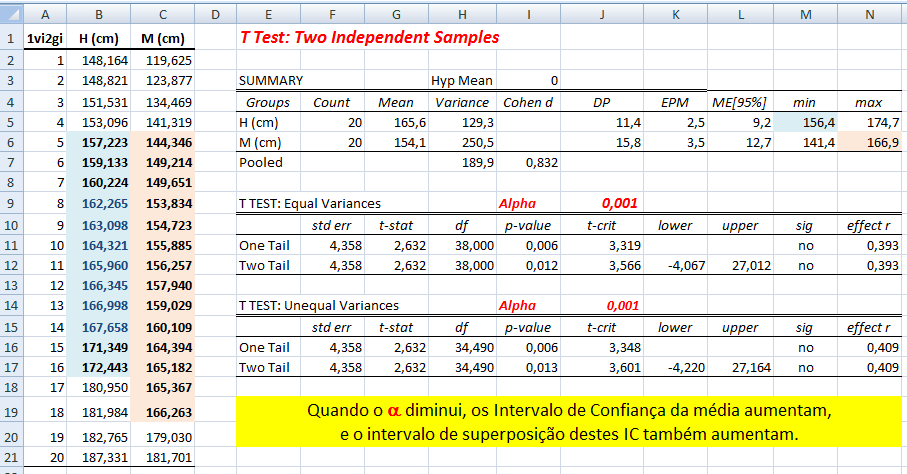{kind=link}
![IC[95%] dos valores Z = µ ± Z(α/2)*σ (α = 0,05)](./info/aula_00.png){kind=link}
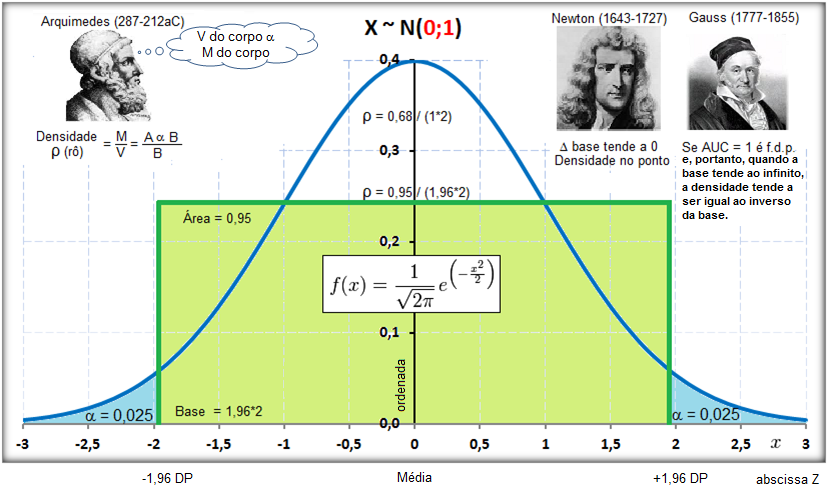{kind=link}
{kind=link}
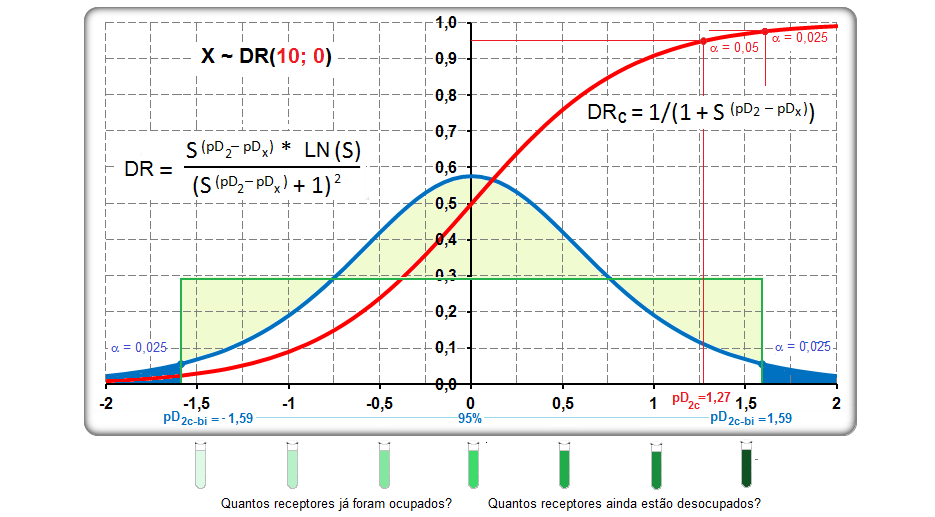{kind=link}
![IC[95%] dos valores t = X̅ ± t(gl, α/2)*S](./info/aula_02.png){kind=link}
![IC[95%] da X̅ = X̅ ± Z(α/2) * EPM (EPM = σ/√n)](./info/ic1.png){kind=link}
![IC[95%] da X̅ = X̅ ± t(gl; α/2) * EPM (EPM = S/√n)](./info/ic3.png){kind=link}
{kind=link}
![IC[95%] de ^p = ^p ± Z(α/2) * (p*(1-p) / n)^0,5](./info/modelo3.png){kind=link}
{kind=link}
![9- IC[95%] para ΔX̅s independentes com σ2s conhecidas...](./info/ic5.png){kind=link}
![10- IC[95%] para ΔX̅s independentes com σ2s equivalentes e desconhecidas...](./info/ic6.png){kind=link}
![11- IC[95%] para ΔX̅s independentes com σ2s diferentes e desconhecidas...](./info/ic7.png){kind=link}
![12- IC[95%] para a Δ^ps independentes...](./info/ic8.png){kind=link}
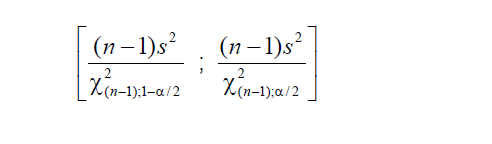{kind=link}
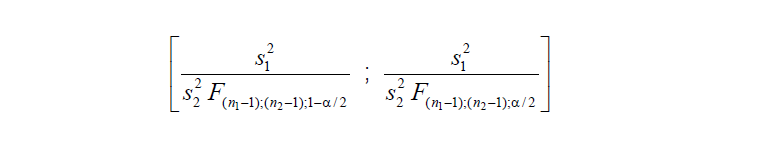{kind=link}
{kind=link}
{kind=link}
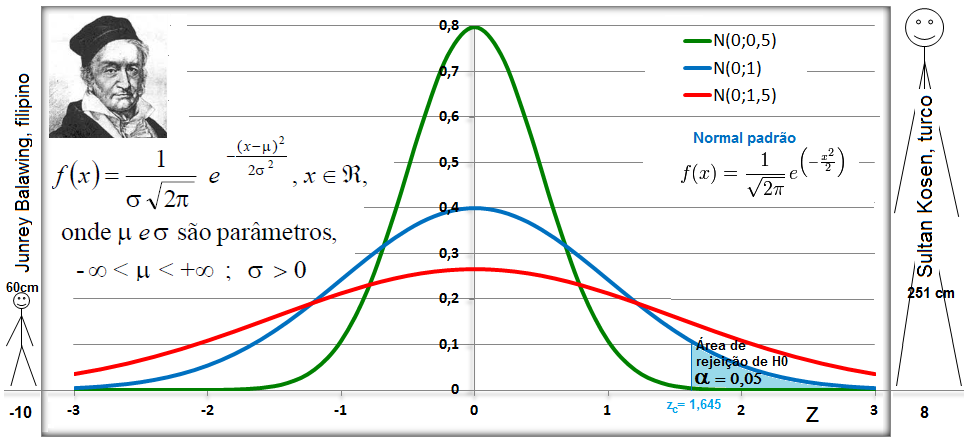{kind=link}
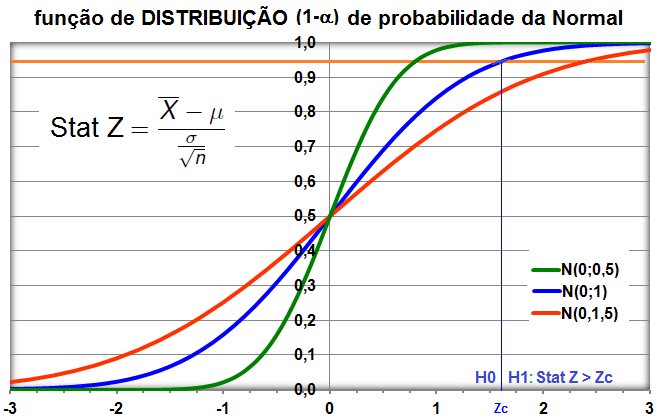{kind=link}
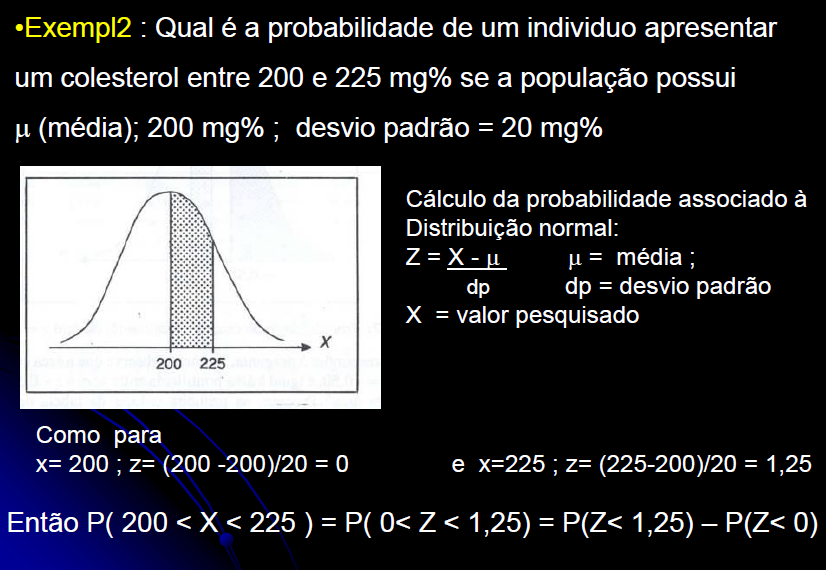{kind=link}
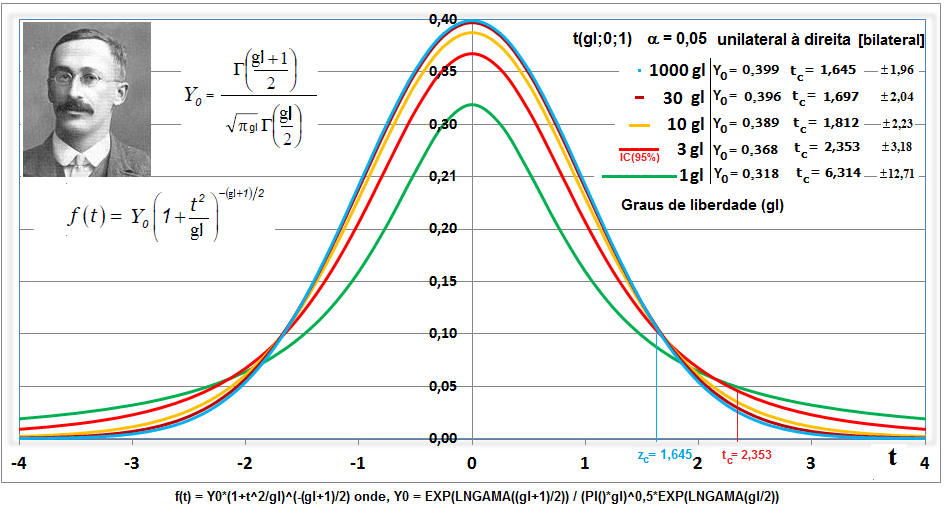{kind=link}
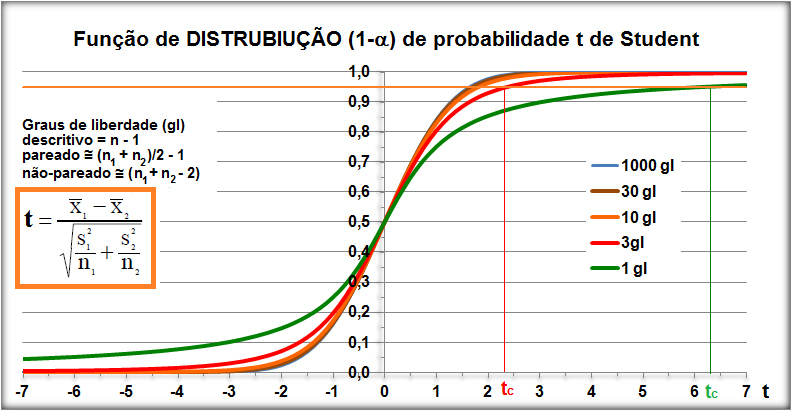{kind=link}
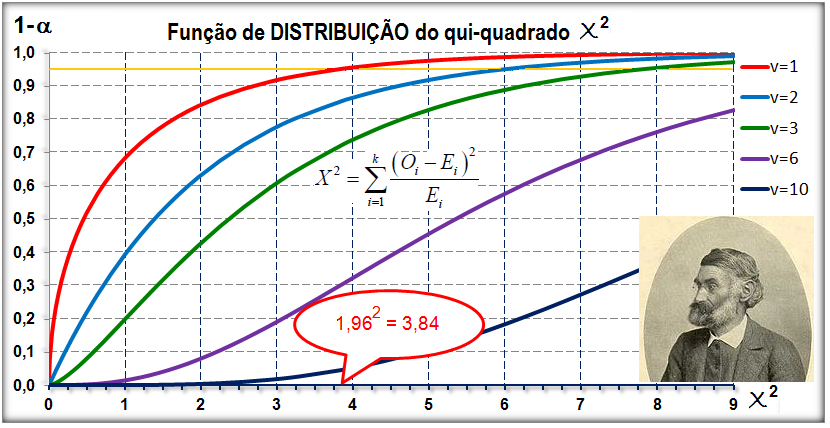{kind=link}
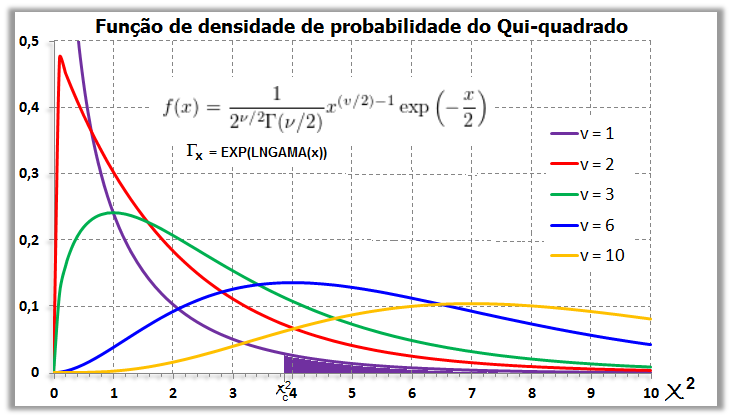{kind=link}
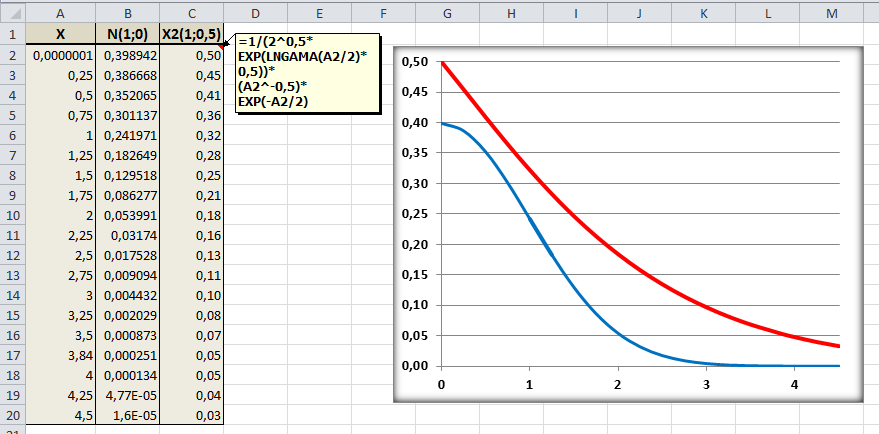{kind=link}
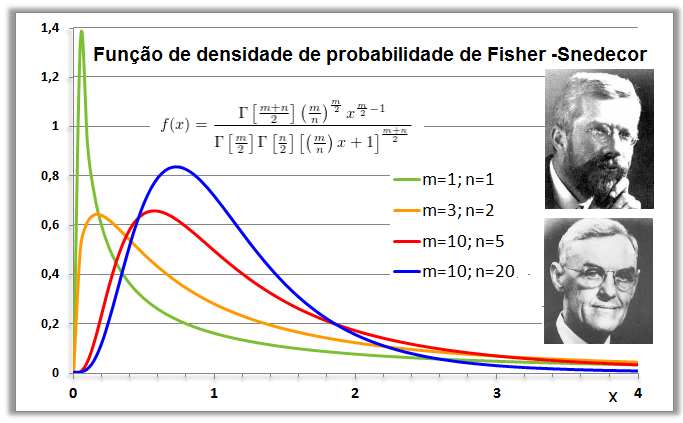{kind=link}
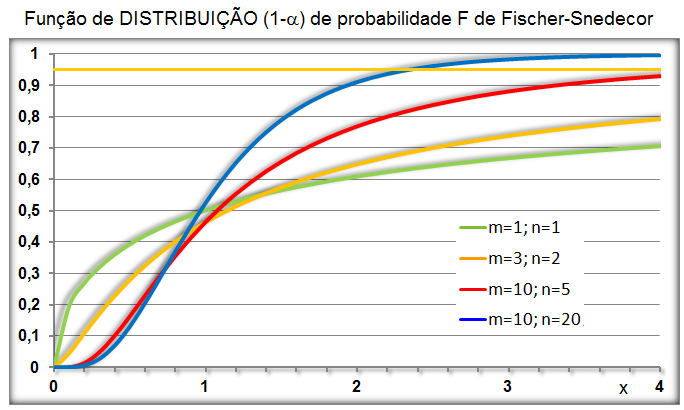{kind=link}
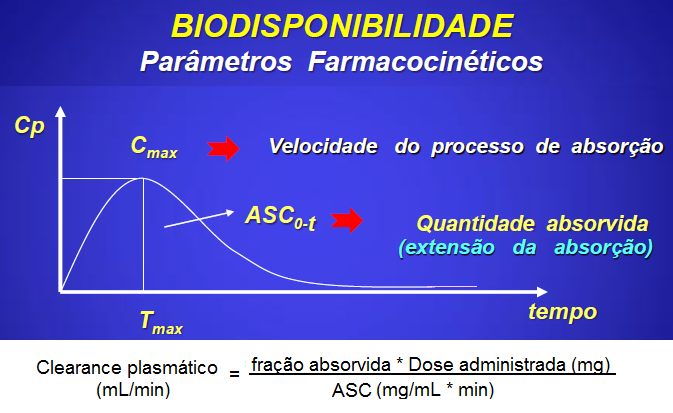{kind=link}
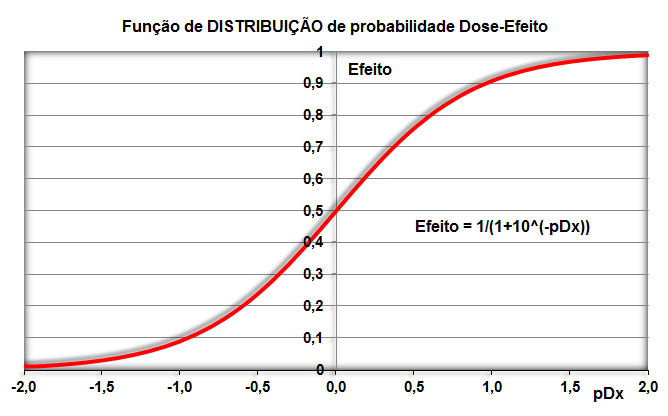{kind=link}
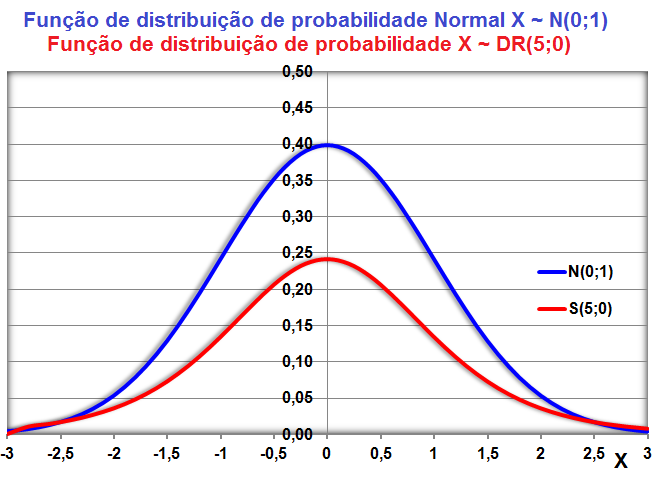{kind=link}
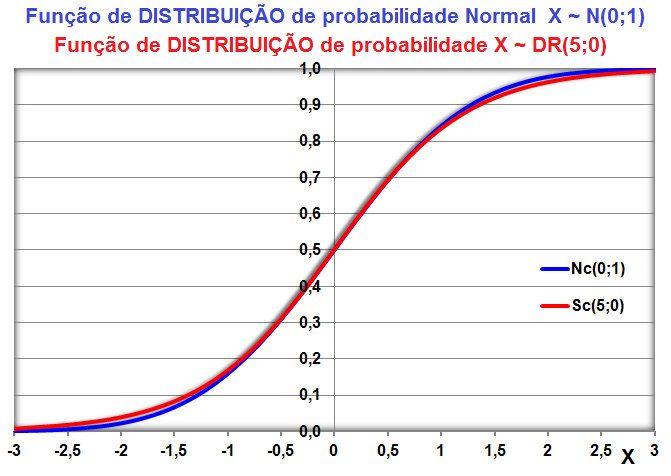{kind=link}
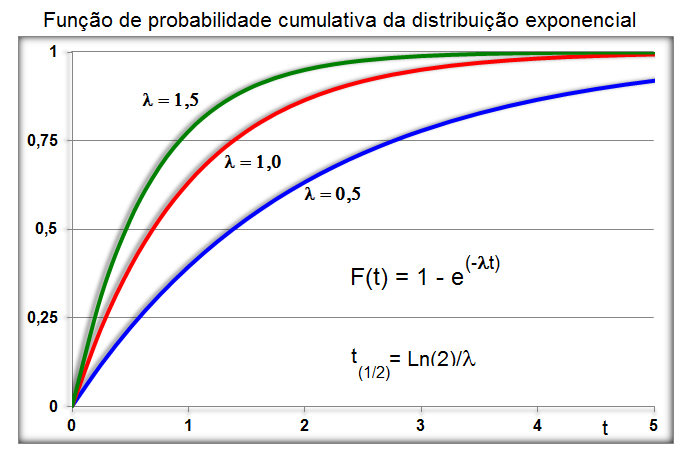{kind=link}
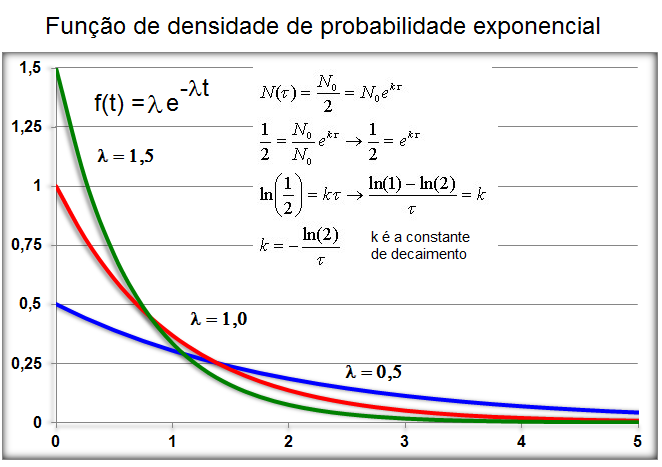{kind=link}
{kind=link}
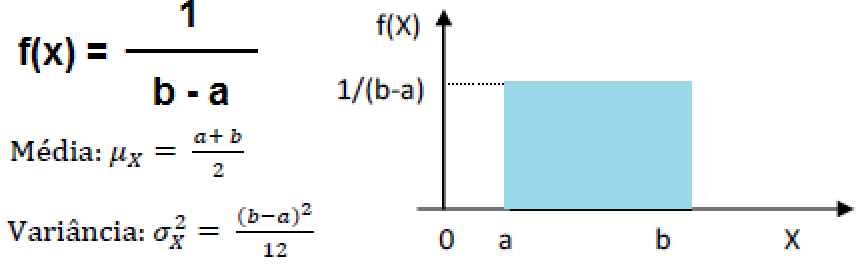{kind=link}
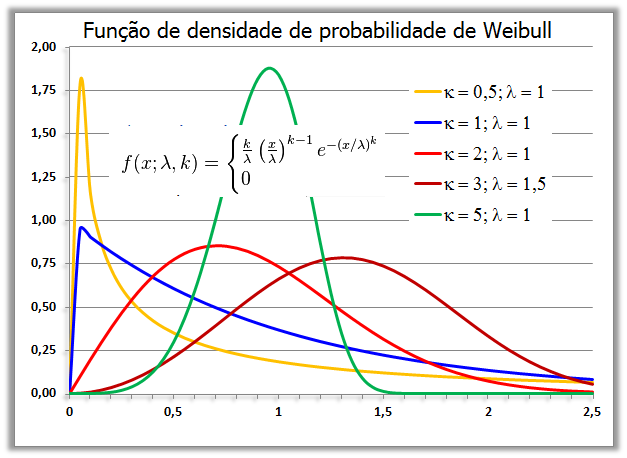{kind=link}
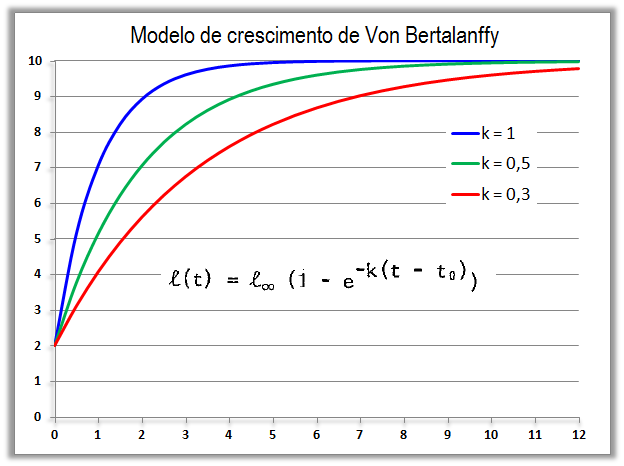{kind=link}
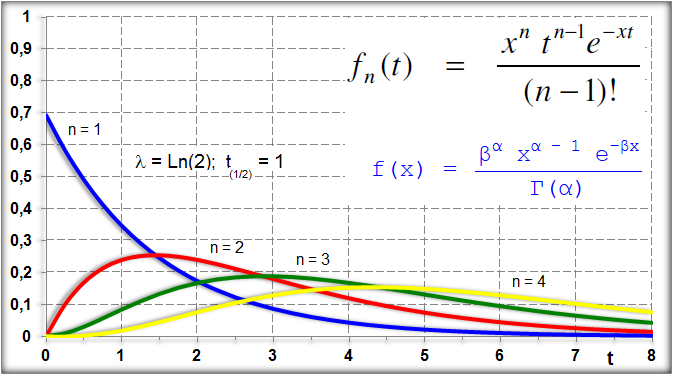{kind=link}
{kind=link}
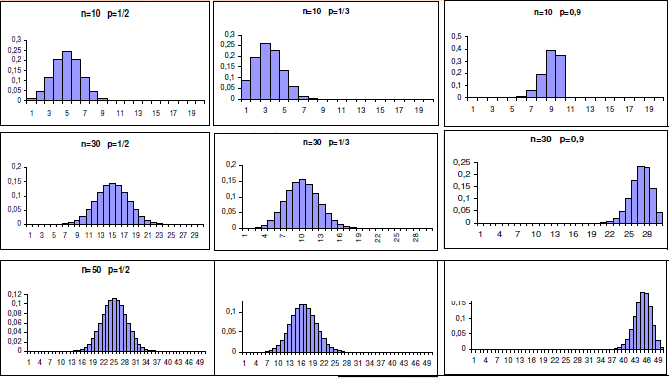{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
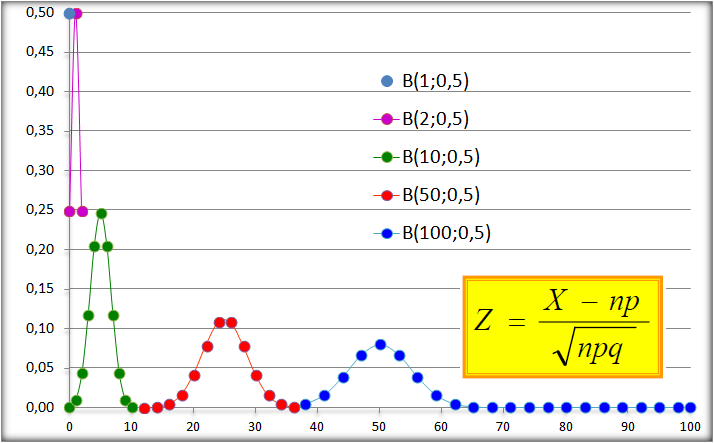{kind=link}
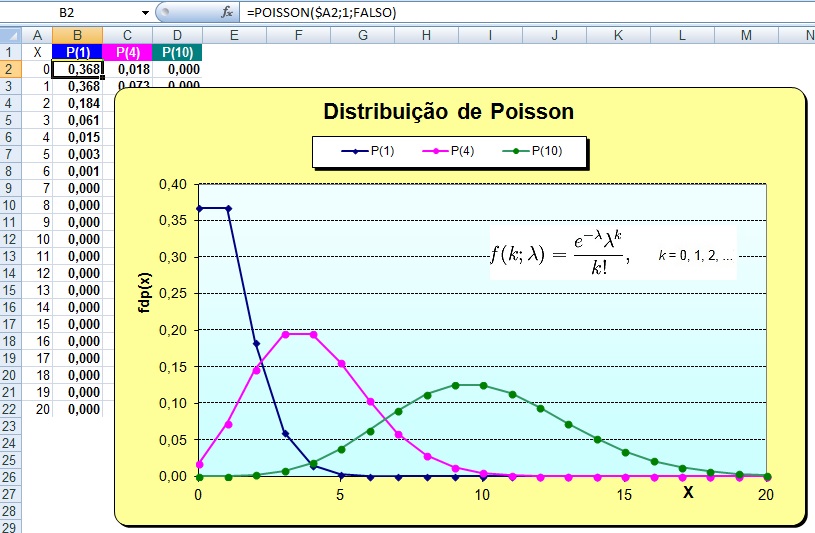{kind=link}
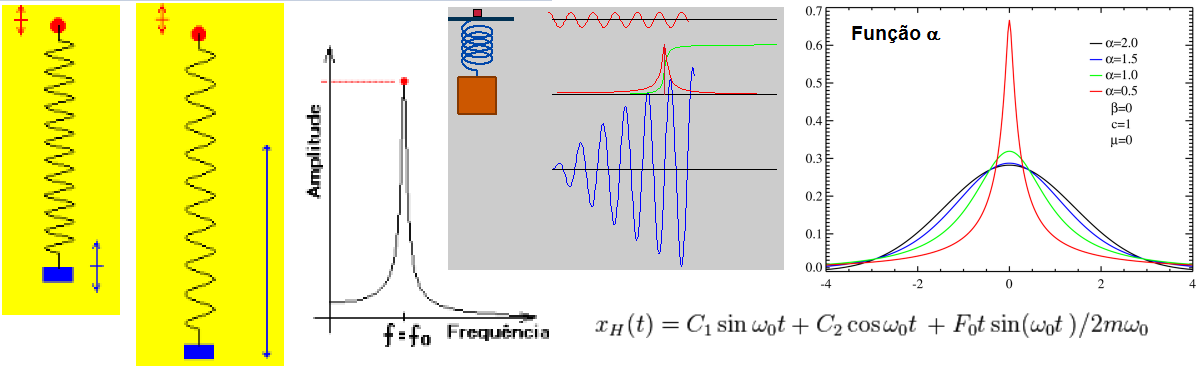{kind=link}
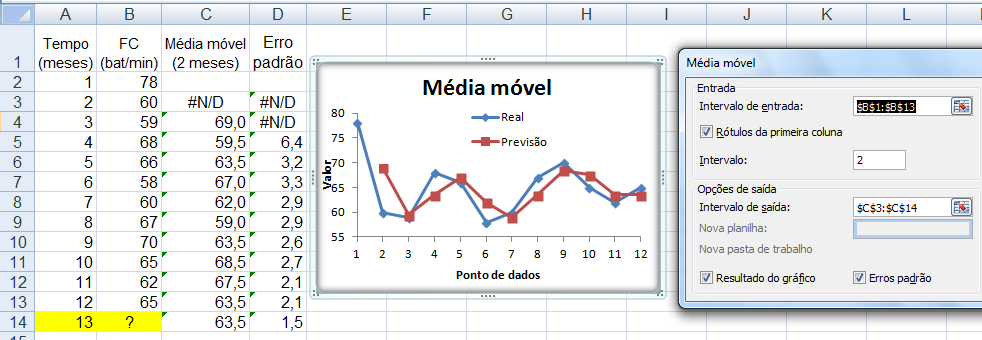{kind=link}
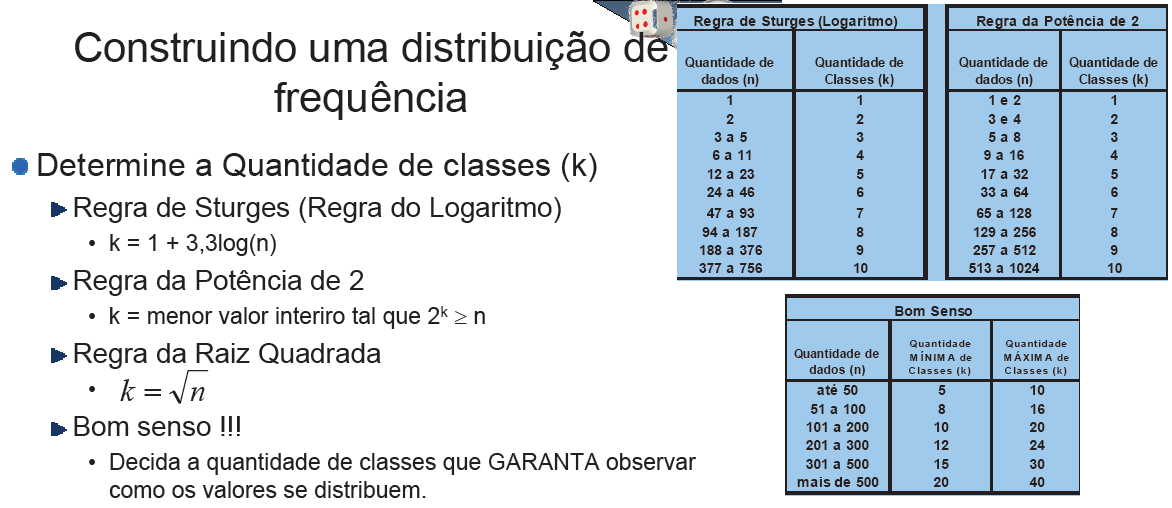{kind=link}
{kind=link}
{kind=link}
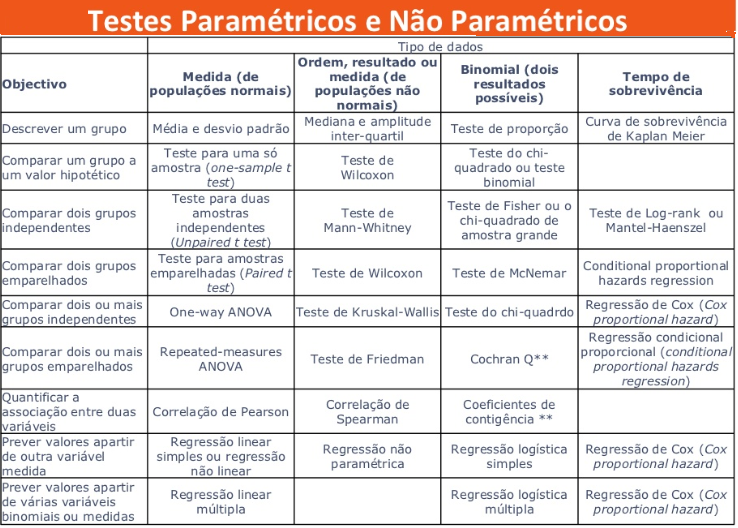{kind=link}
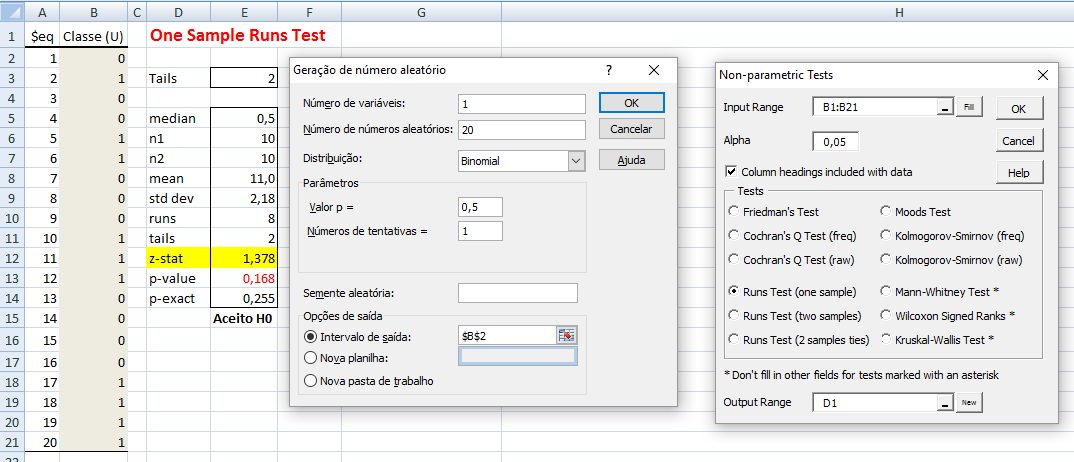{kind=link}
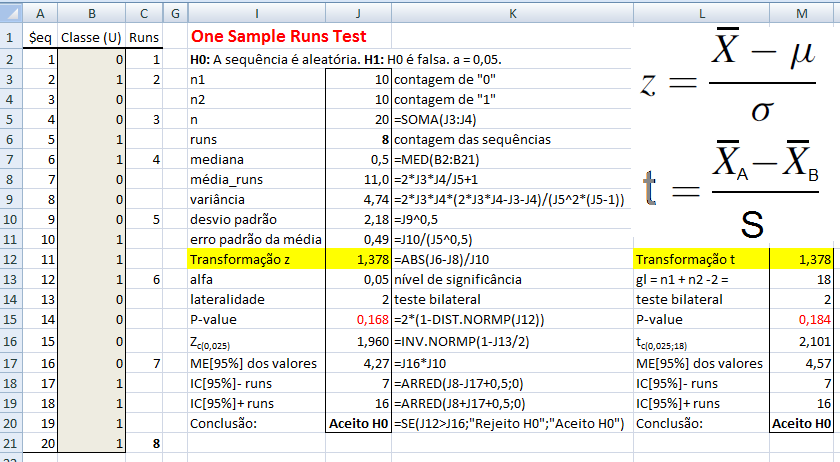{kind=link}
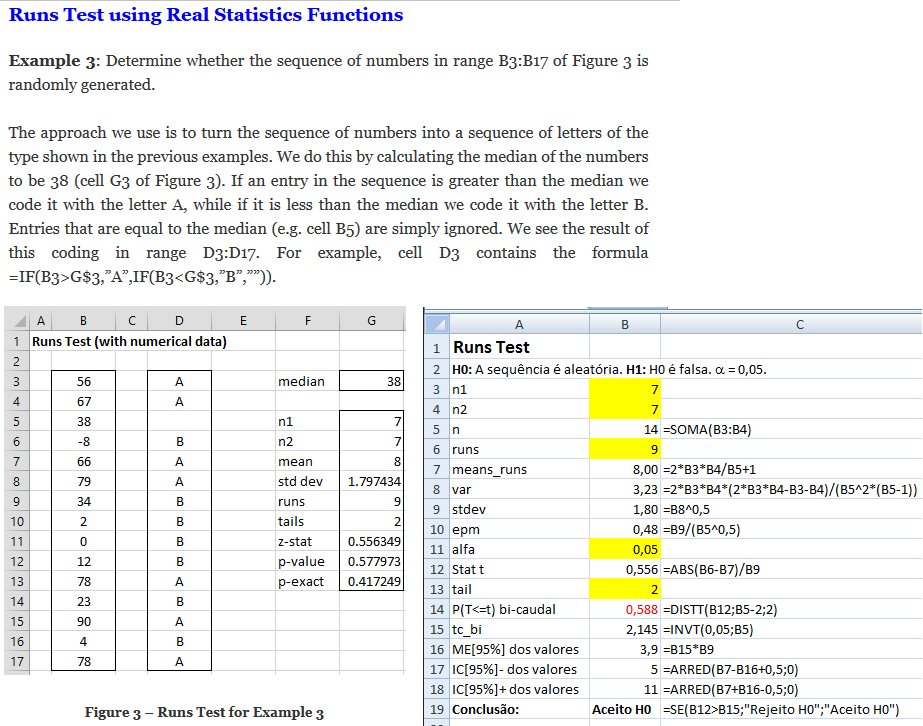{kind=link}
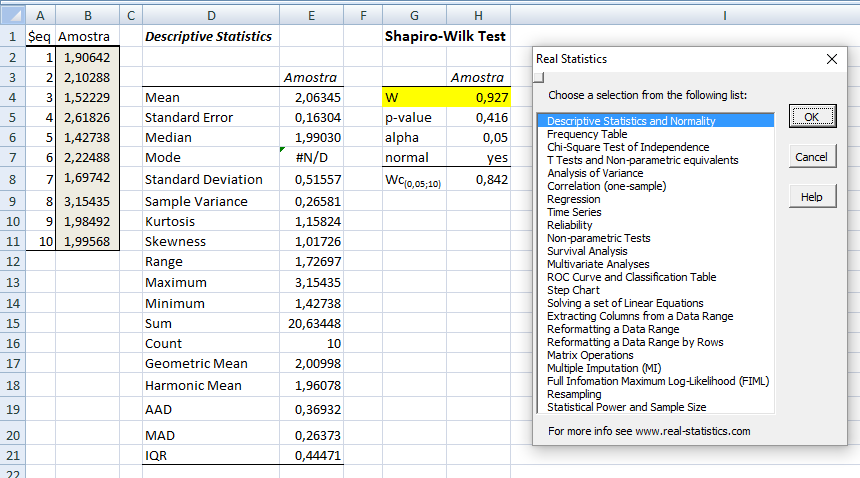{kind=link}
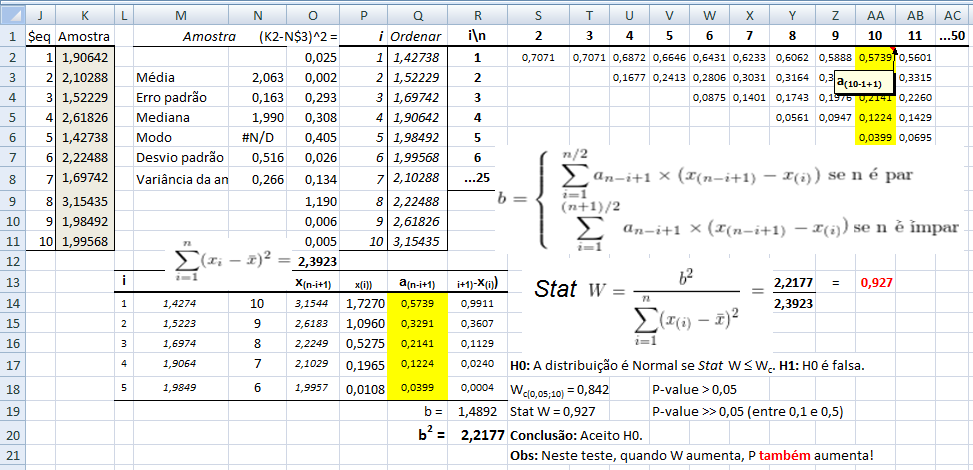{kind=link}
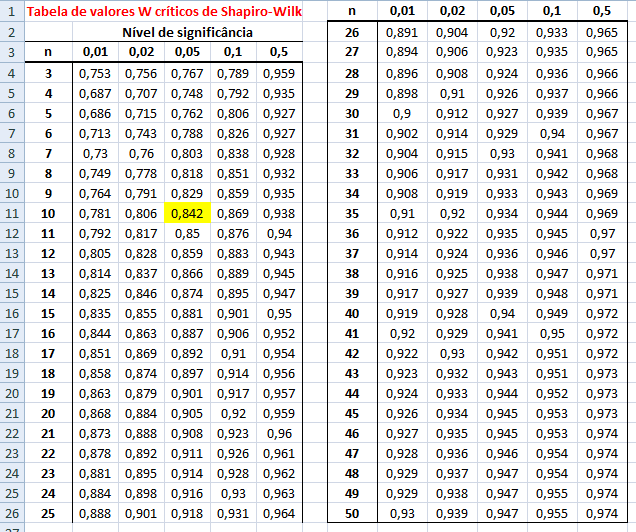{kind=link}
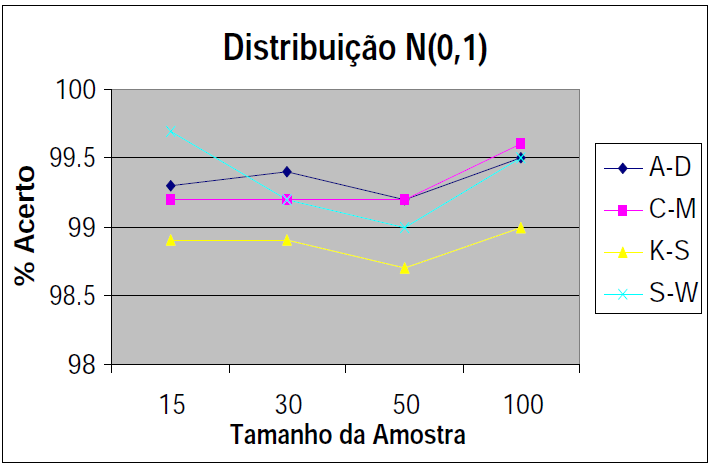{kind=link}
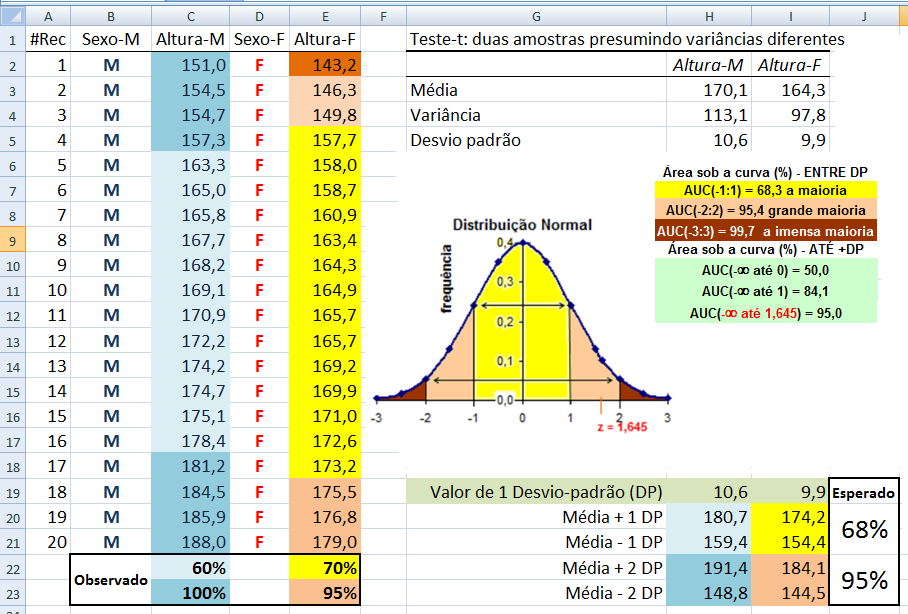{kind=link}
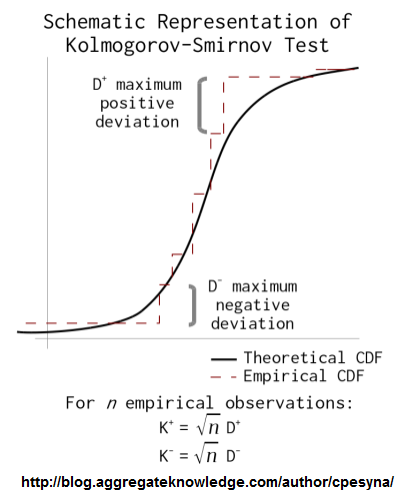{kind=link}
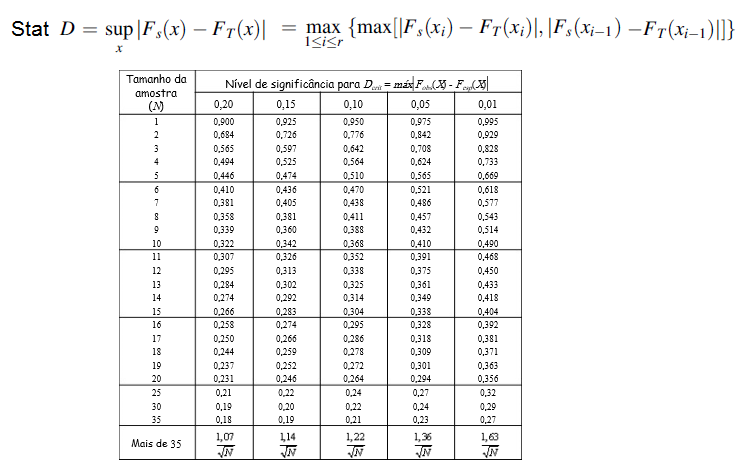{kind=link}
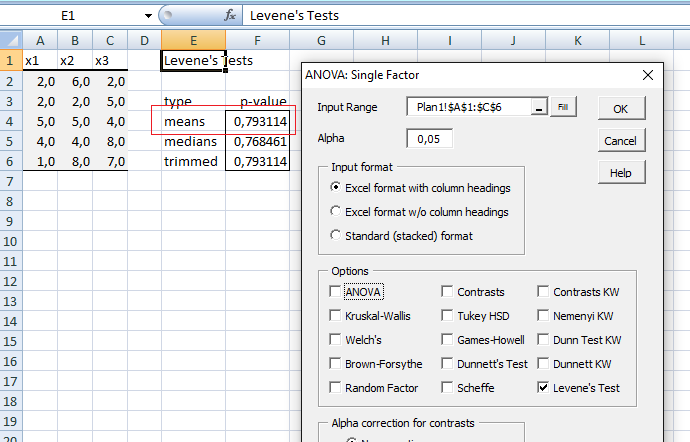{kind=link}
{kind=link}
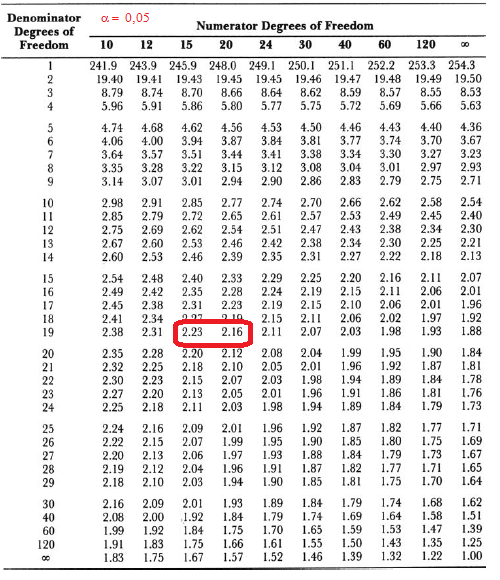{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
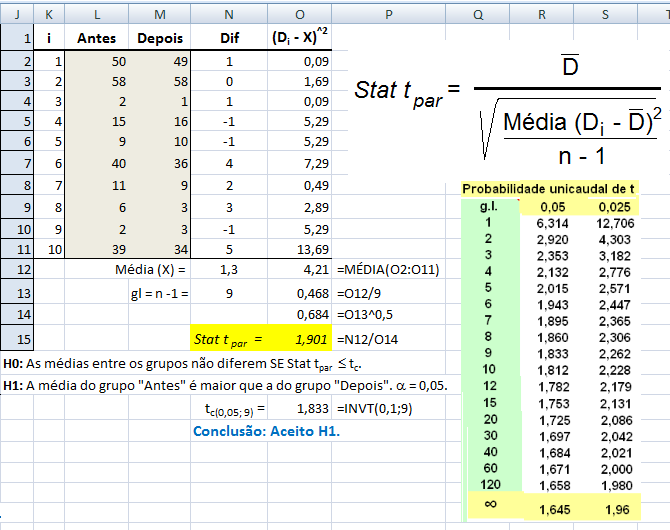{kind=link}
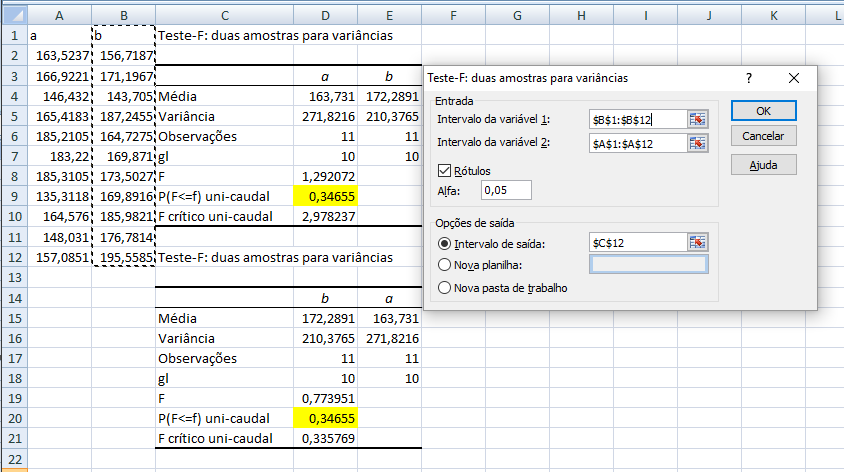{kind=link}
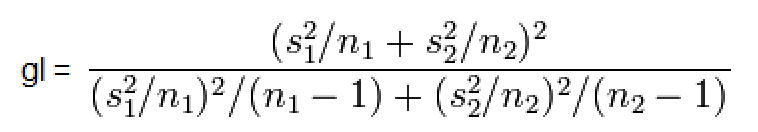{kind=link}
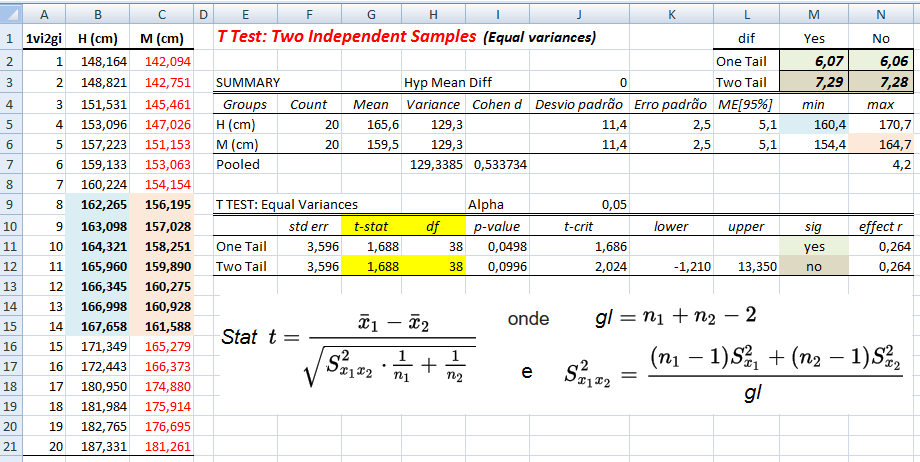{kind=link}
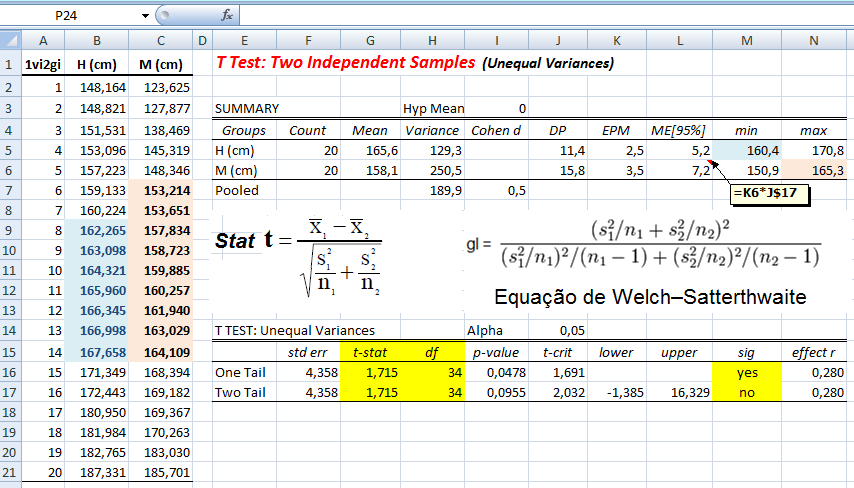{kind=link}
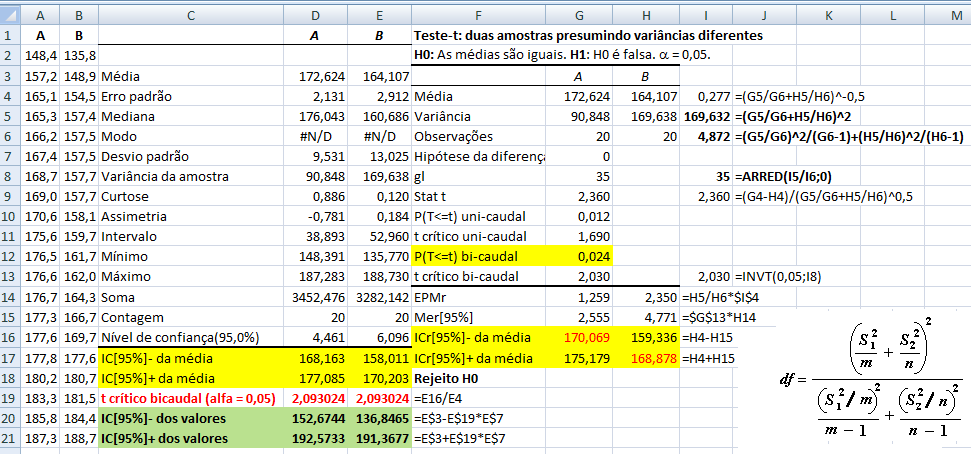{kind=link}
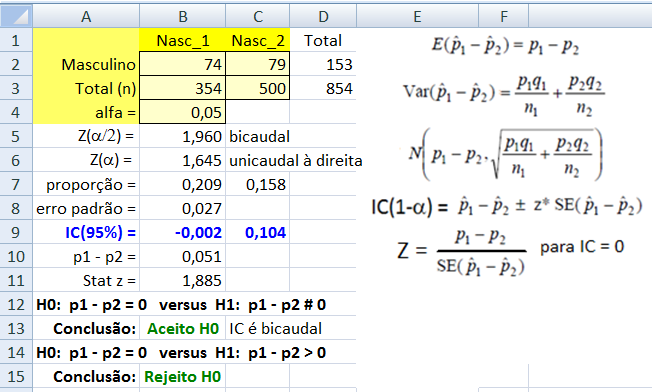{kind=link}
{kind=link}
{kind=link}
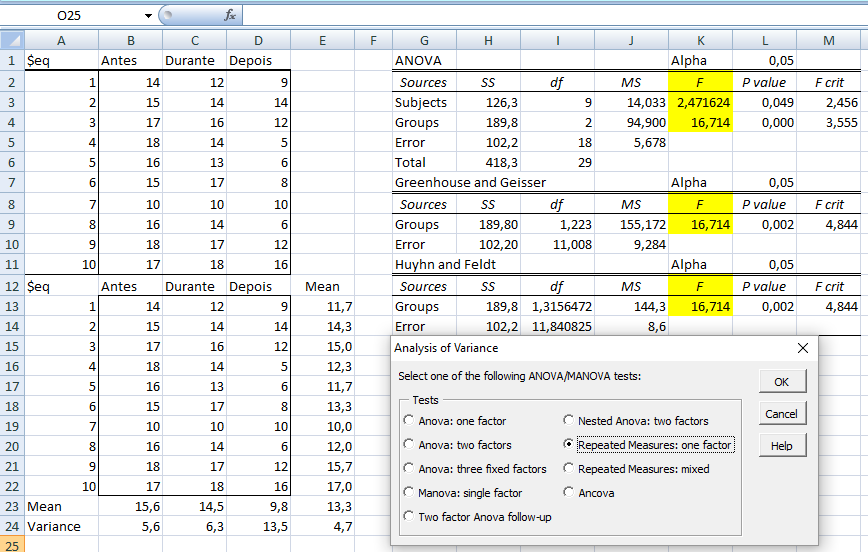{kind=link}
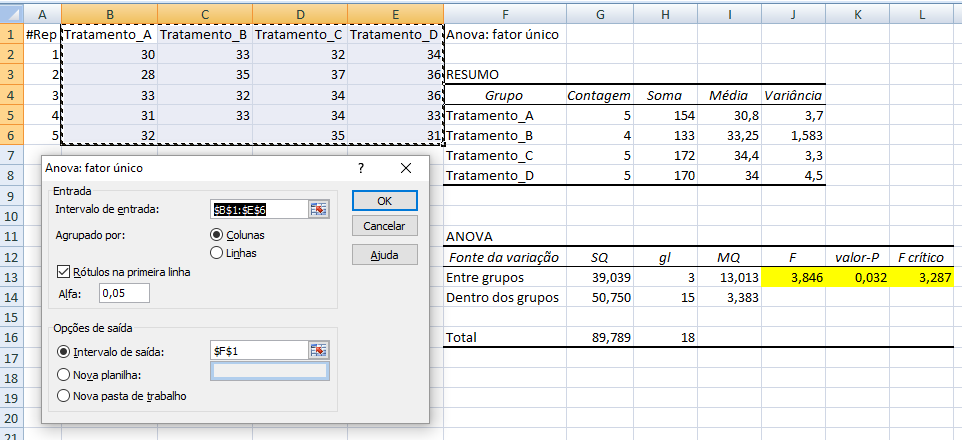{kind=link}
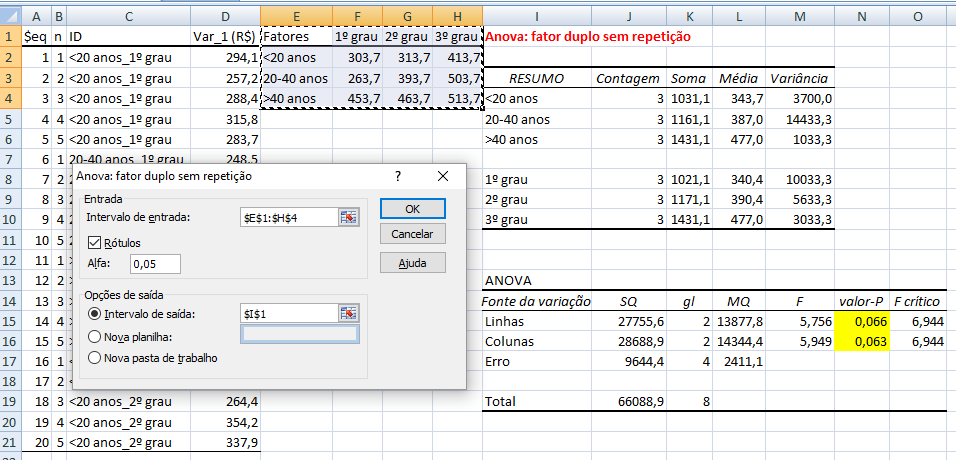{kind=link}
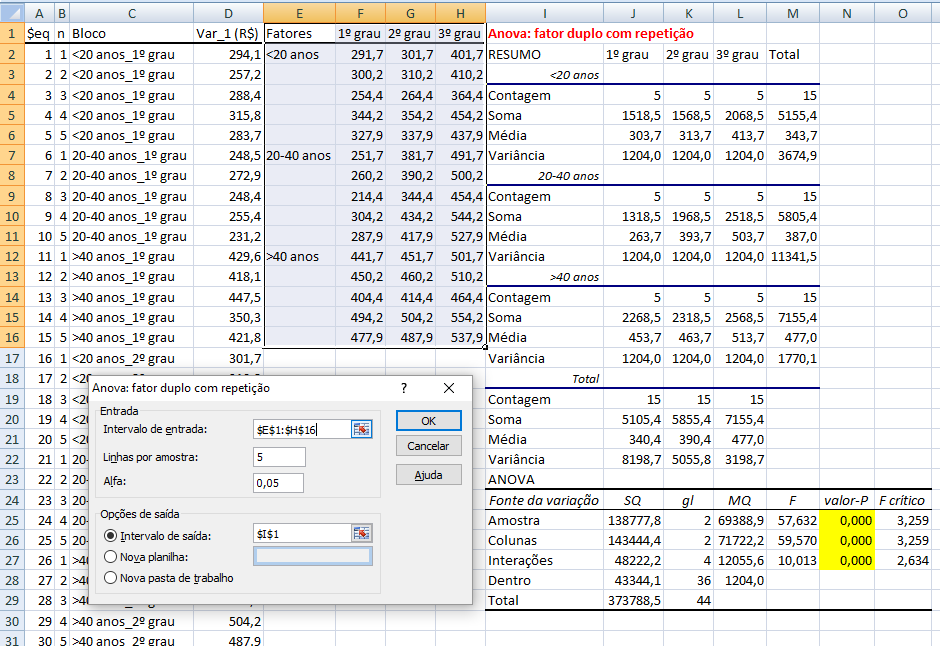{kind=link}
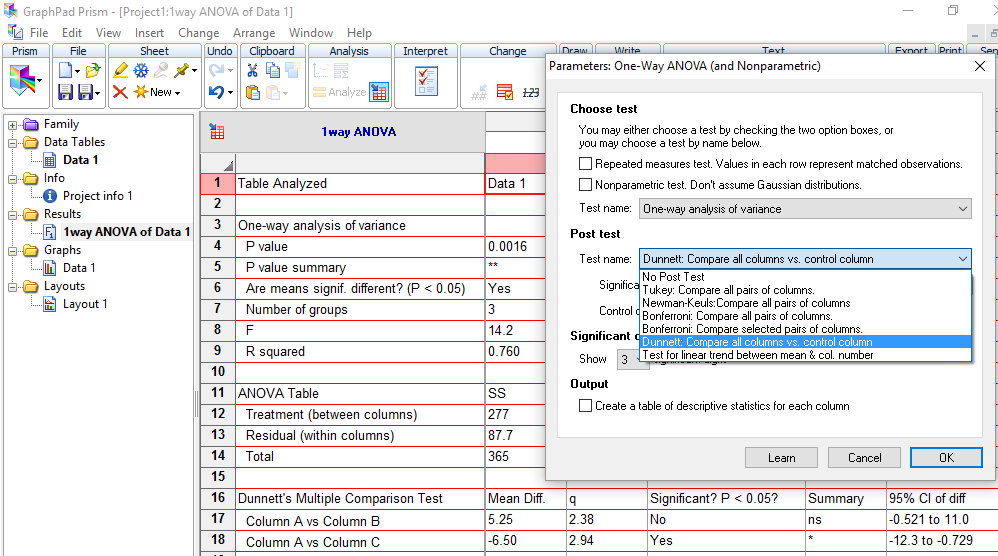{kind=link}
{kind=link}
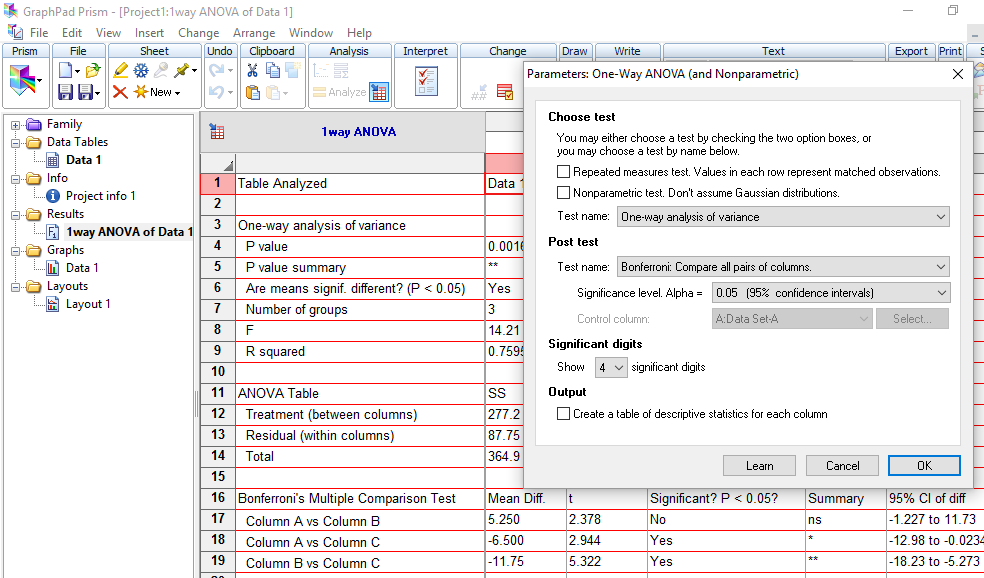{kind=link}
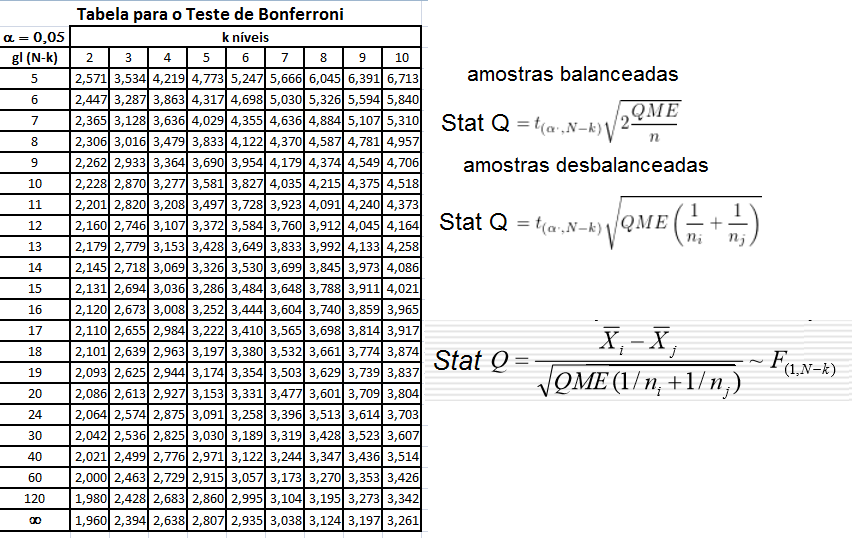{kind=link}
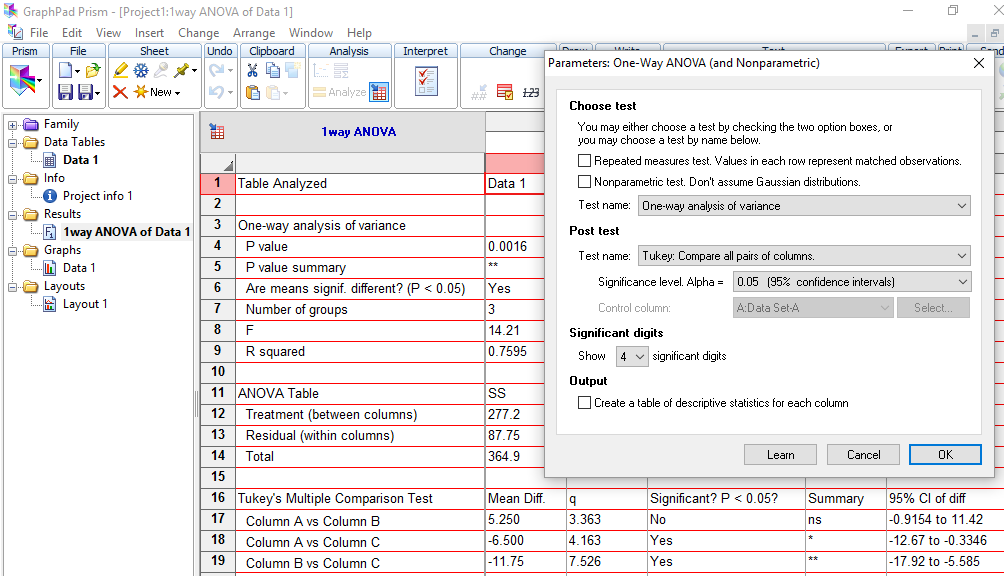{kind=link}
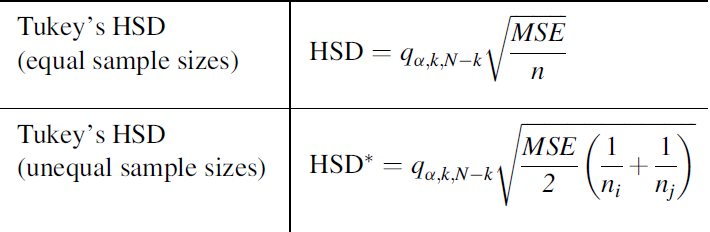{kind=link}
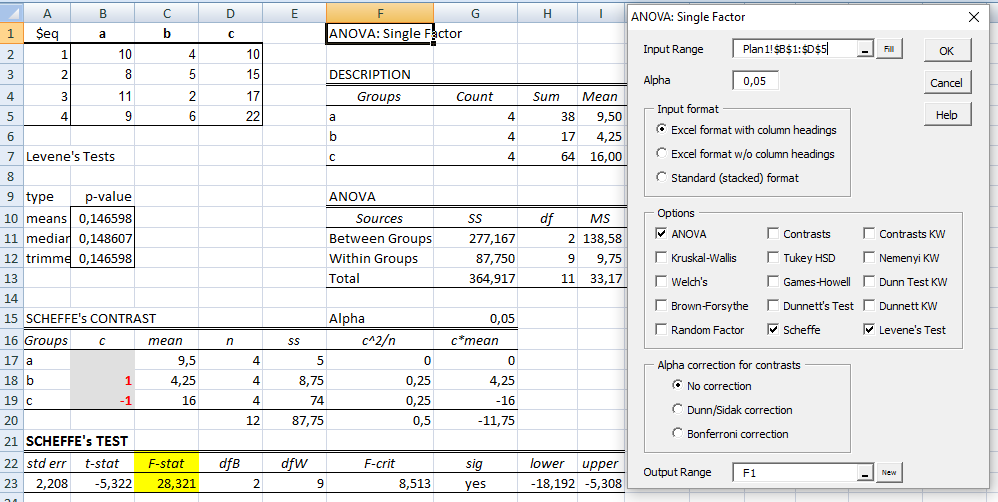{kind=link}
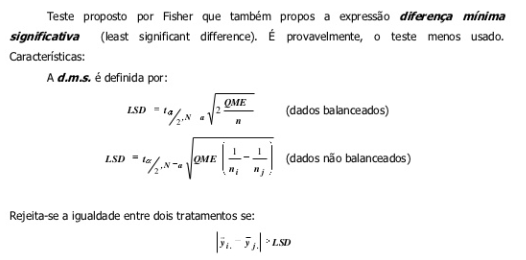{kind=link}
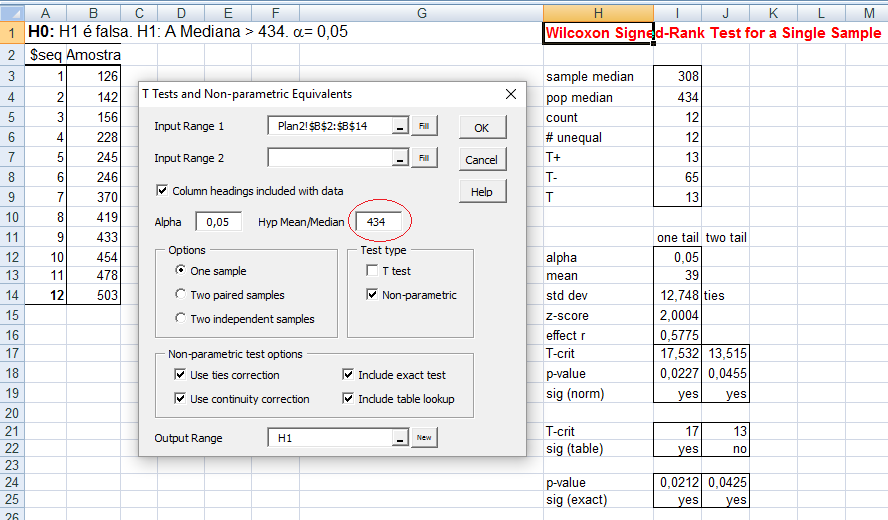{kind=link}
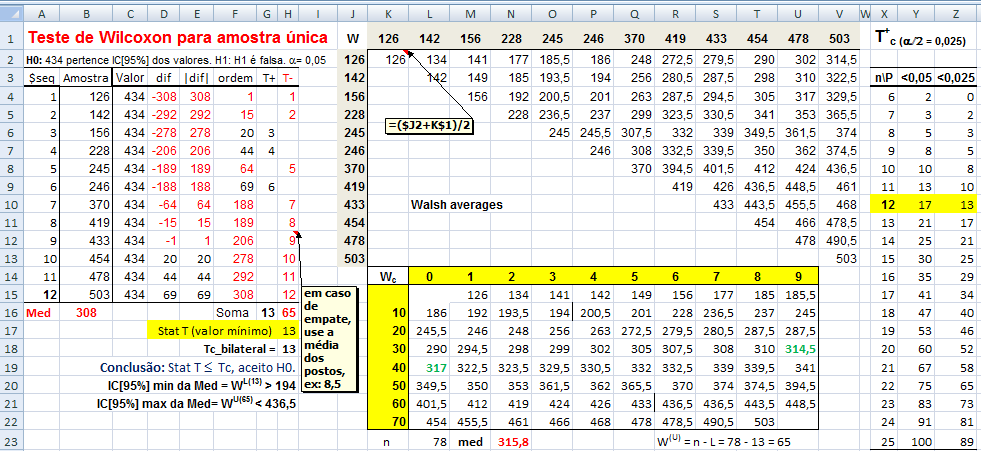{kind=link}
{kind=link}
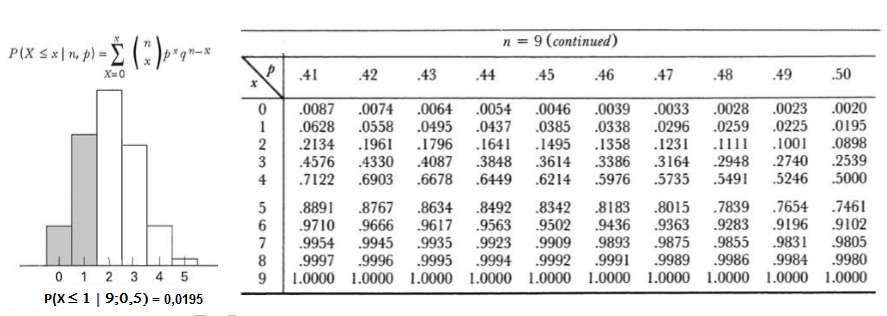{kind=link}
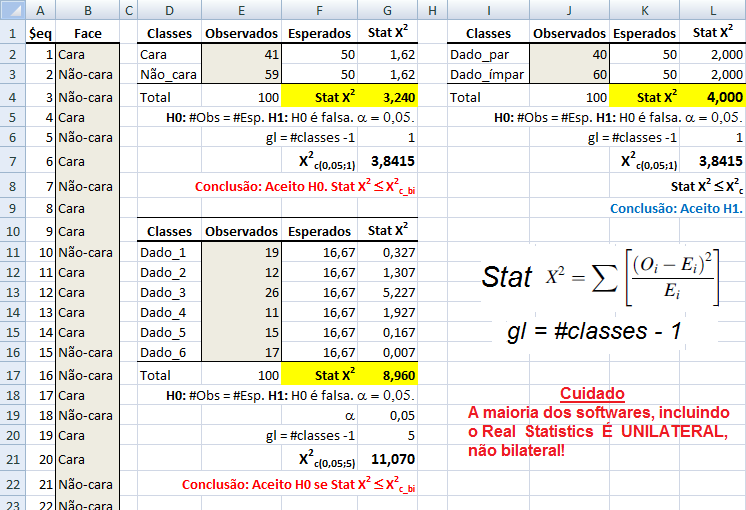{kind=link}
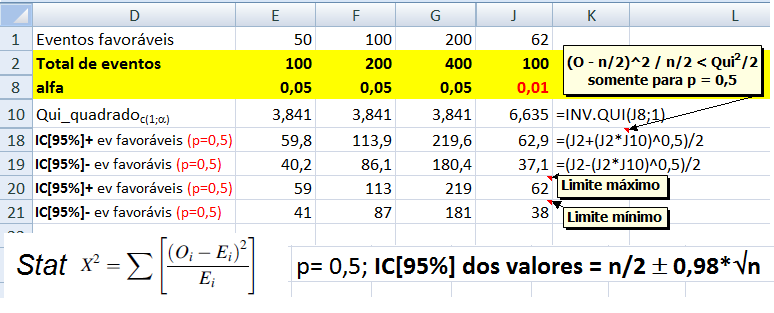{kind=link}
{kind=link}
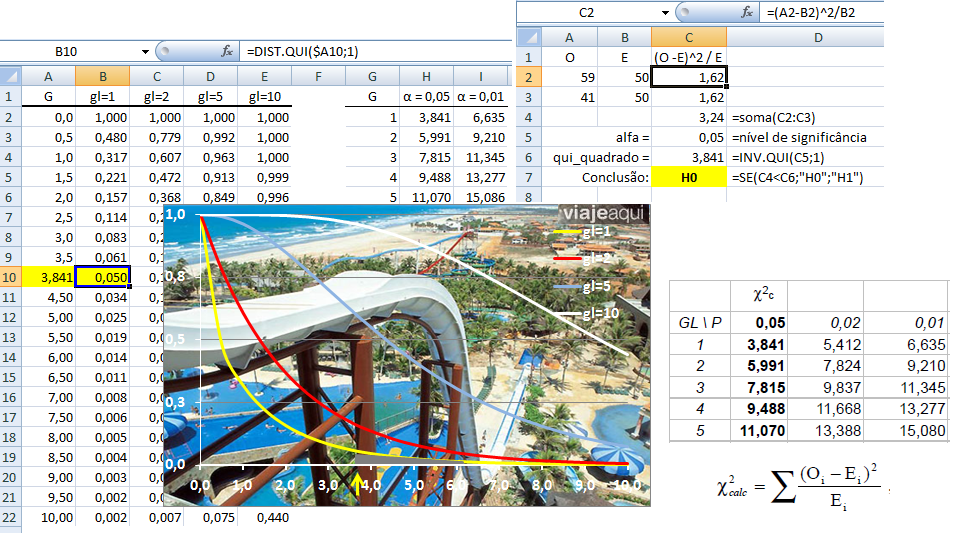{kind=link}
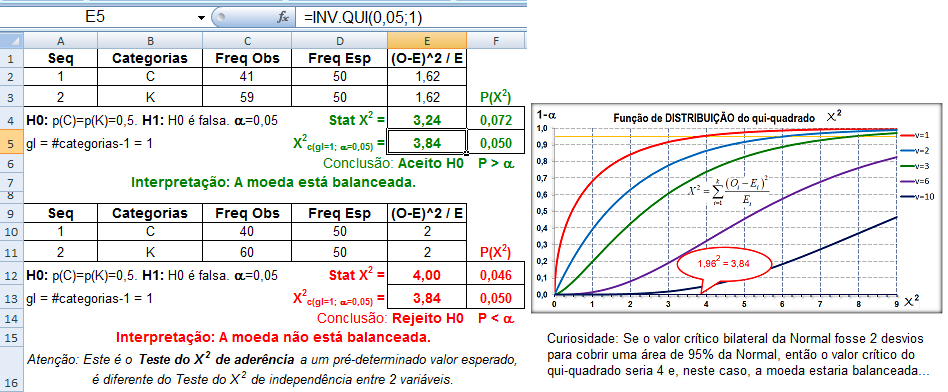{kind=link}
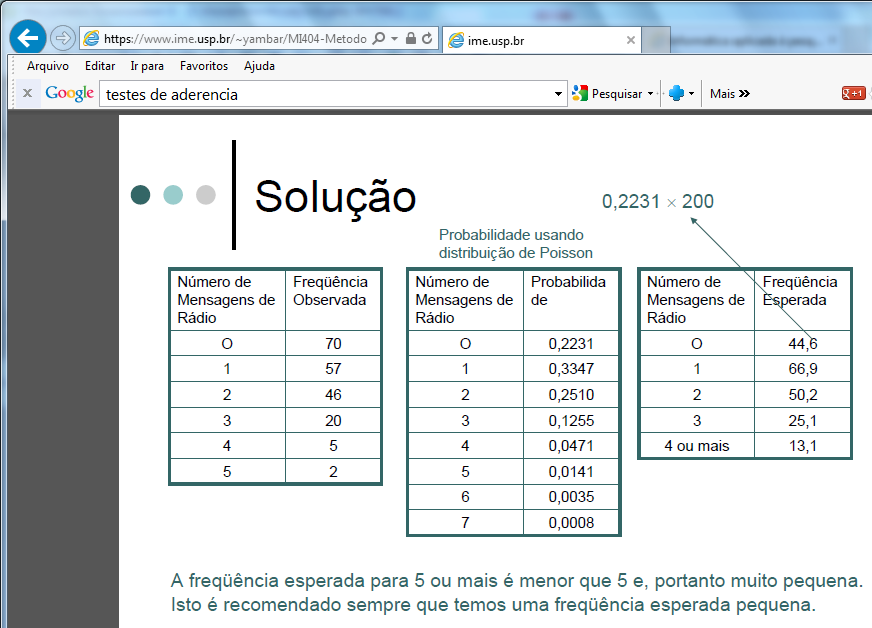{kind=link}
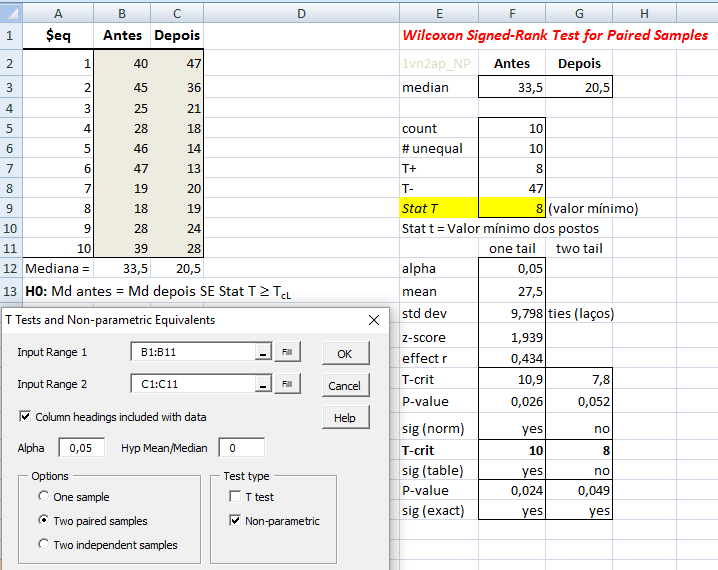{kind=link}
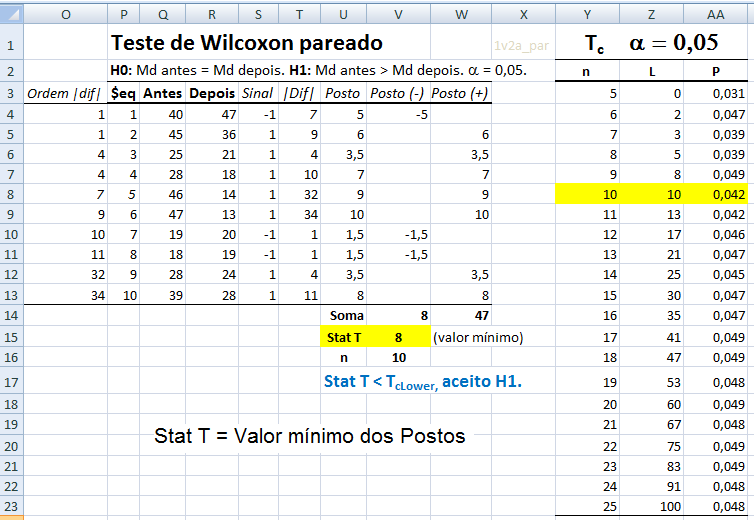{kind=link}
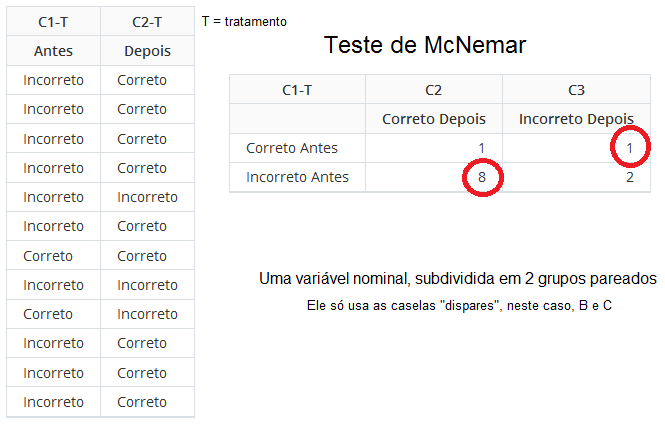{kind=link}
{kind=link}
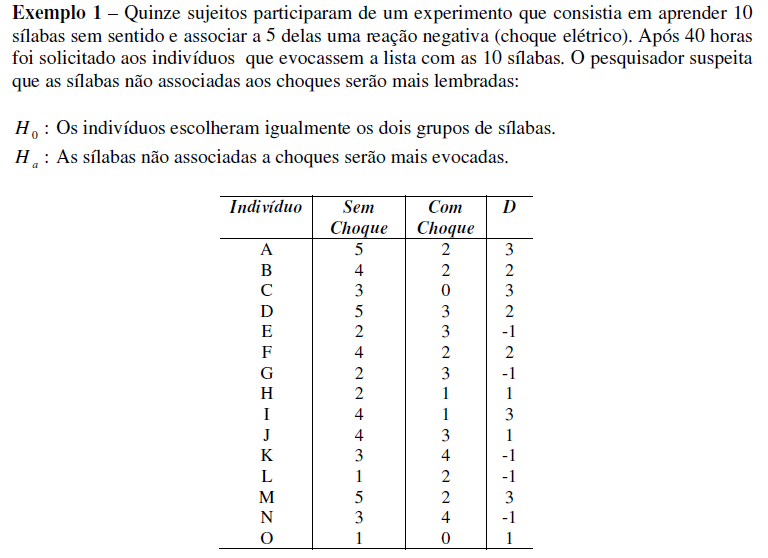{kind=link}
{kind=link}
{kind=link}
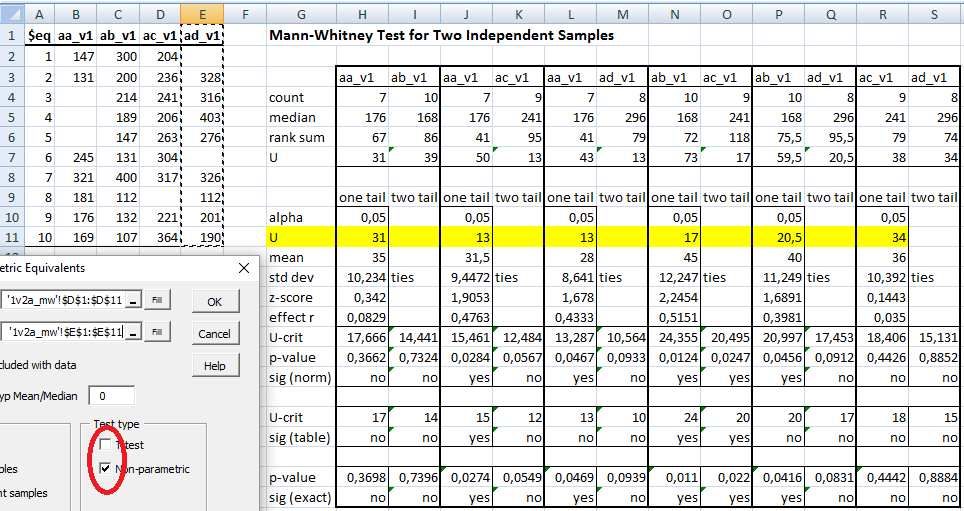{kind=link}
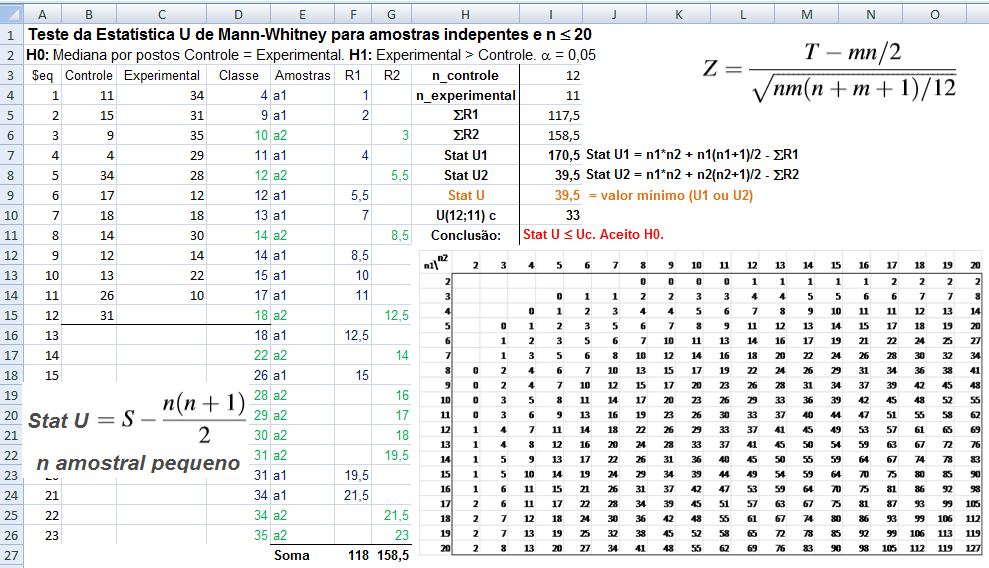{kind=link}
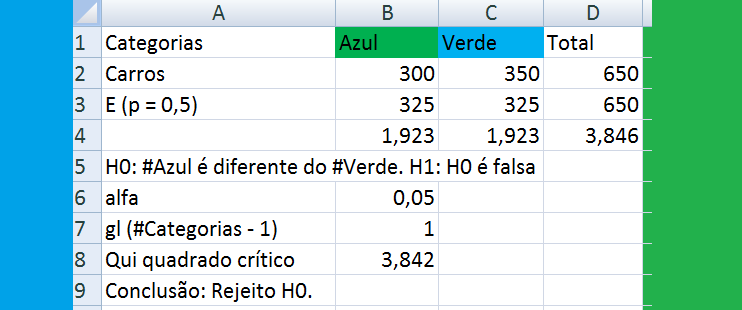{kind=link}
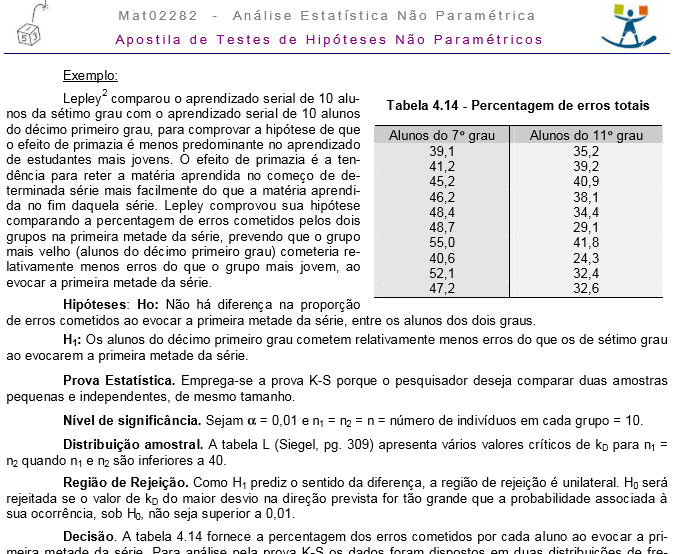{kind=link}
{kind=link}
{kind=link}
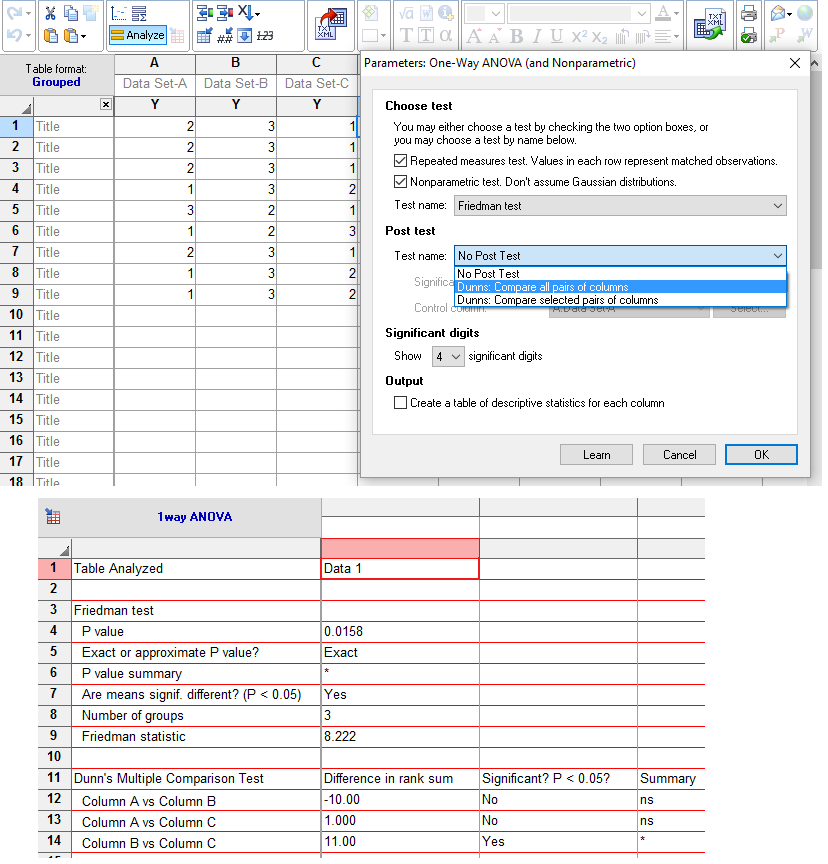{kind=link}
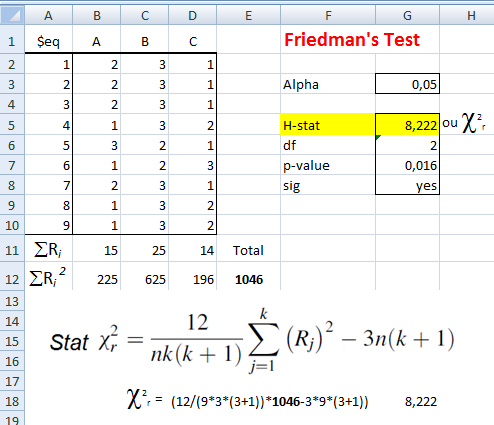{kind=link}
{kind=link}
{kind=link}
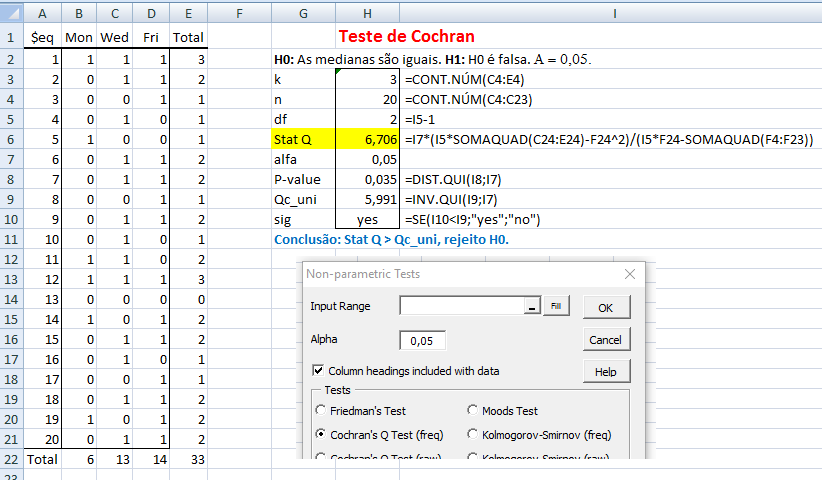{kind=link}
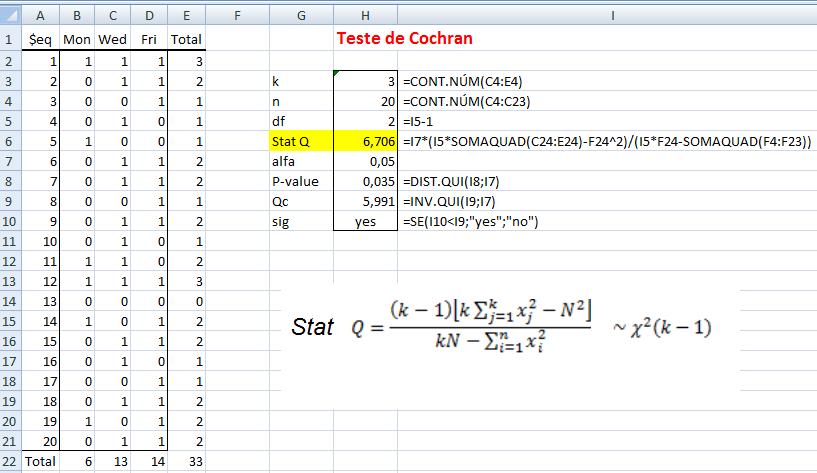{kind=link}
{kind=link}
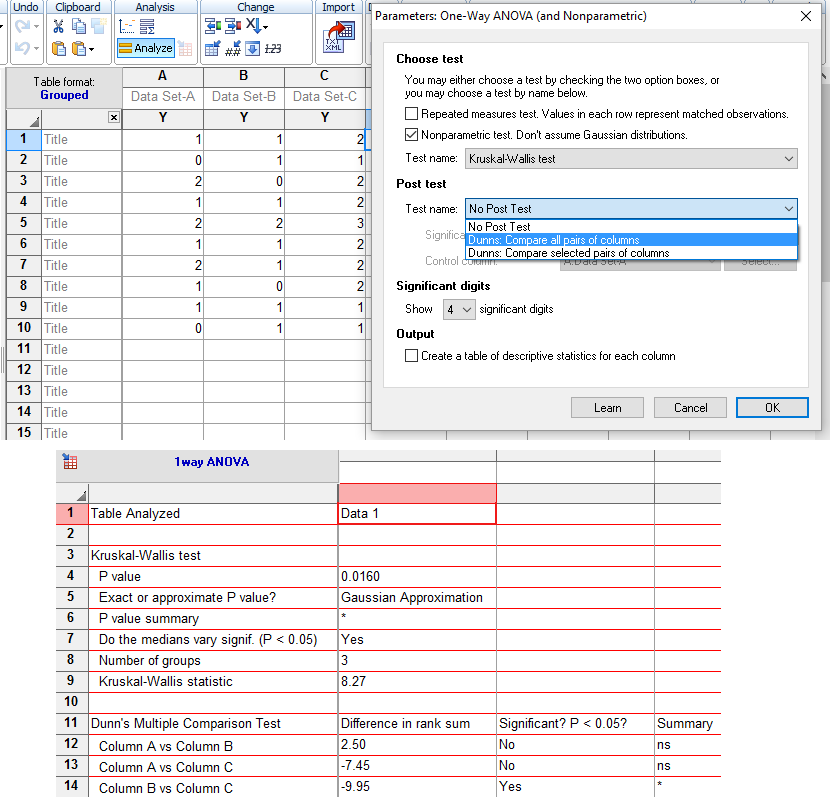{kind=link}
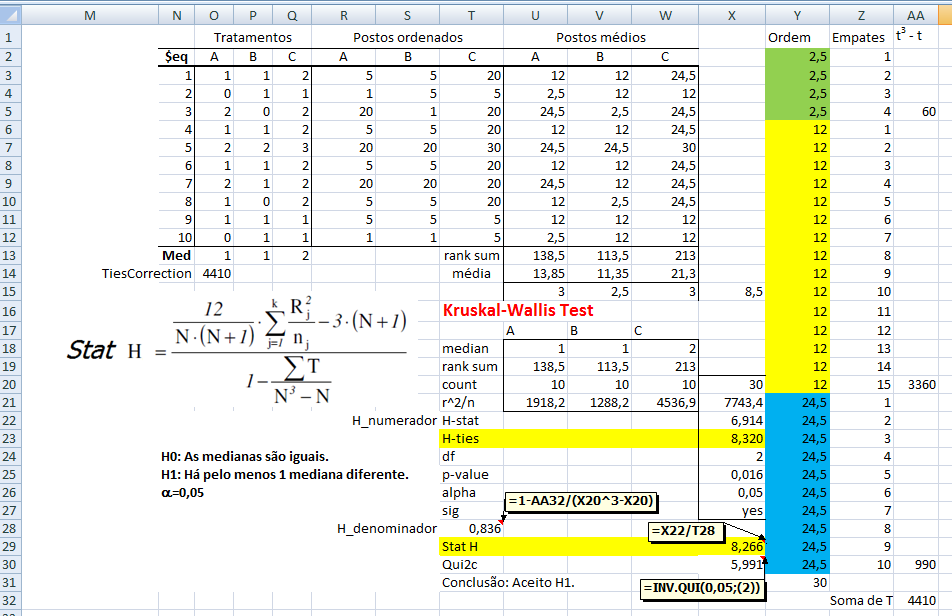{kind=link}
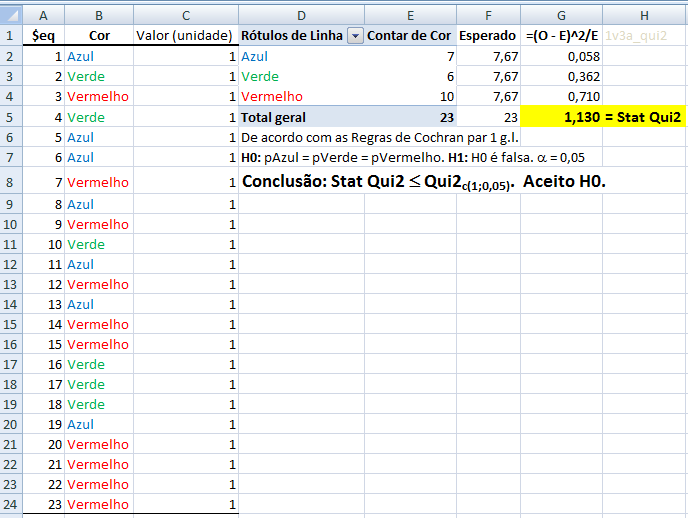{kind=link}
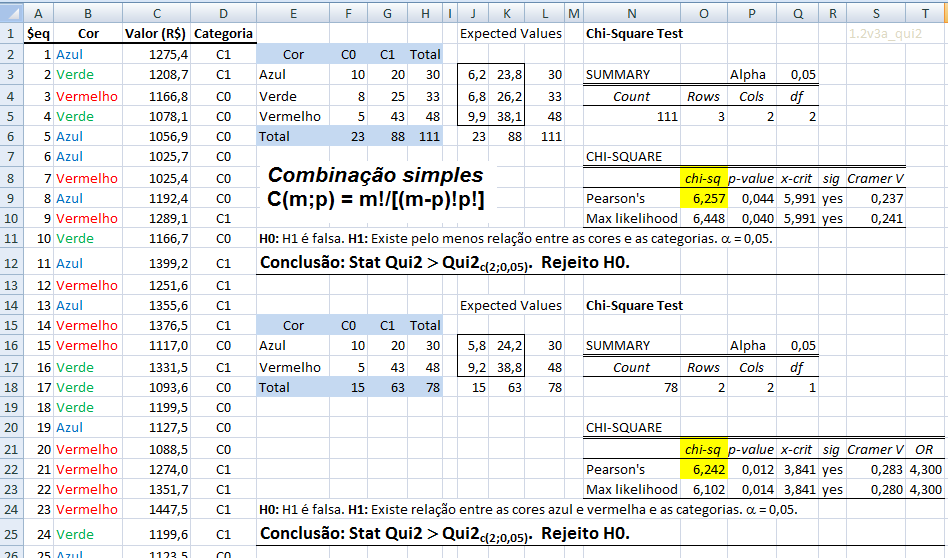{kind=link}
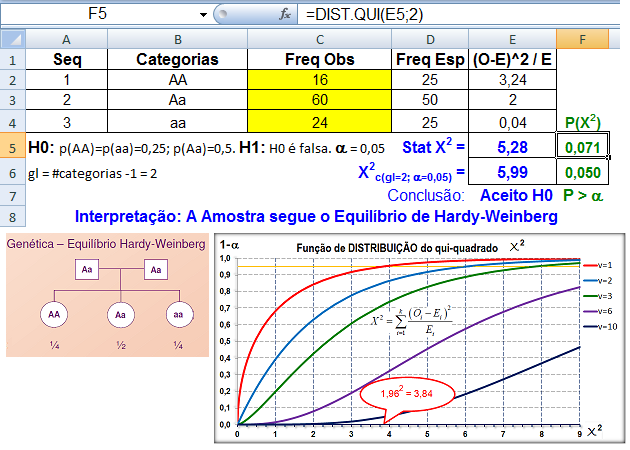{kind=link}
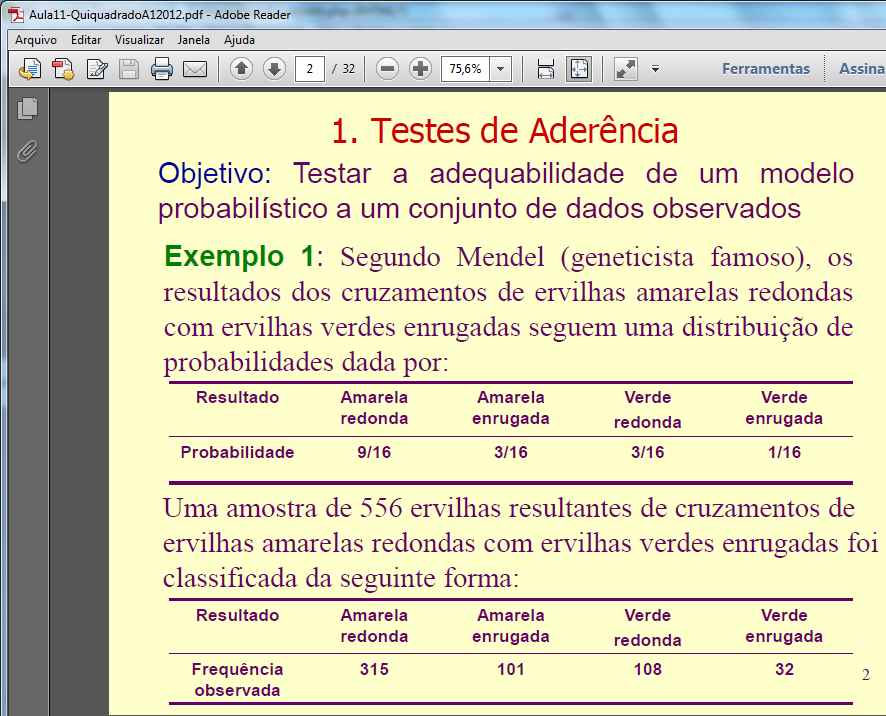{kind=link}
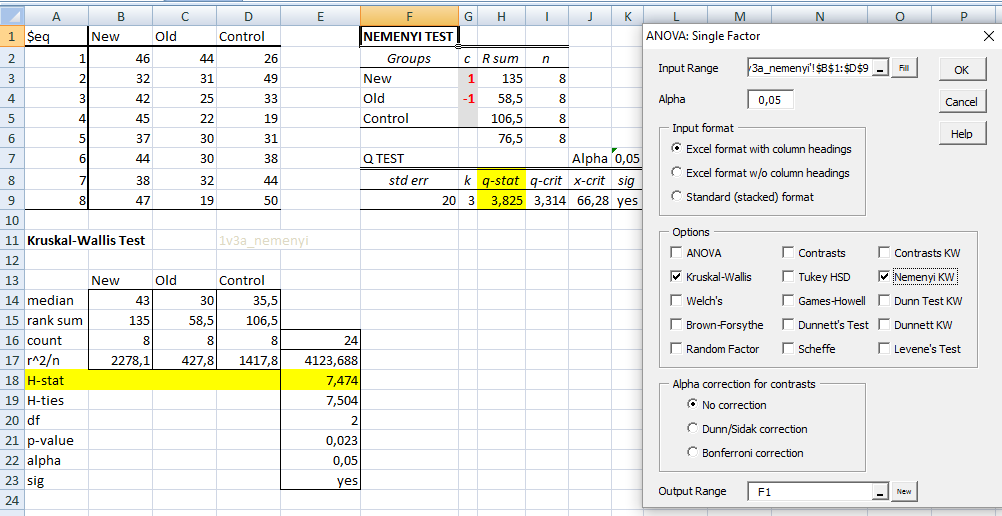{kind=link}
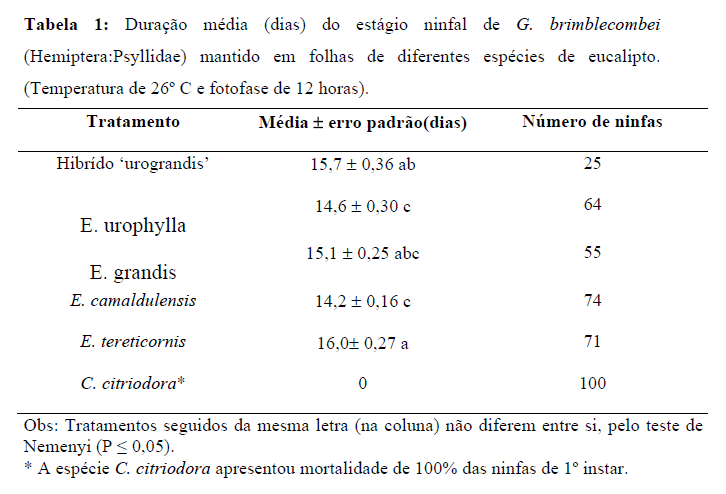{kind=link}
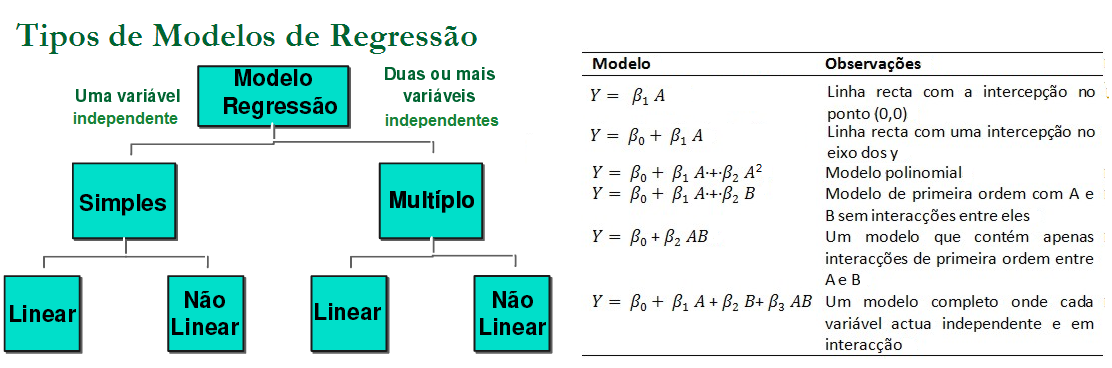{kind=link}
{kind=link}
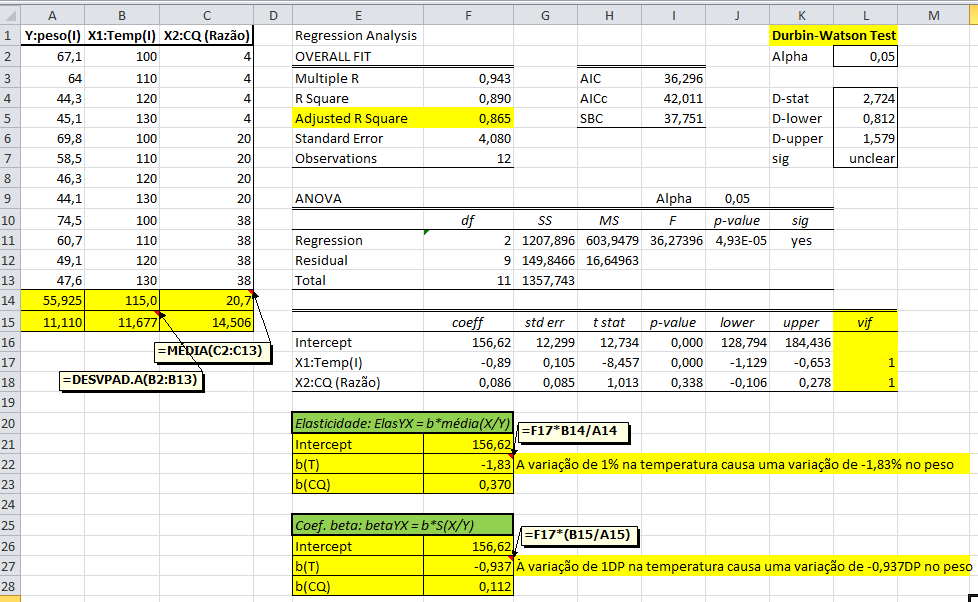{kind=link}
{kind=link}
{kind=link}
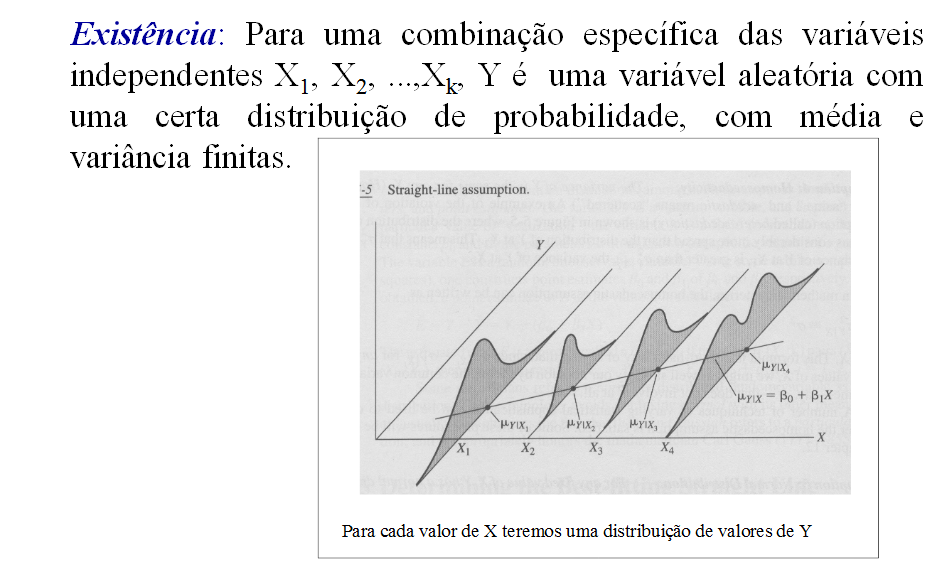{kind=link}
{kind=link}
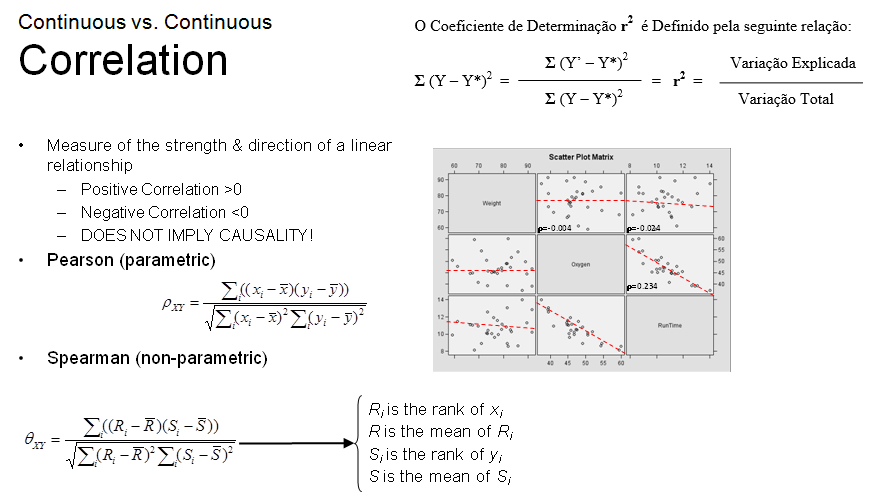{kind=link}
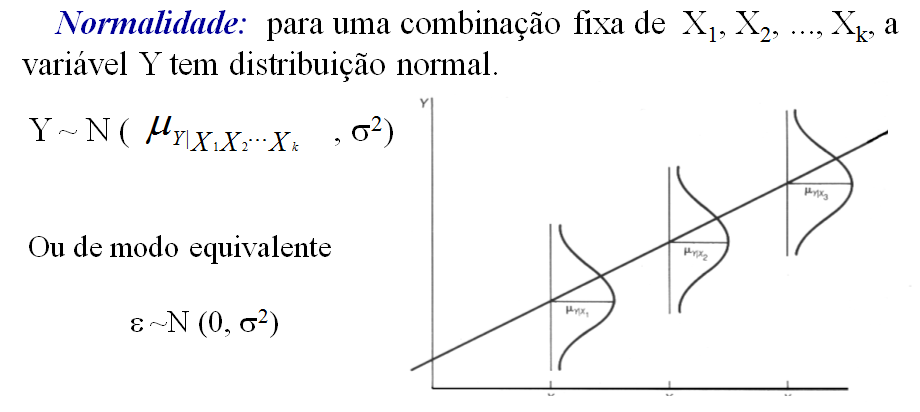{kind=link}
{kind=link}
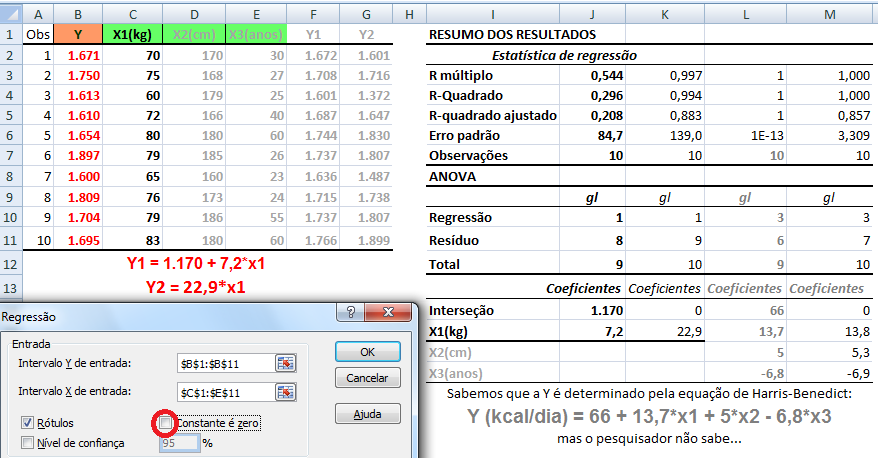{kind=link}
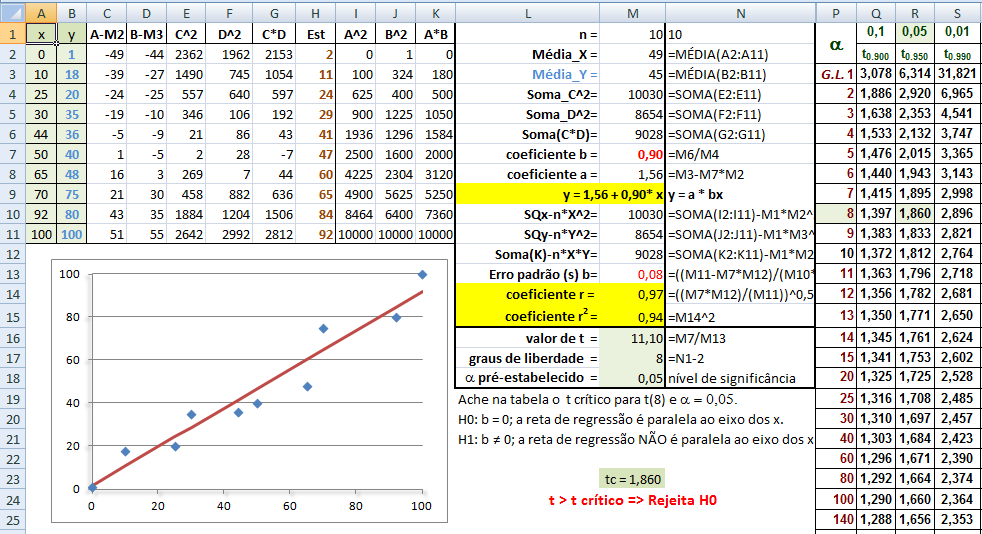{kind=link}
{kind=link}
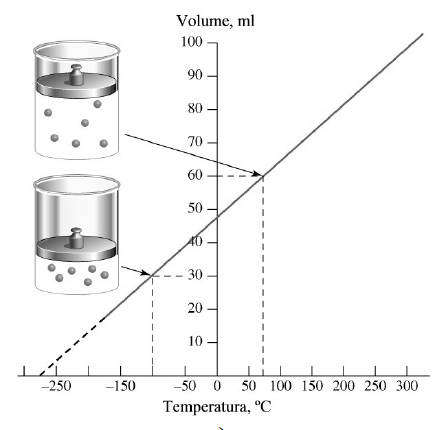{kind=link}
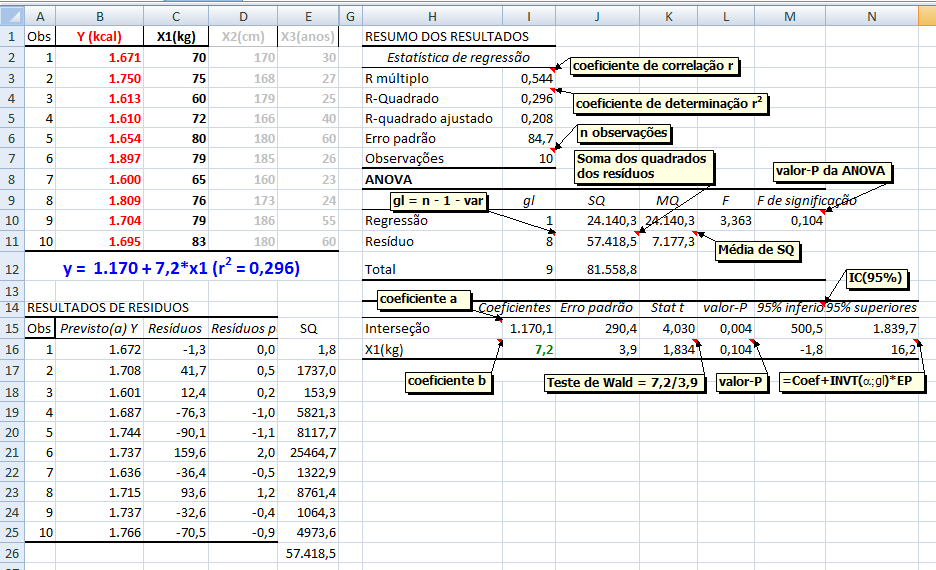{kind=link}
{kind=link}
{kind=link}
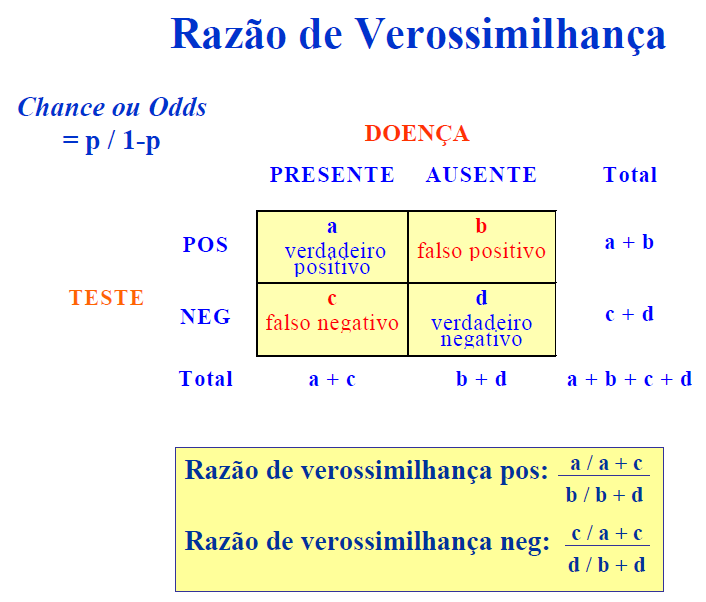{kind=link}
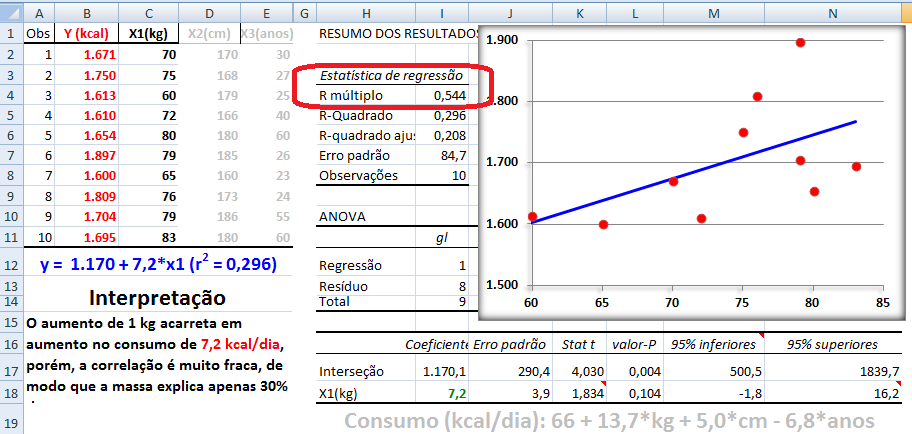{kind=link}
{kind=link}
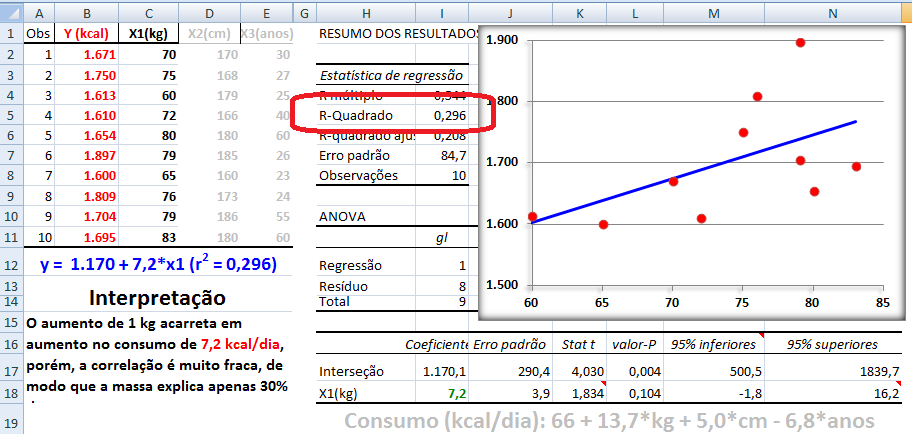{kind=link}
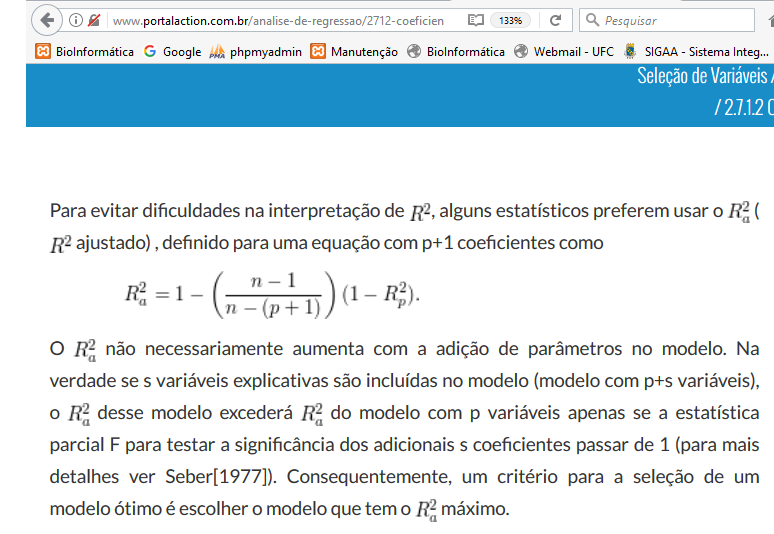{kind=link}
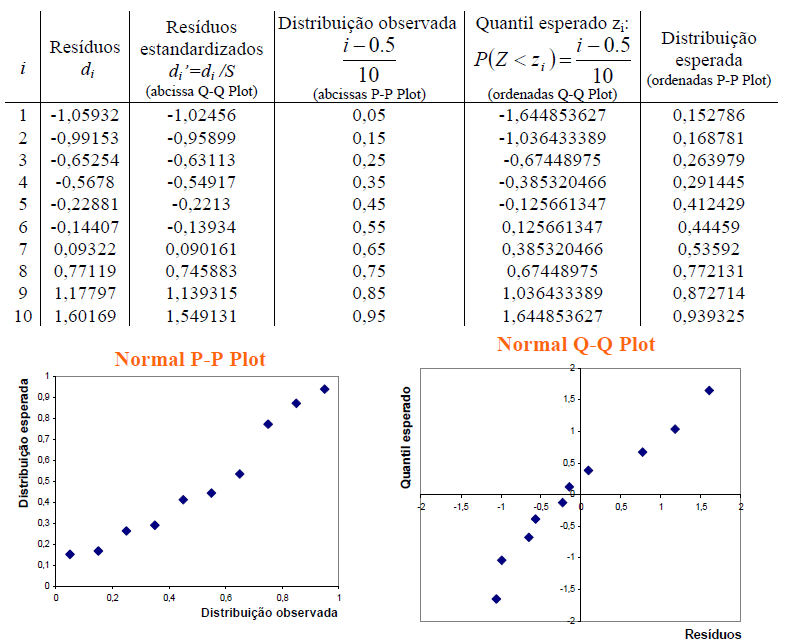{kind=link}
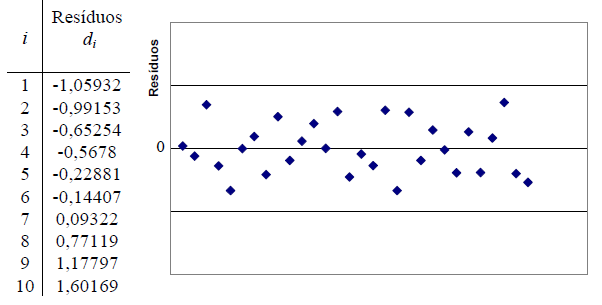{kind=link}
{kind=link}
{kind=link}
![Regressão linear simples com BC[95%]](./info/linear_bc.png){kind=link}
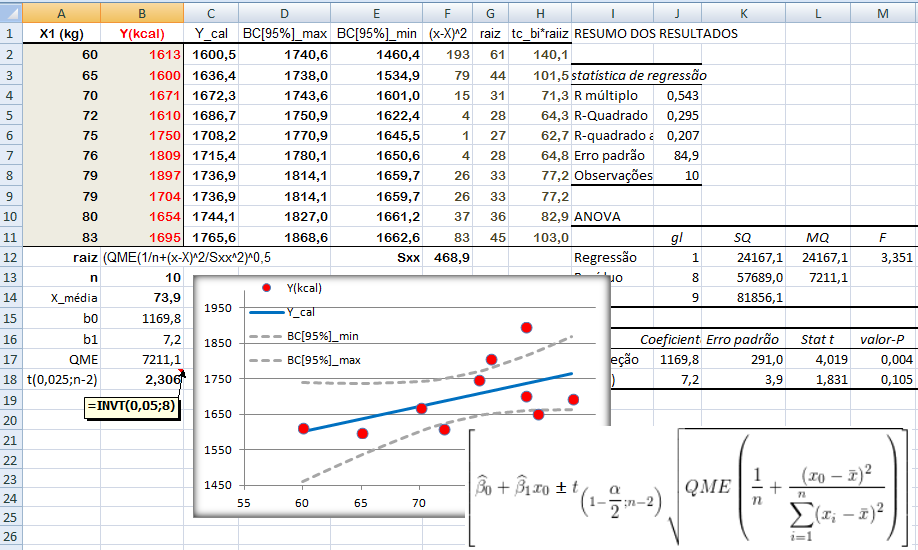{kind=link}
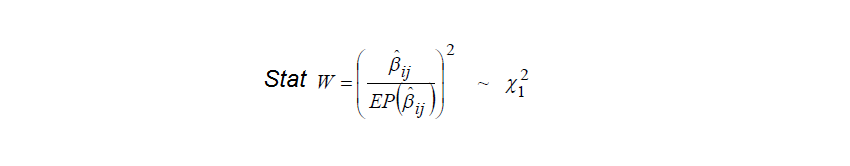{kind=link}
{kind=link}
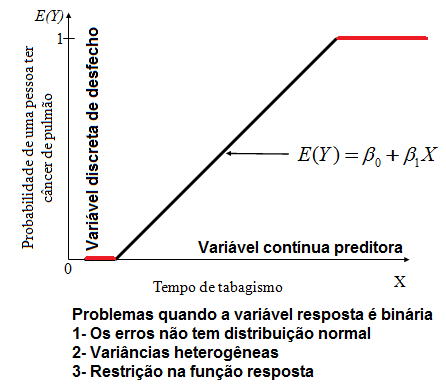{kind=link}
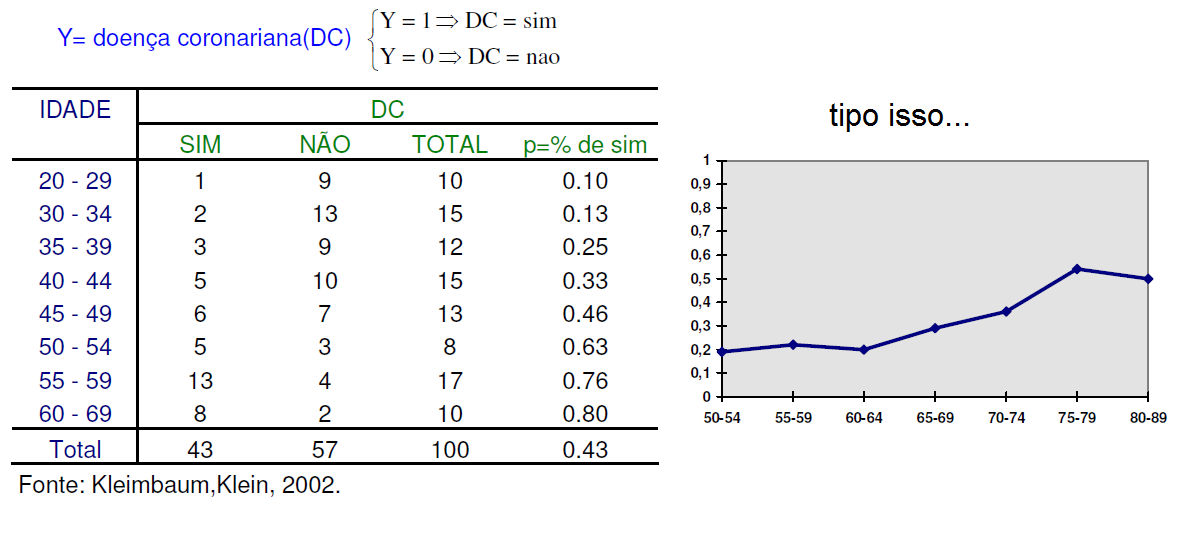{kind=link}
{kind=link}
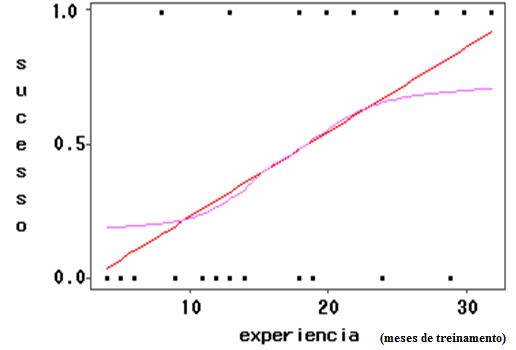{kind=link}
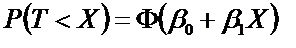{kind=link}
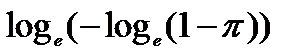{kind=link}
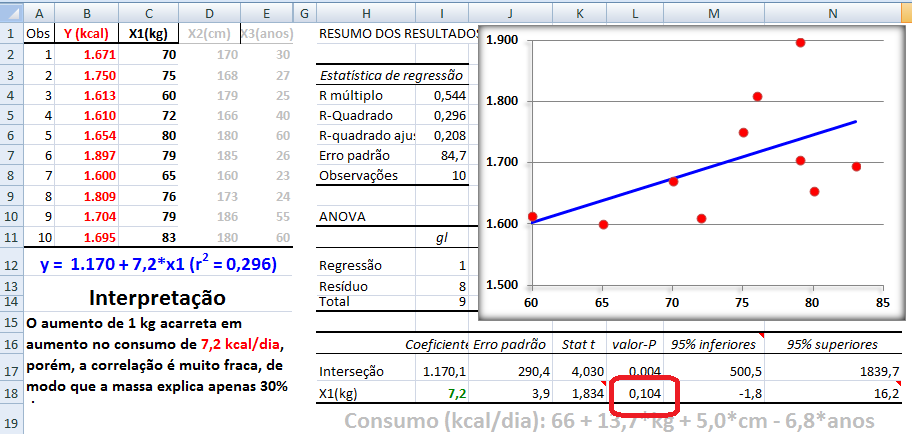{kind=link}
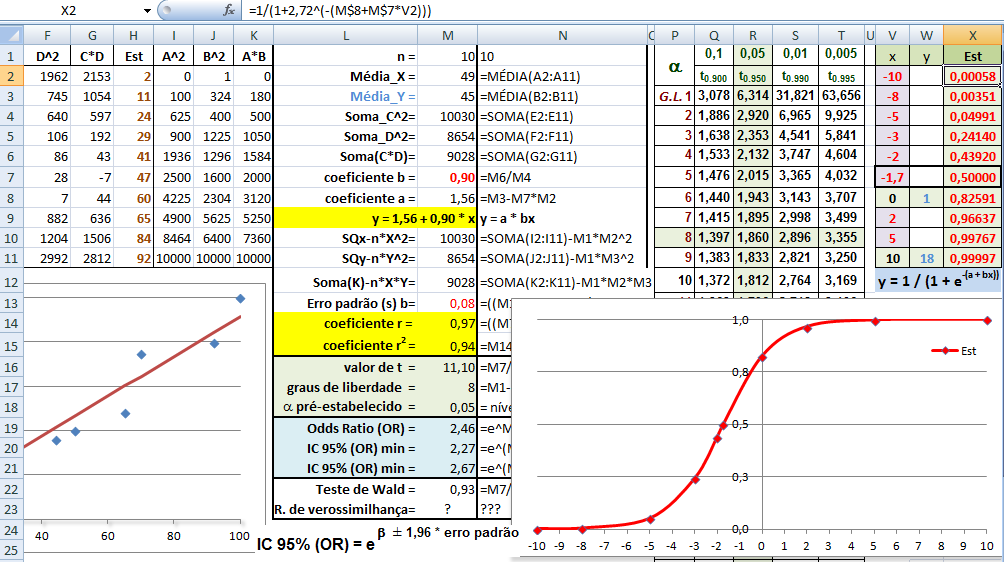{kind=link}
{kind=link}
{kind=link}
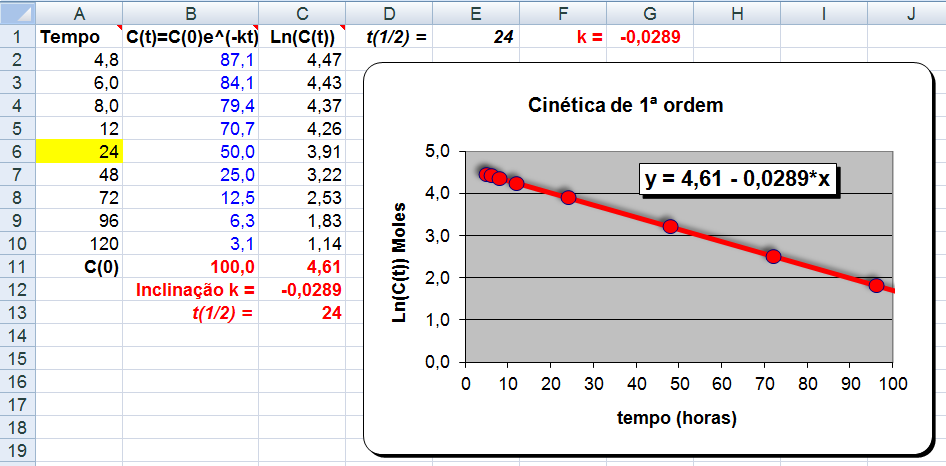{kind=link}
{kind=link}
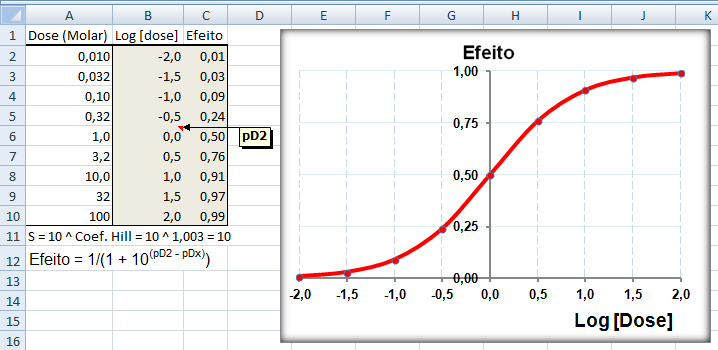{kind=link}
{kind=link}
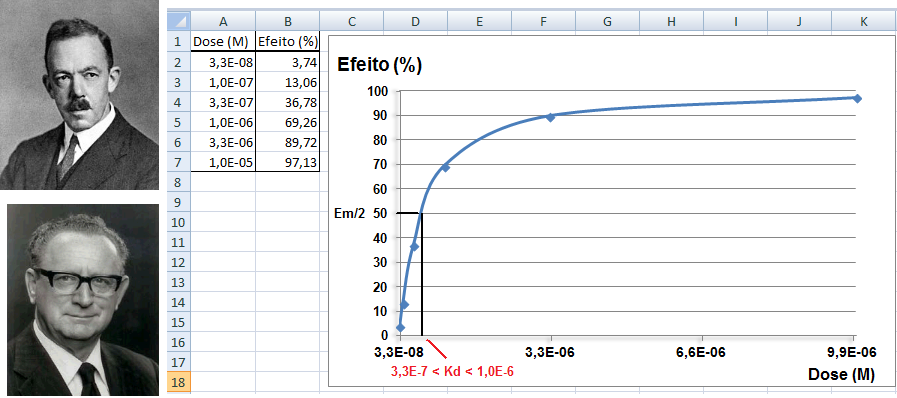{kind=link}
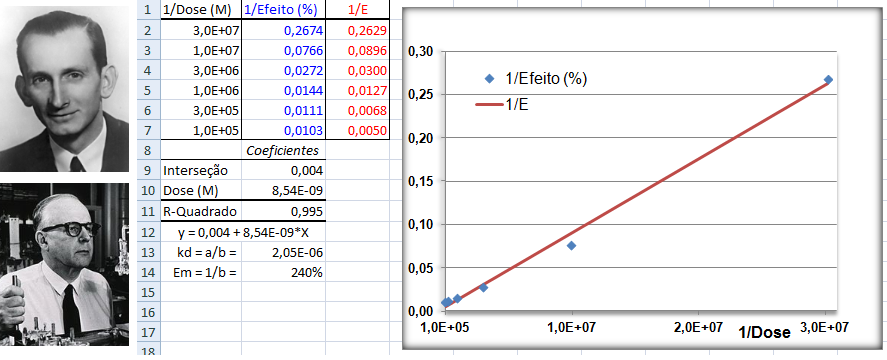{kind=link}
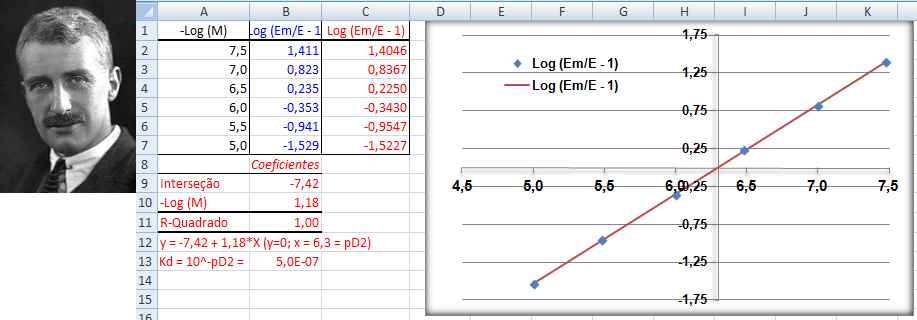{kind=link}
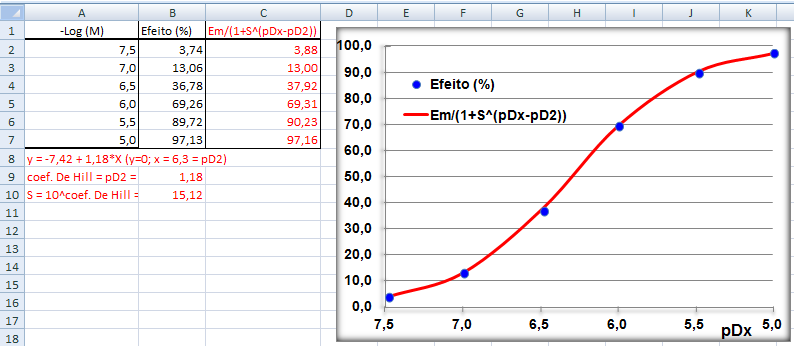{kind=link}
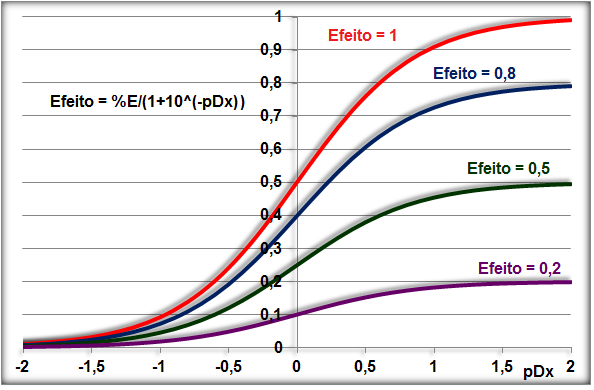{kind=link}
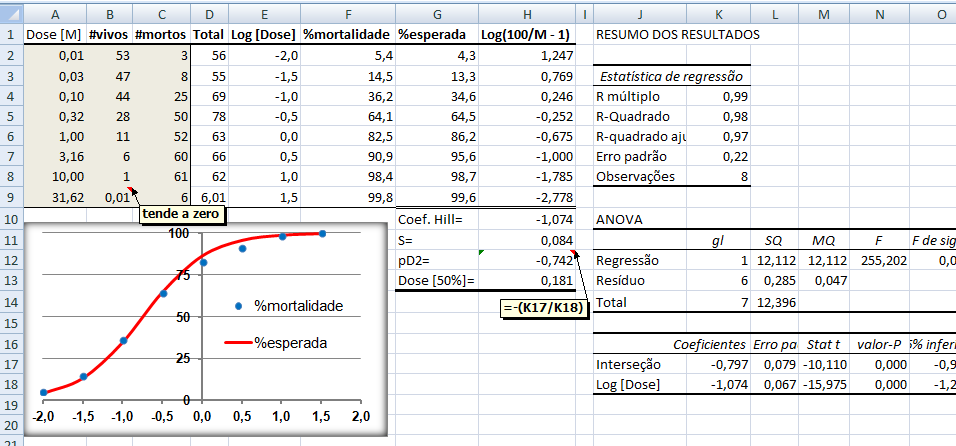{kind=link}
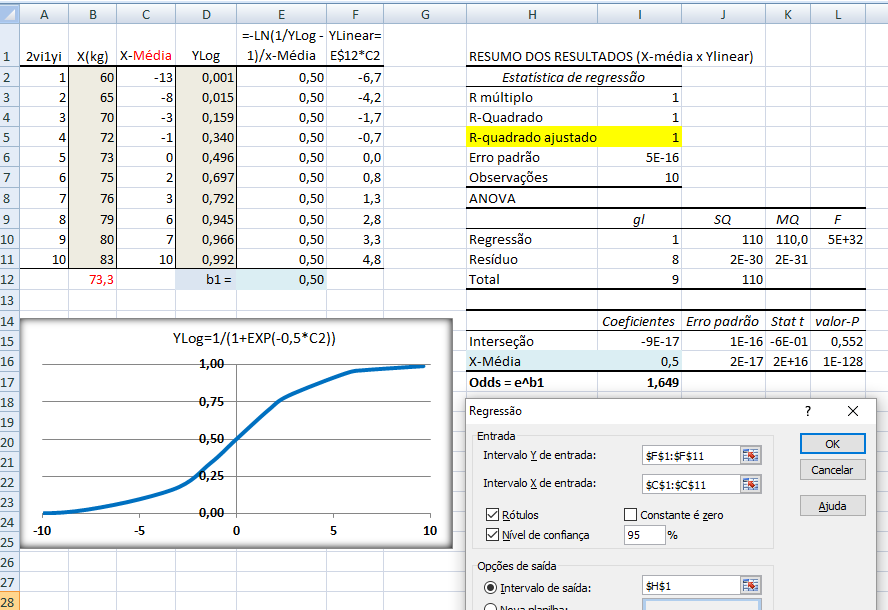{kind=link}
{kind=link}
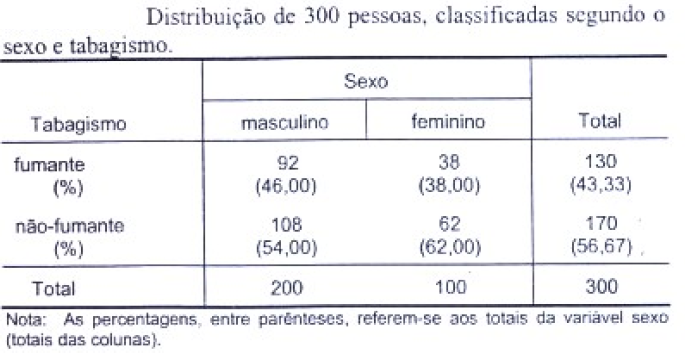{kind=link}
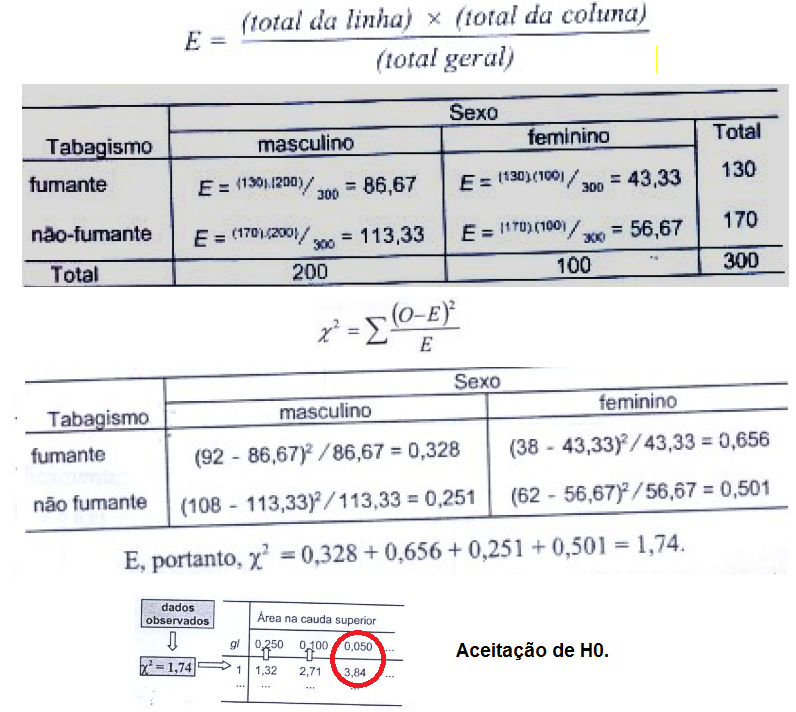{kind=link}
{kind=link}
{kind=link}
{kind=link}
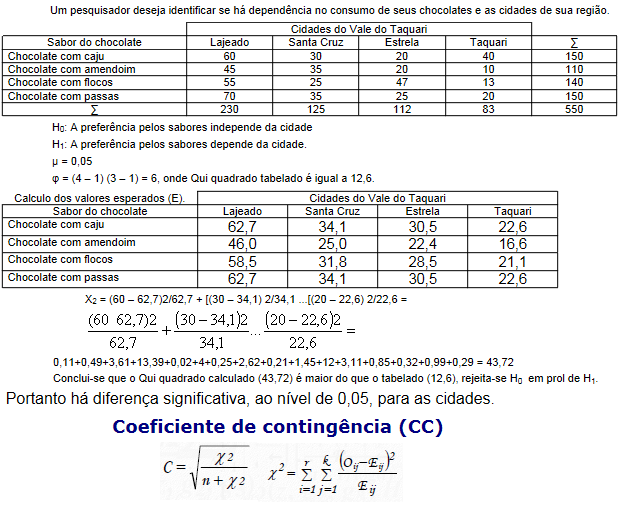{kind=link}
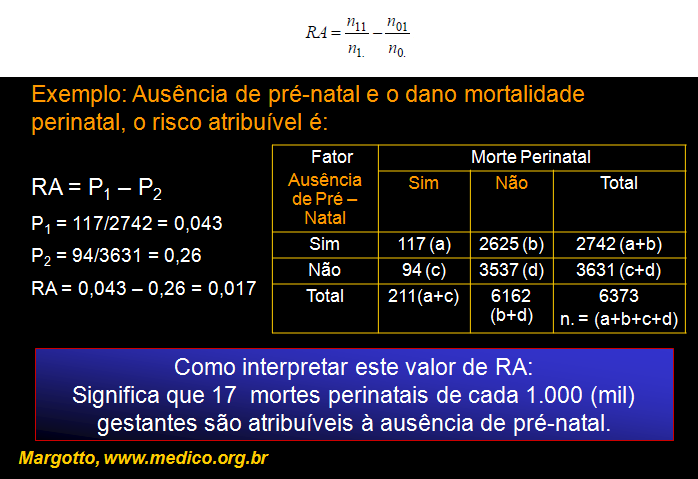{kind=link}
{kind=link}
{kind=link}
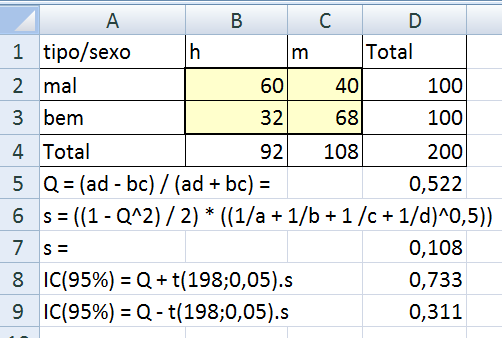{kind=link}
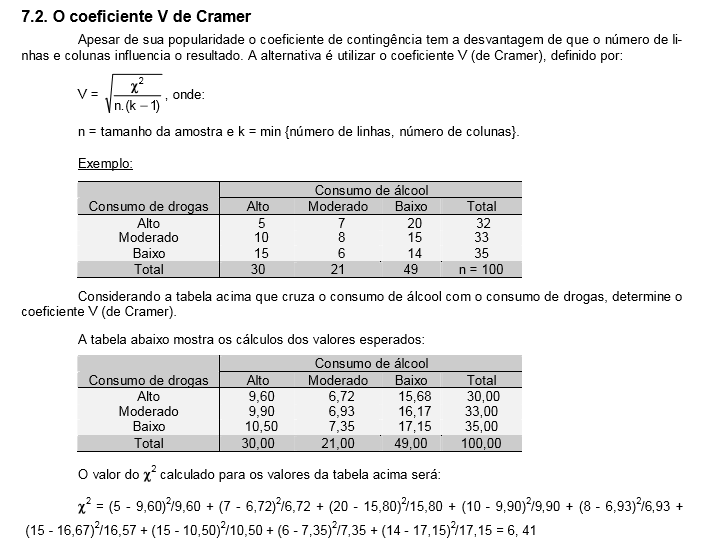{kind=link}
{kind=link}
{kind=link}
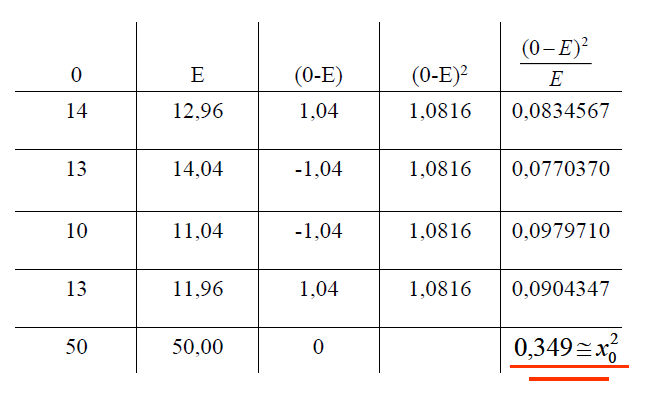{kind=link}
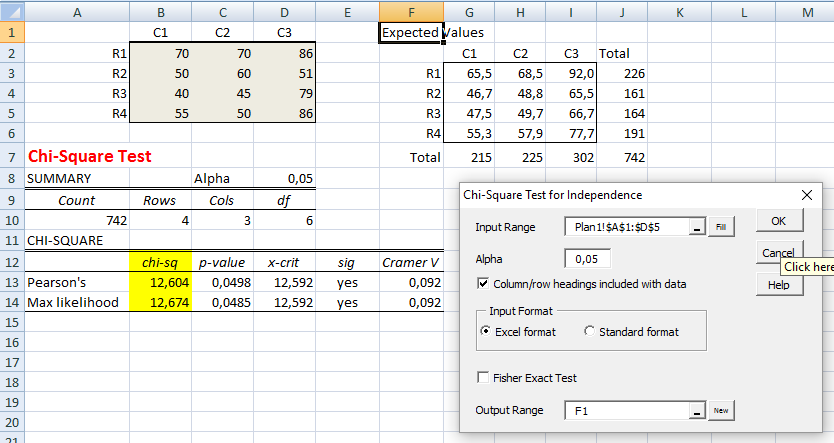{kind=link}
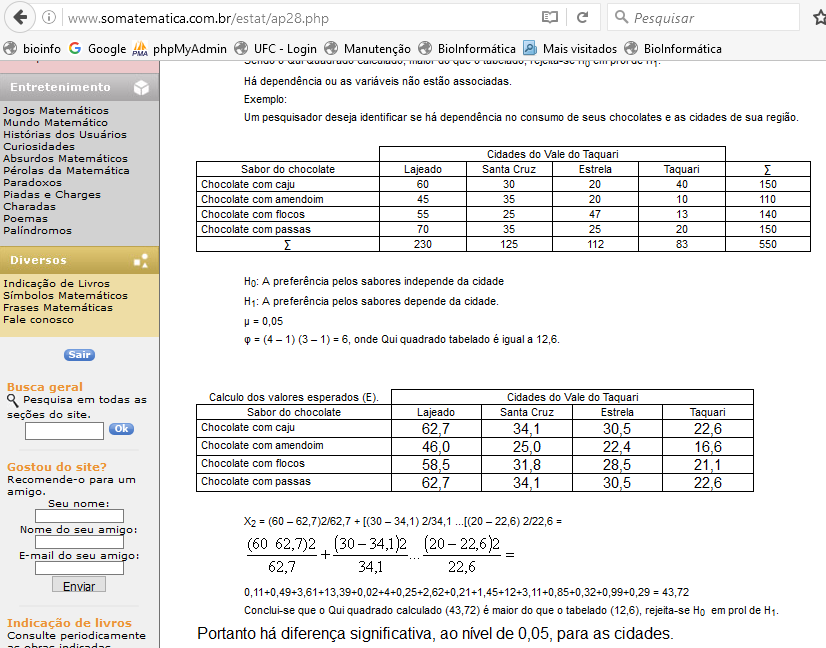{kind=link}
{kind=link}
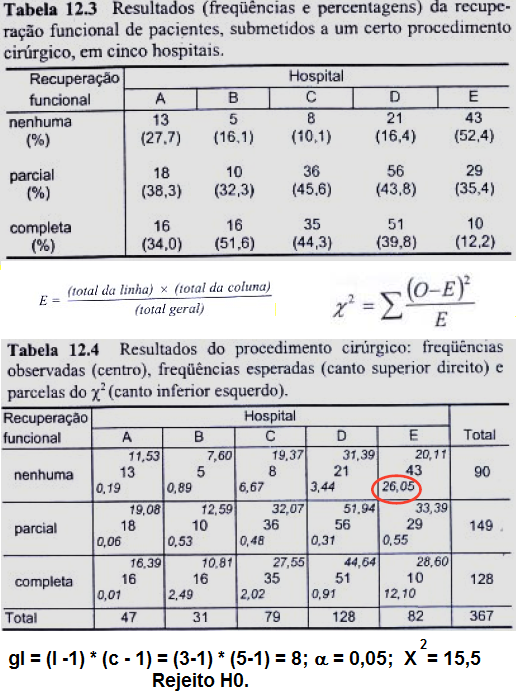{kind=link}
{kind=link}
{kind=link}
{kind=link}
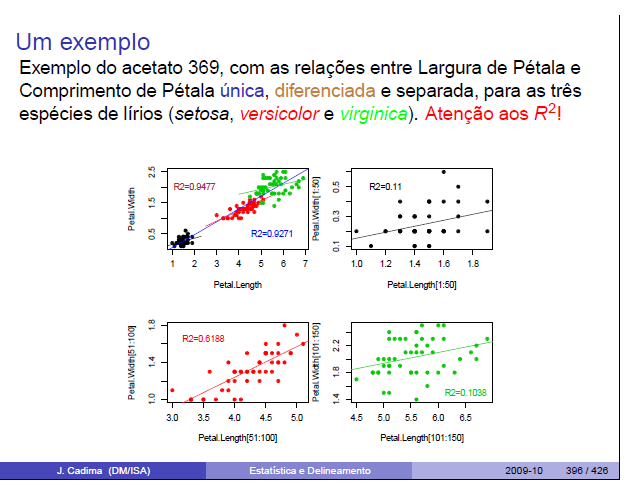{kind=link}
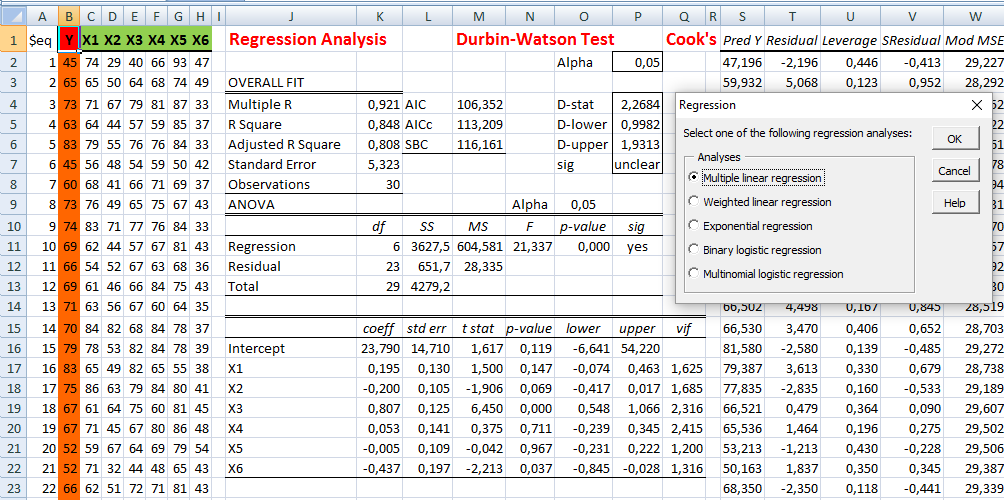{kind=link}
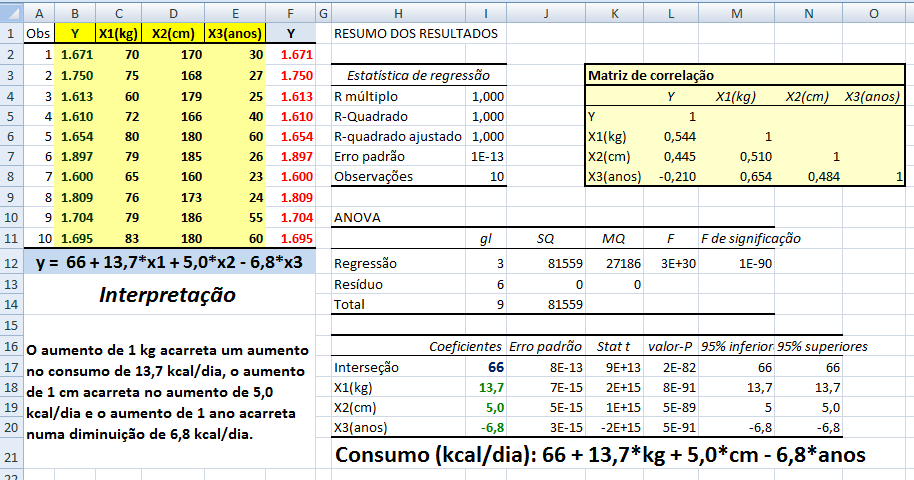{kind=link}
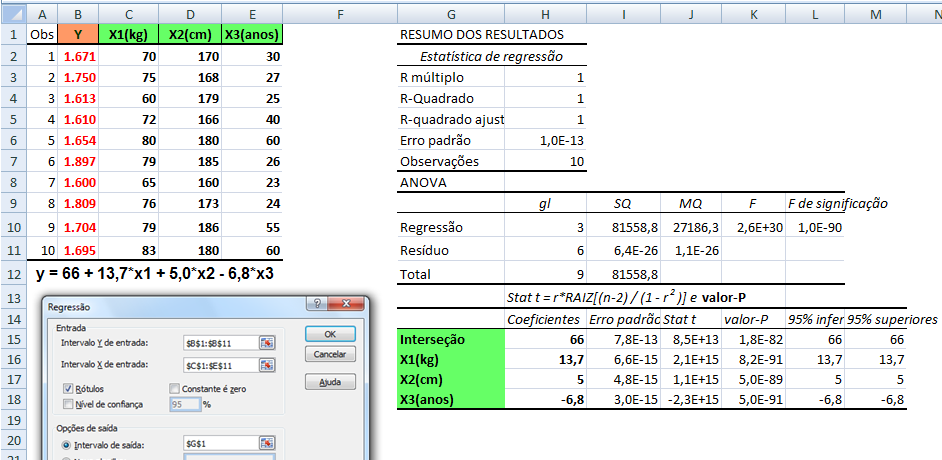{kind=link}
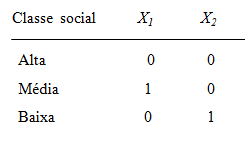{kind=link}
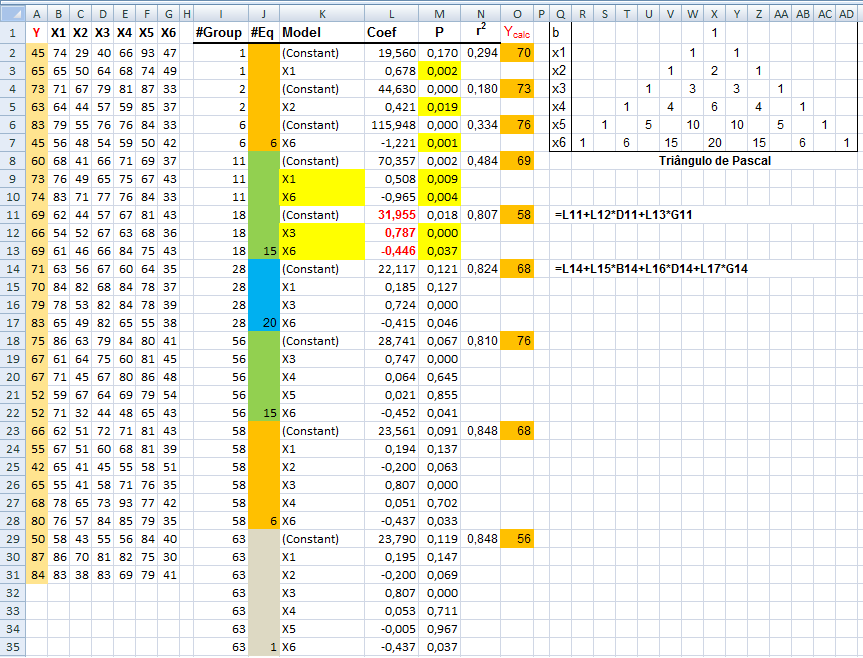{kind=link}
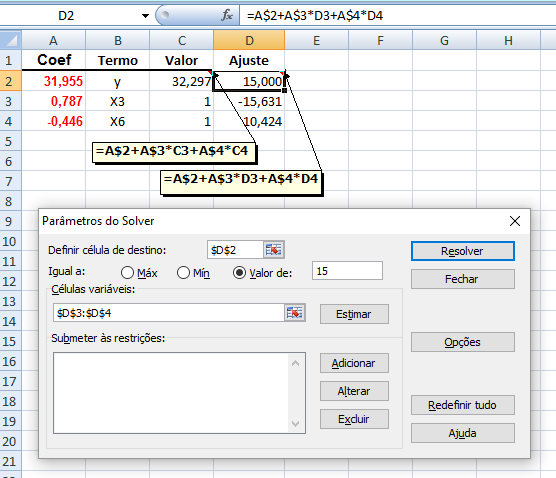{kind=link}
{kind=link}
{kind=link}
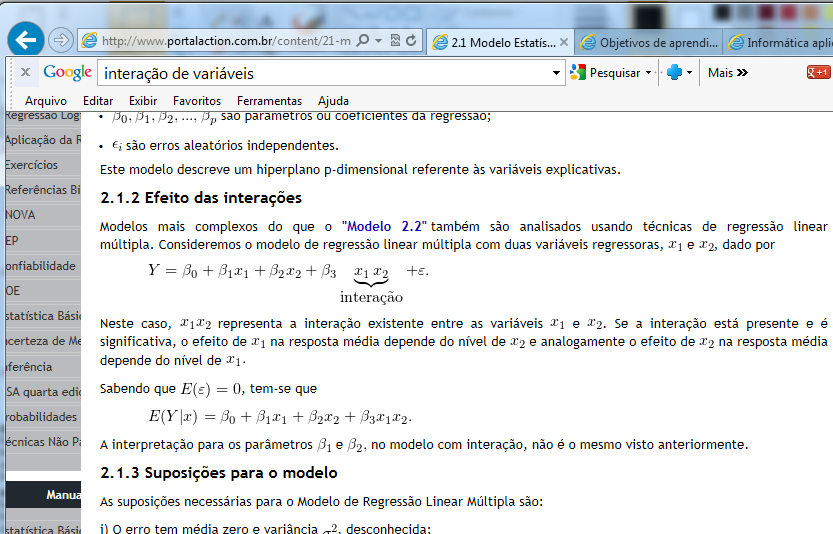{kind=link}
{kind=link}
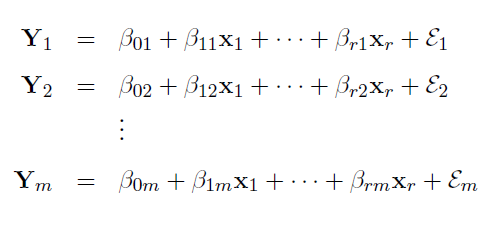{kind=link}
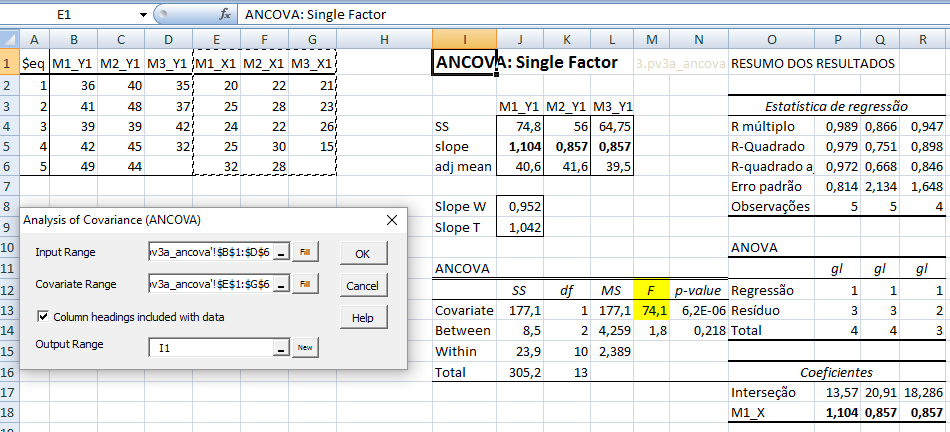{kind=link}
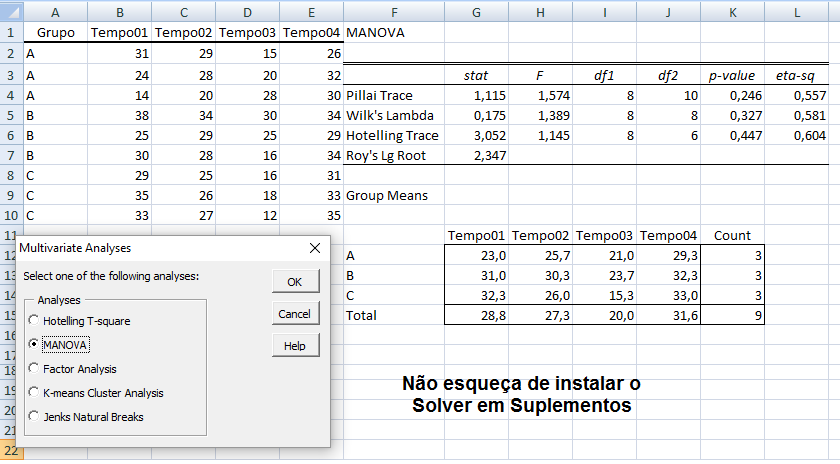{kind=link}
{kind=link}
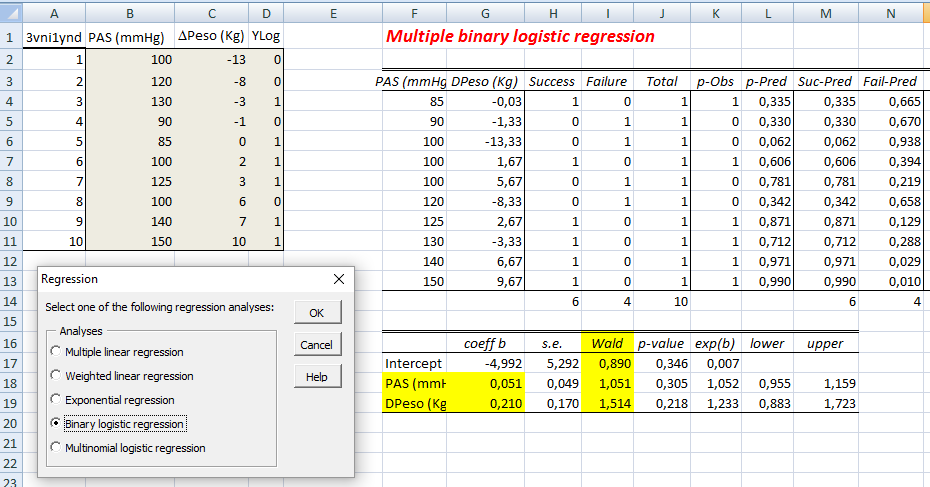{kind=link}
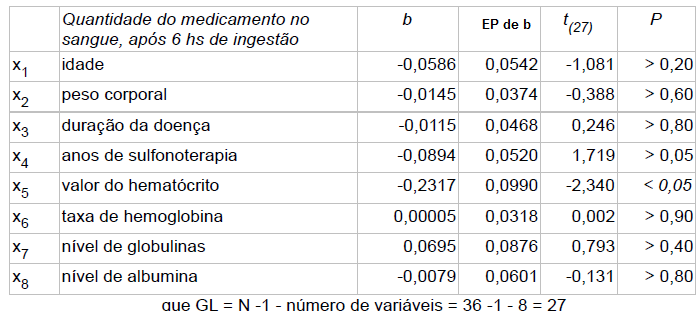{kind=link}
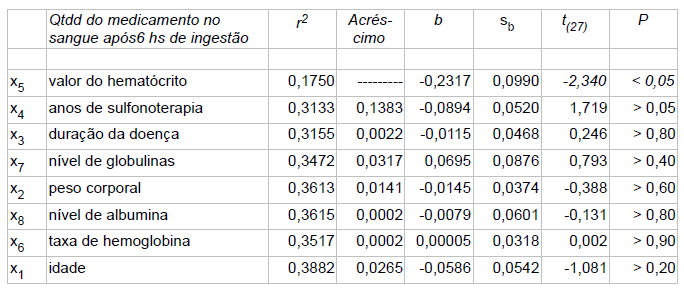{kind=link}
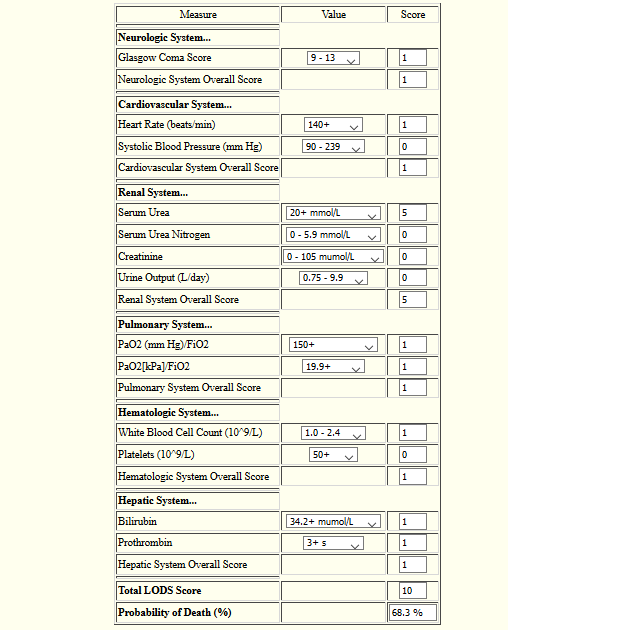{kind=link}
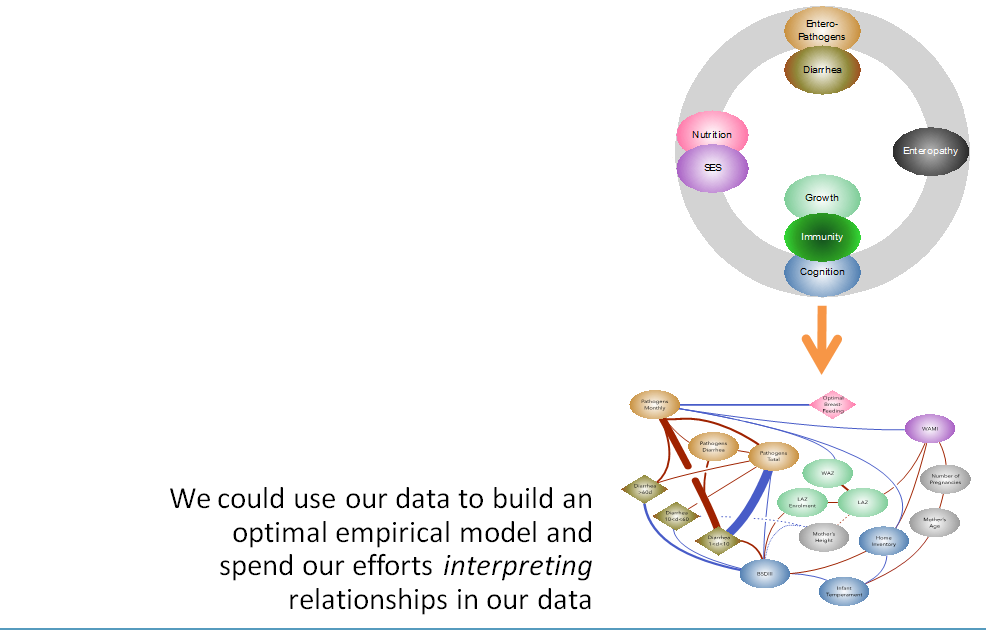{kind=link}
{kind=link}
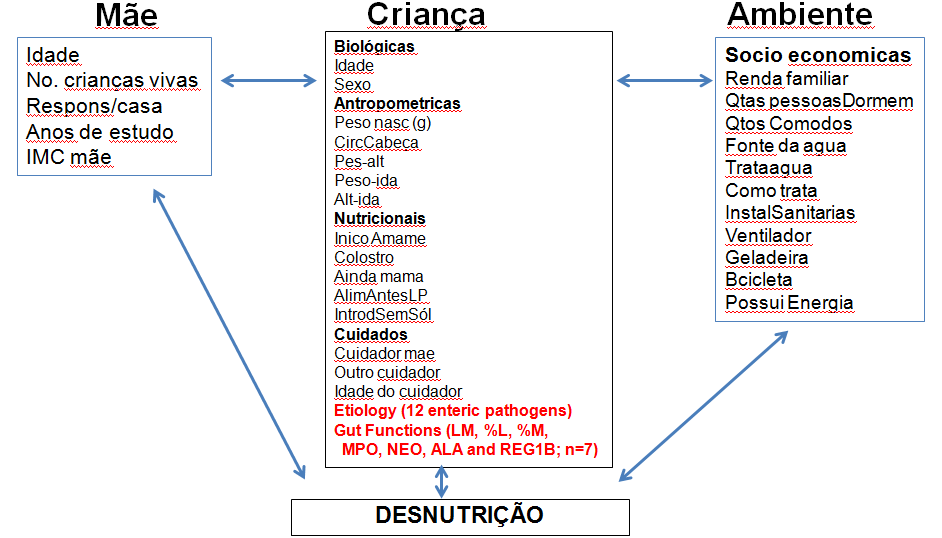{kind=link}
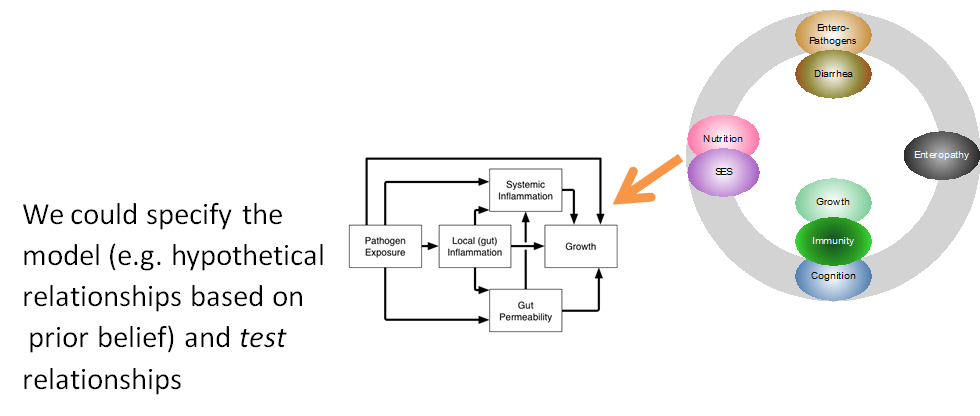{kind=link}
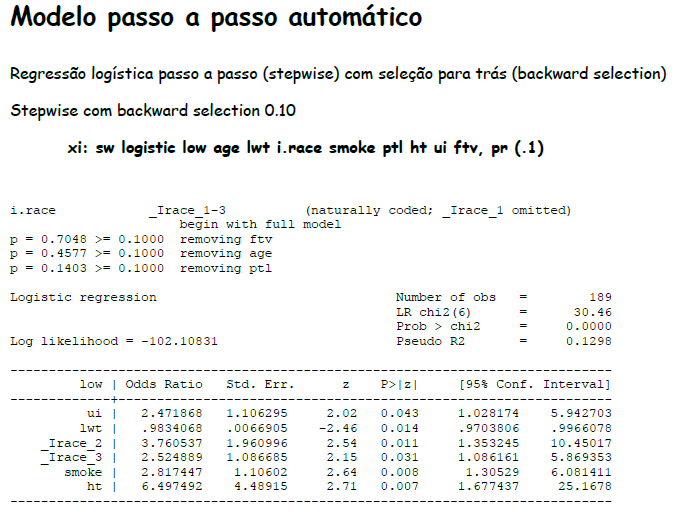{kind=link}
{kind=link}
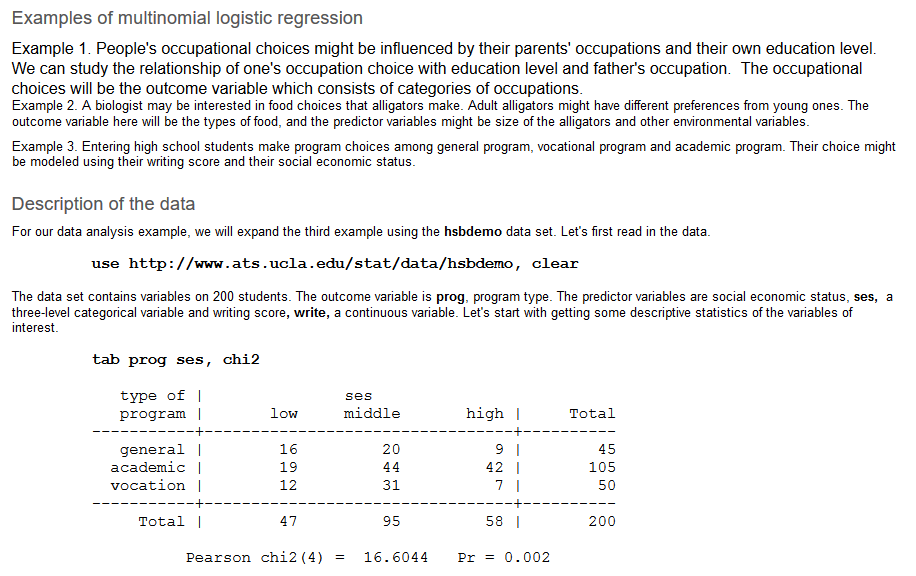{kind=link}
{kind=link}
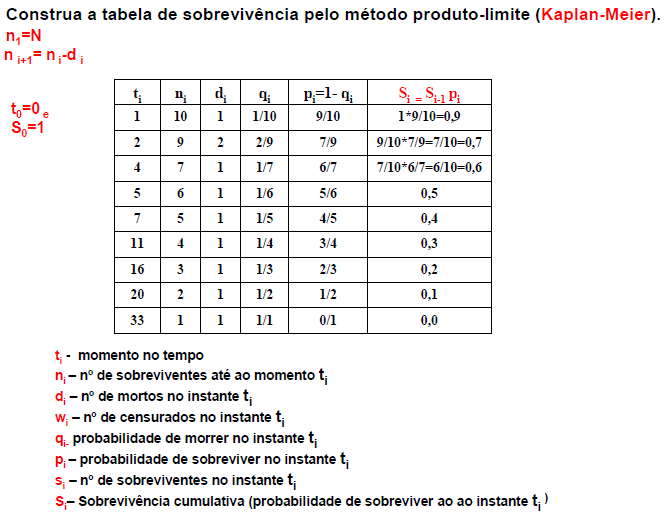{kind=link}
{kind=link}
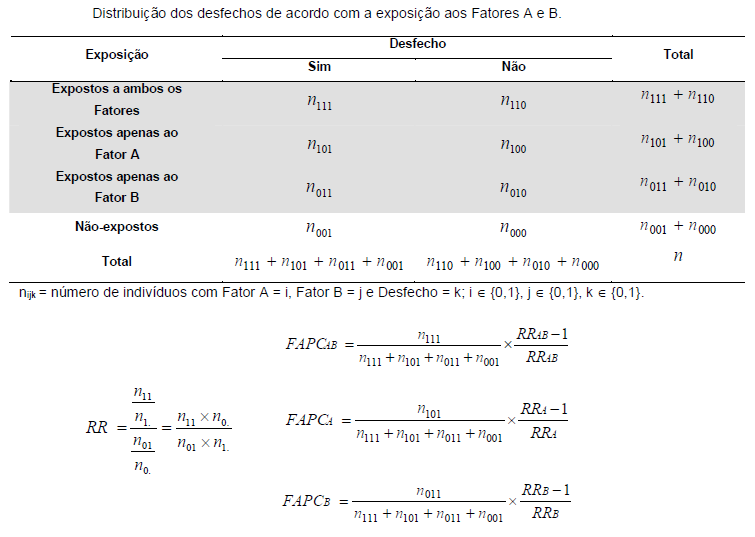{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
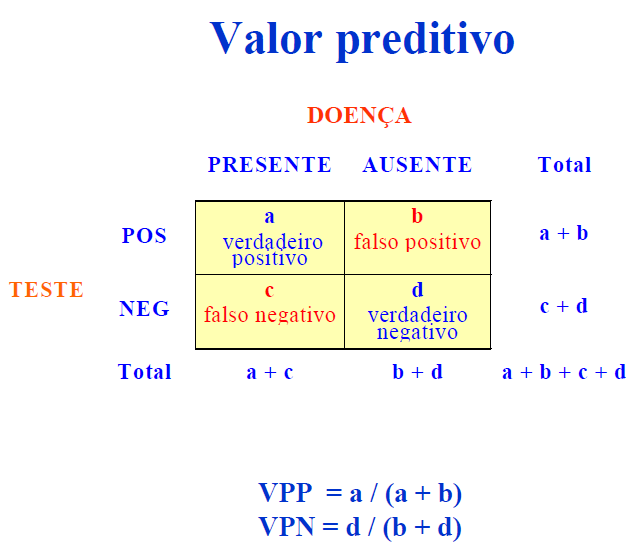{kind=link}
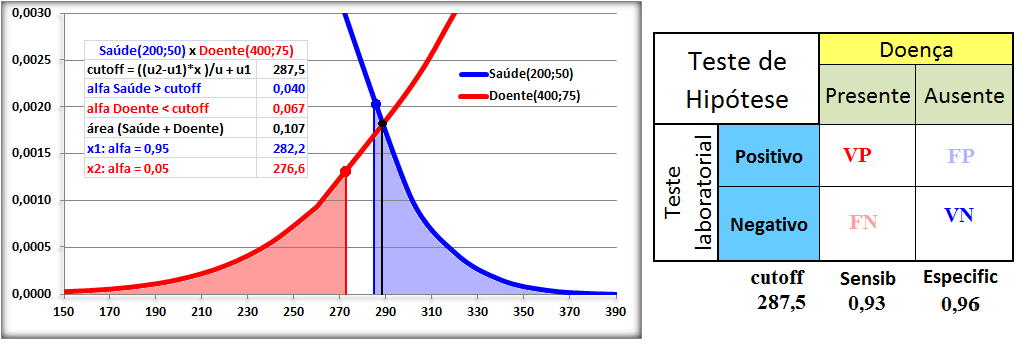{kind=link}
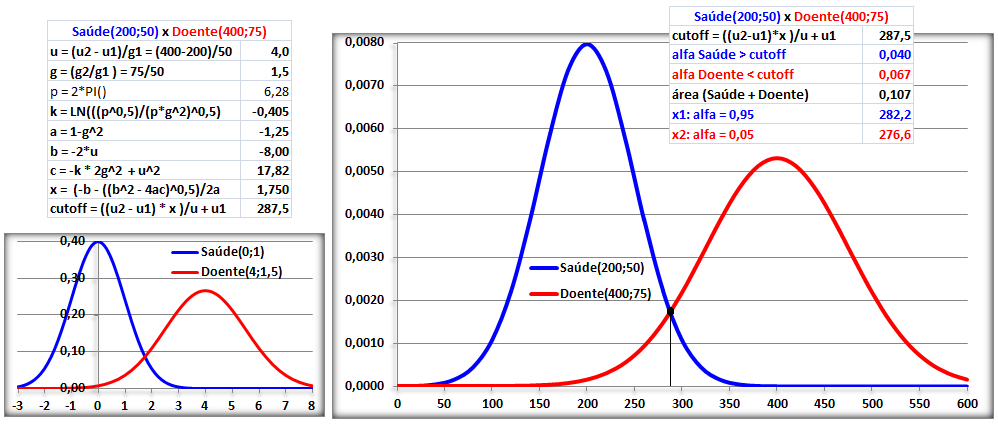{kind=link}
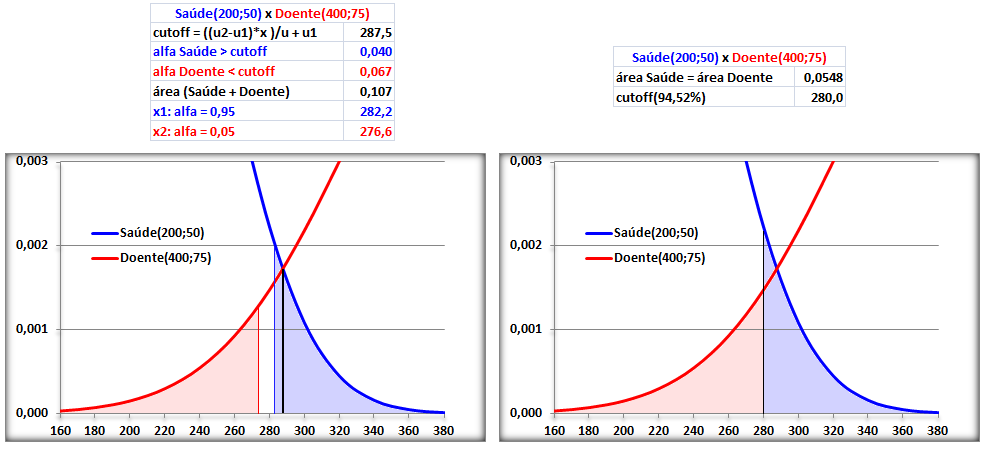{kind=link}
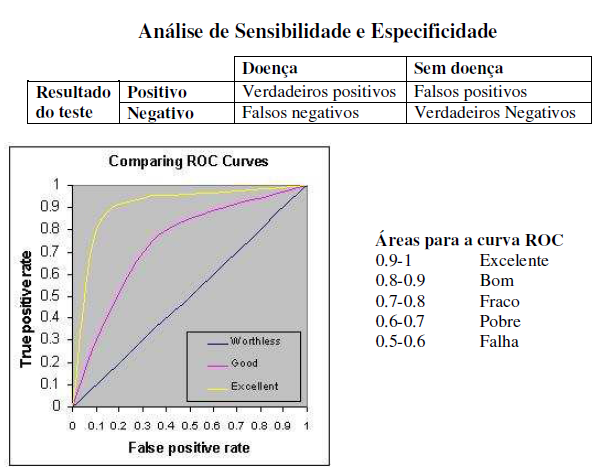{kind=link}
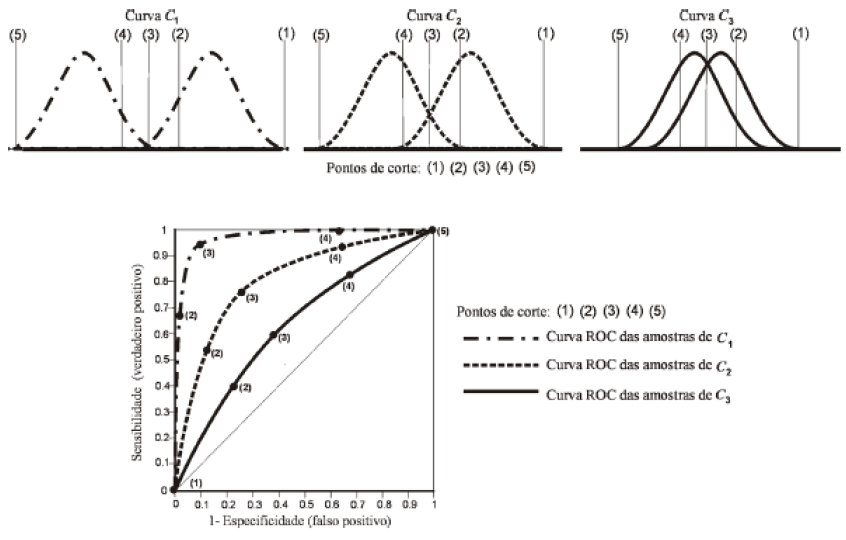{kind=link}
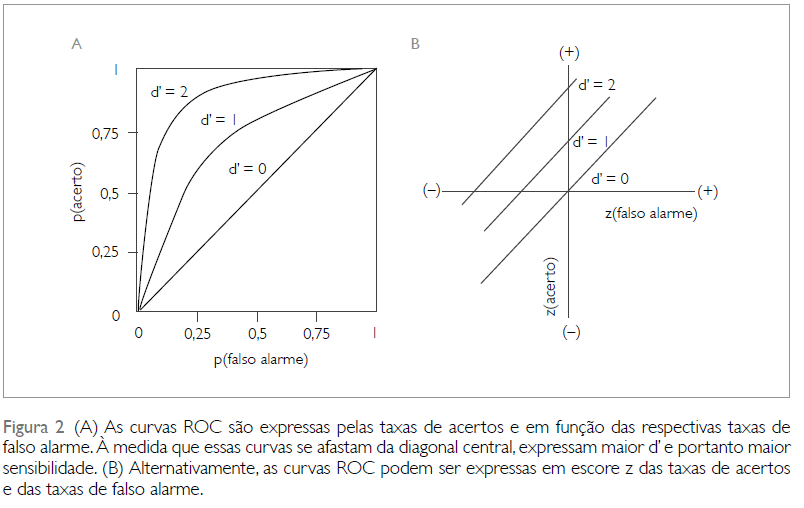{kind=link}
{kind=link}
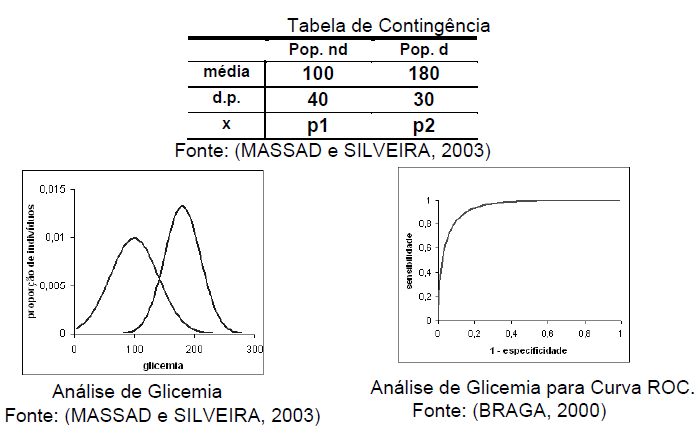{kind=link}
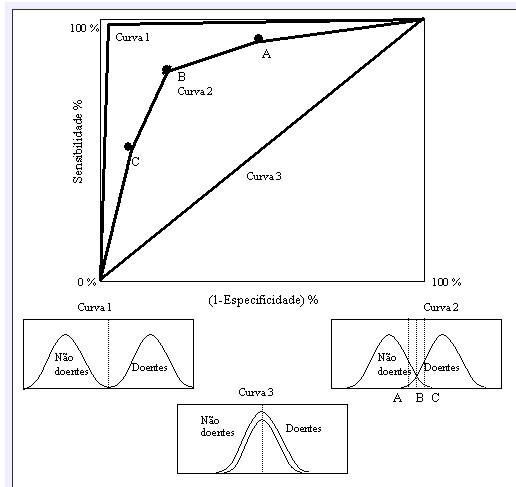{kind=link}
{kind=link}
{kind=link}
{kind=link}